本文主要是介绍YOLOv8:Roboflow公开数据集训练模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Roboflow公开数据集
Roboflow是一个提供计算机视觉数据集管理和处理工具的平台。虽然Roboflow本身并不创建或策划公开数据集,但它提供了一系列功能,帮助用户组织、预处理、增强和导出计算机视觉数据集。
官方网站:https://universe.roboflow.com/
然而,有几个常用的公开数据集可供计算机视觉使用,可以在Roboflow或其他计算机视觉平台上访问和使用这些数据集。以下是一些常用的计算机视觉公开数据集:
-
COCO(Common Objects in Context):COCO是一个大规模数据集,其中包含带有对象注释的图像,可用于对象检测、分割和字幕生成等任务。
-
ImageNet:ImageNet是一个包含数百万标记图像的数据集,涵盖了数千个类别。它被广泛用于图像分类和深度学习研究。
-
Open Images:Open Images是一个包含数百万图像及其对象检测、分割和视觉关系注释的数据集。
-
Pascal VOC:Pascal VOC数据集是一个包含图像及其对象检测、分割和分类注释的集合。它常用于计算机视觉算法的基准测试。
-
Cityscapes:Cityscapes是一个专注于城市场景的数据集,包含高质量图像以及像素级别的语义分割和实例分割注释。
-
LFW(Labeled Faces in the Wild):LFW是一个包含从网络收集的人脸图像的数据集。它常用于人脸识别任务。
