本文主要是介绍【火山引擎数据传输工具 TOS import使用手册】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 背景
- 正文
- 下载软件包
- 安装 TOS import
- 部署分布式数据传输任务
- 启动分布式任务
背景
TOS import是火山引擎的TOS(对象存储)传输工具包,是从本地、S3或者其他云存储传输数据到TOS的常用工具;在使用过程中发现TOS import的文档不太全面,本文作为补充,方便大家上手,争取做到复制粘帖即可运行。
正文
本文的服务器系统均为linux。
下载软件包
wget https://tos-tools.tos-cn-beijing.volces.com/linux/tos-import_v1.0.3.linux_x86.tar.gz
安装 TOS import
解压安装,比如这里直接安装在root下;
tar -zxvf tos-import_v1.0.3.linux_x86.tar.gz -C /root/
在/root/tos-import 目录下有这些内容,后续会用到;
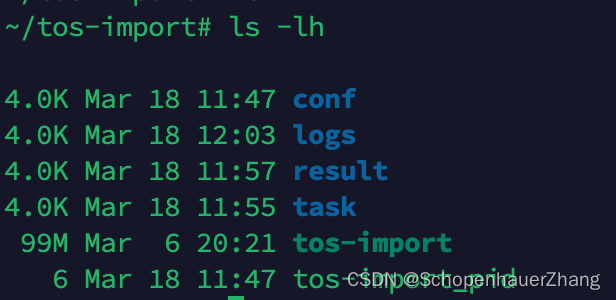
简单解释下,
- conf是配置文件的存储目录;
- logs是日志目录;
- task是迁移任务的管理和配置;
- tos-import是二进制文件;
部署分布式数据传输任务
加入集群中有3个节点(IP分别为:1,2,3),以下列出必要的配置;
通信、节点配置
# conf/server.yaml
work_dir: "/root/tos-import/"
work_nodes:- "1"# 默认第一个节点为管理节点,由管理节点下发配置给worker节点,并且将执行的结果收集起来展示- "2"- "3"
ssh_user: "root" # 节点间做root免密
ssh_password: ""
ssh_keyfile: "/root/.ssh/id_rsa" #
ssh_port: "22" # ssh 的默认端口
mgr_port: "31" # 管理节点的端口
server_port: "32" # 节点间通信端口
log_level: "Info"
task 的配置
# task/task-local.template.yaml
# 任务名称
task_name: "test"
#local:本地文件。
#url:url列表文件。
#s3:支持s3协议对象存储文件
src_type: "local"
# 需要迁移的目录/文件
src_prefix: "/root/tos-import_v1.0.3.linux_x86.tar.gz"
dest_type: "tos"
dest_ak:"" # access key
dest_sk:"" # secret key
dest_region:"" #tos 的region
dest_endpoint:"" #tos endpoint域名
dest_bucket:"" #桶名称
#迁移任务带宽流控,单位:KB/s,默认为100MB/s。最好设置,给其他业务或者服务留出带宽,防止带宽打满
task_bandwidth: 102400
启动分布式任务
注意配置文件;
./tos-import create --conf task/task-local.template.yaml
Create migrate task 'test' success, source type: local
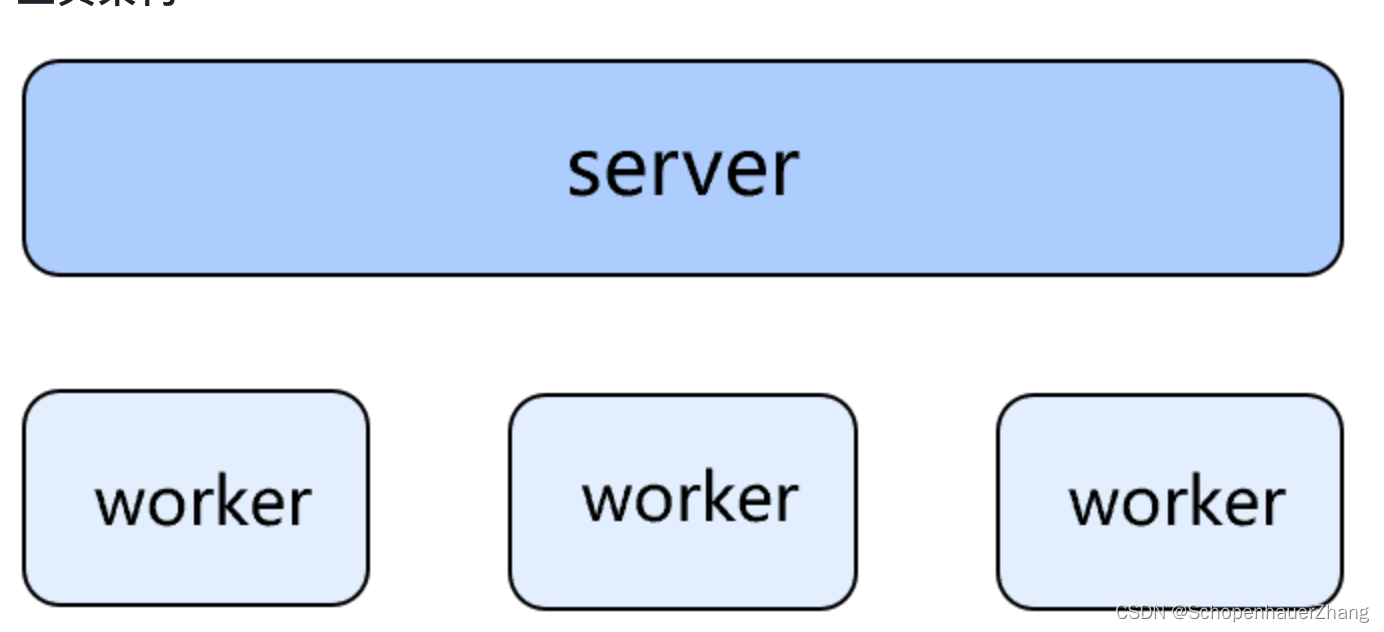
server:负责响应命令、管理任务、列举与分发功能的核心节点;worker:承载负责具体迁移的 executor 进程的节点。
查看迁移任务列表
# 查看迁移任务的列表
./tos-import list
ID TaskName TaskStatus CreateTime Objects-Transferred/Total Bytes-Transferred/Total
1 test Transferring 2024-03-18 11:56:50 0/2 43109799/86219599 这篇关于【火山引擎数据传输工具 TOS import使用手册】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