部署安装YOLOv8环境
Github官方网址:https://github.com/ultralytics/ultralytics
安装和部署YOLOv8:http://t.csdnimg.cn/iGwXY
下载Roboflow公开数据集
打开官方网站:https://universe.roboflow.com/
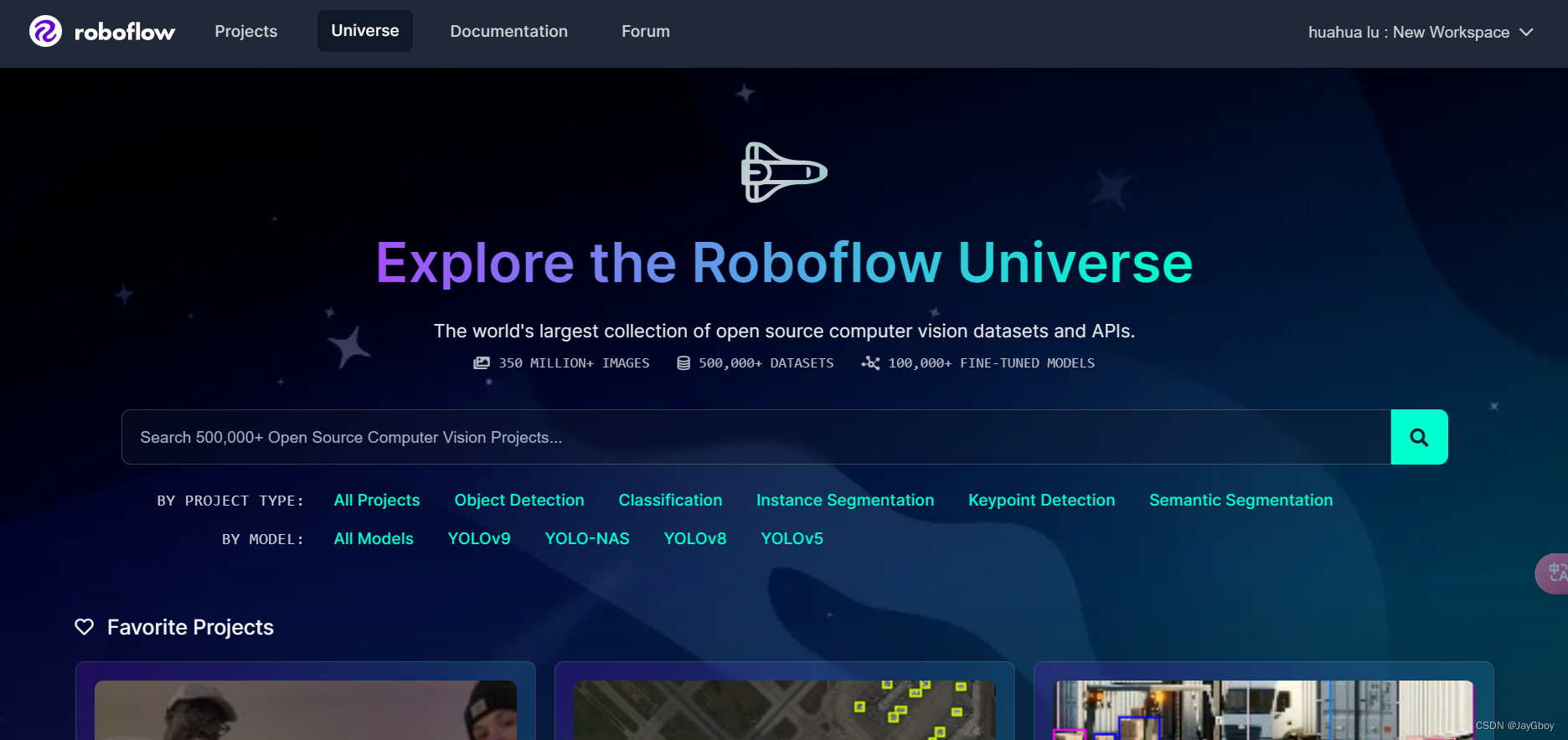
选择自己需要的数据集:
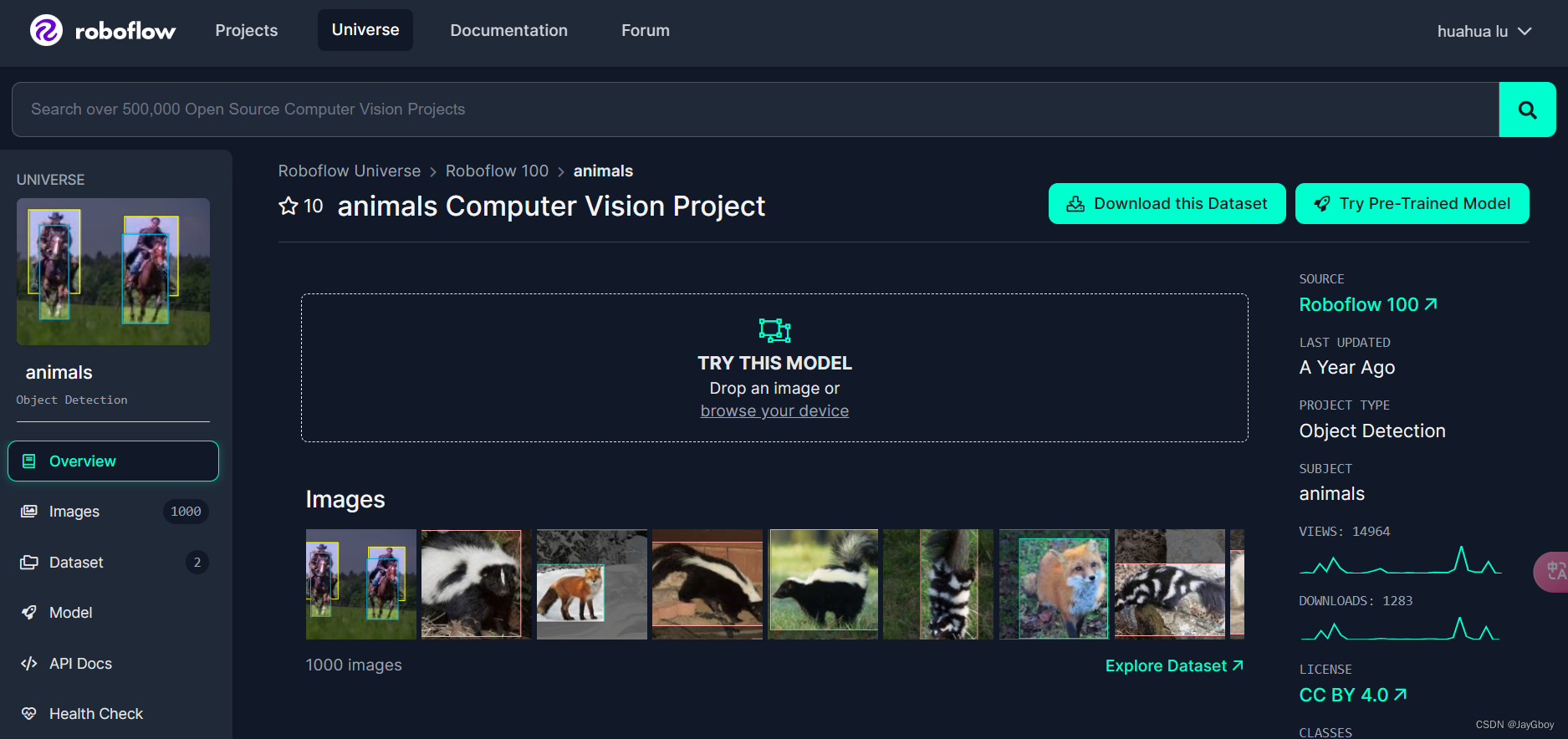
点击左旁工具栏的Dataset:
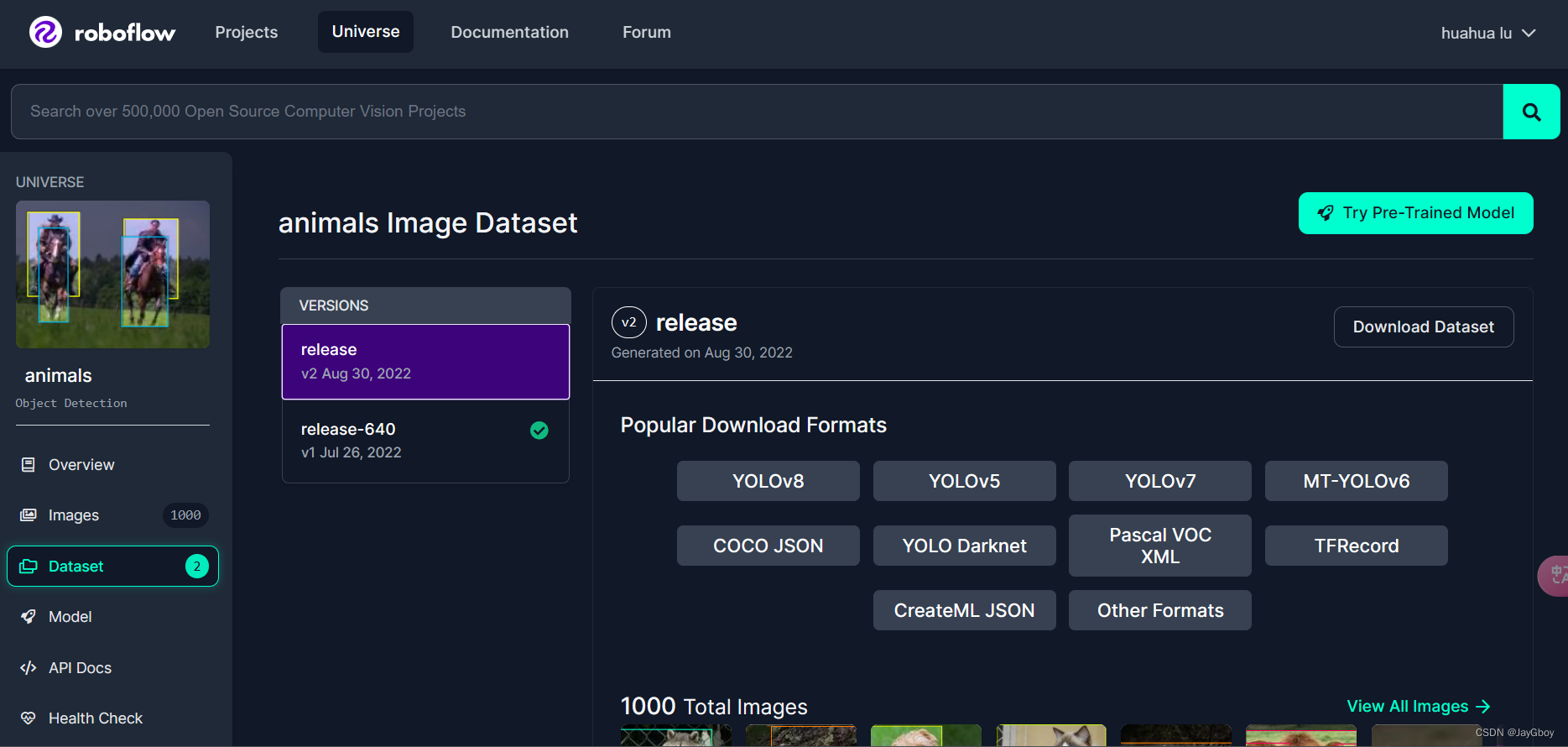
由于我们需要的是在YOLOv8下训练的数据集,故点击YOLOv8
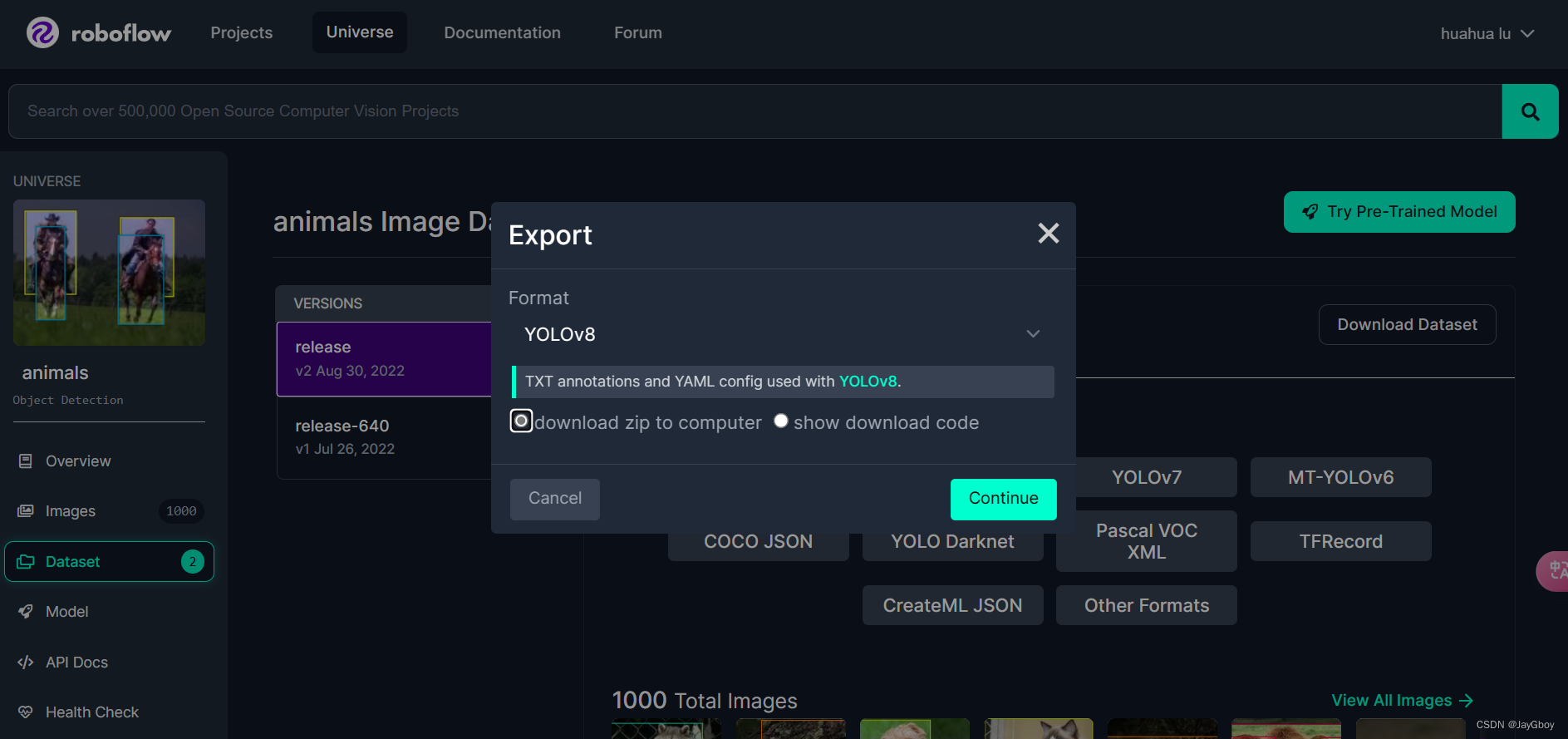
在窗口中选择download zip to computer(下载压缩包至电脑)
即可下载完成
训练数据集
打开pycharm,在安装好的YOLOv8项目下新建datasets文件夹
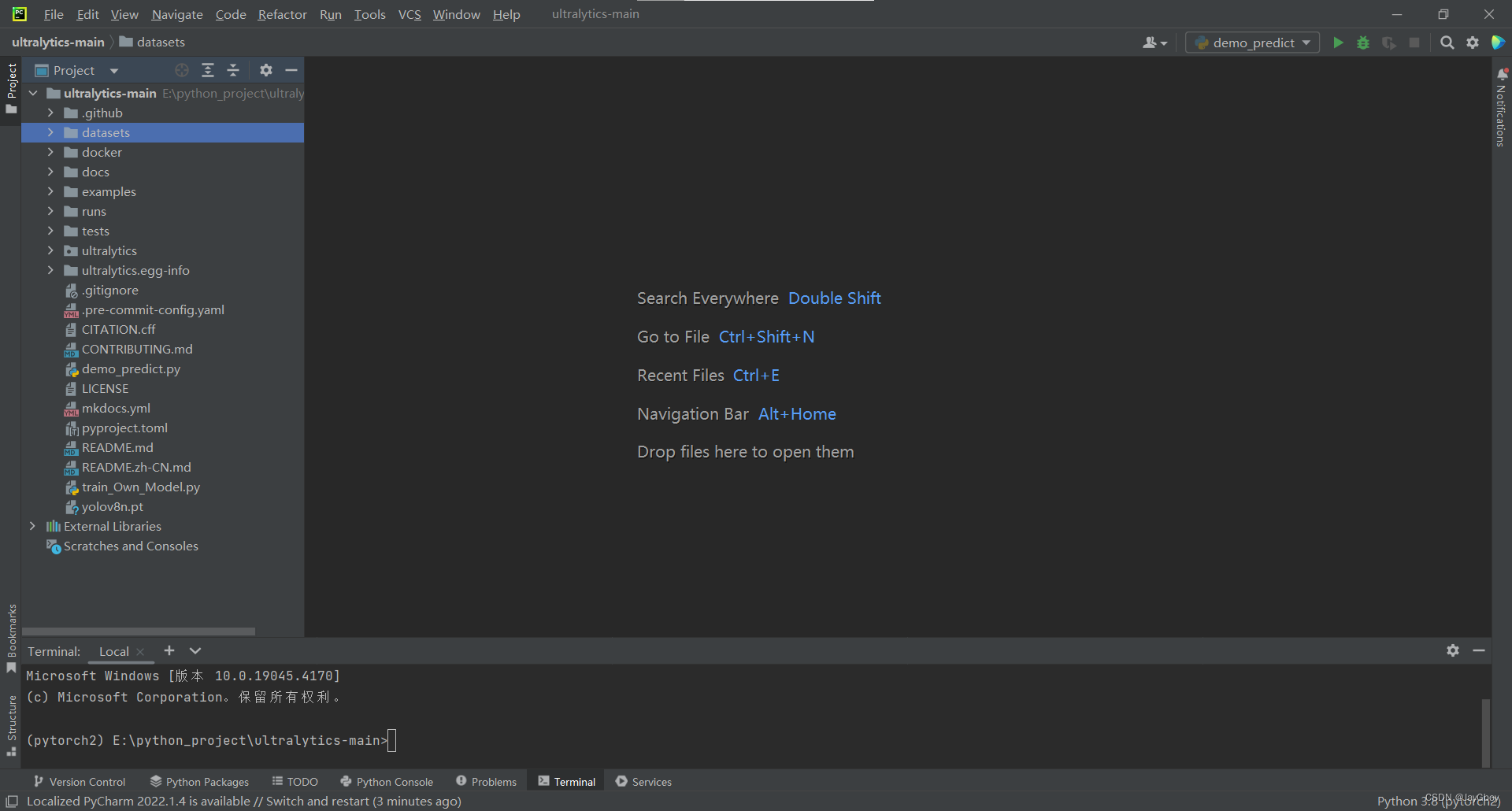
将下载好的Roboflow公开数据集(我下载的animals数据集)解压到datasets文件夹中,目录格式如下:
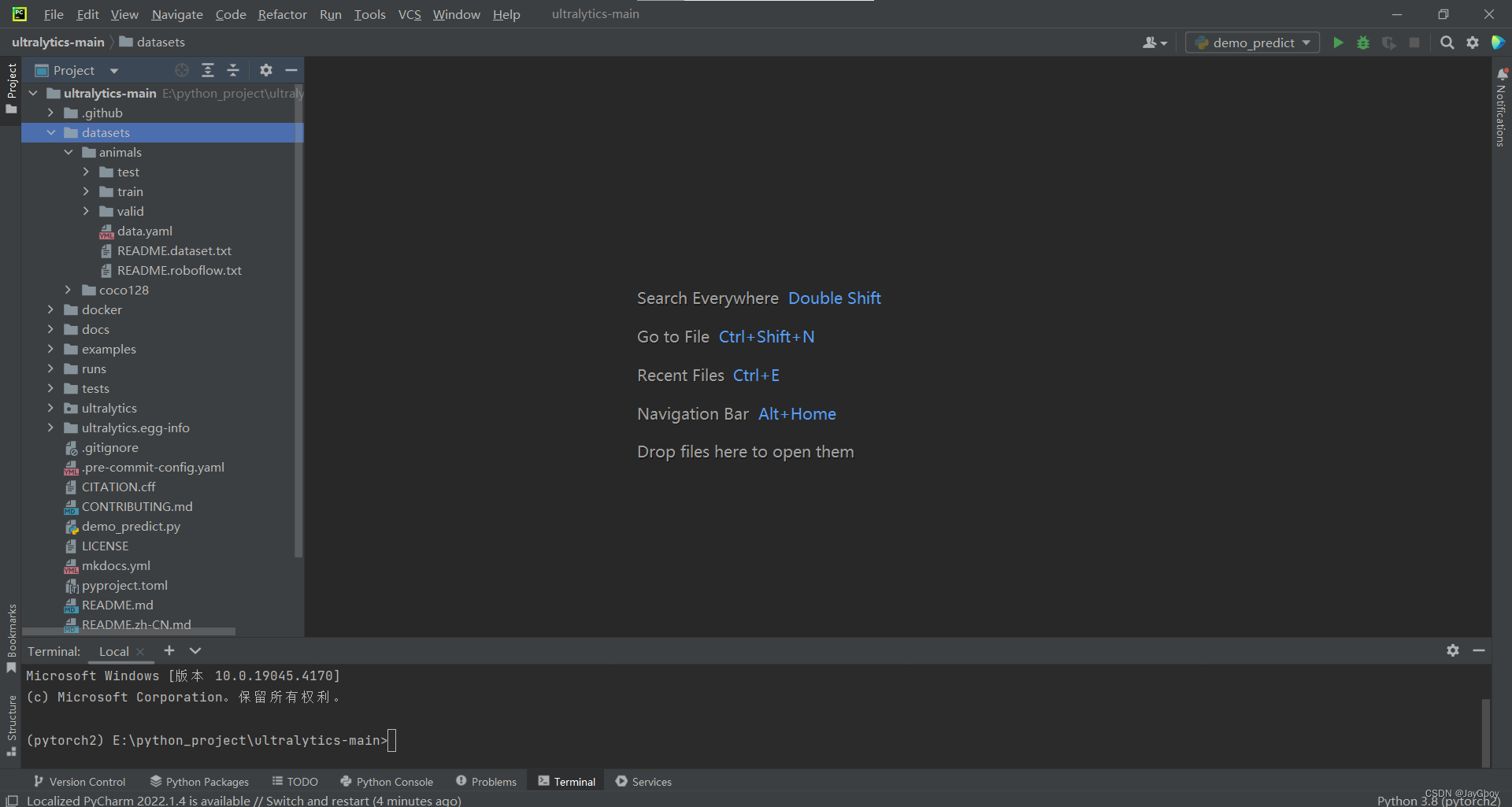
注:coco128是另外一个数据集。
此时打开animals数据集文件夹中的data.yaml文件:
train: ../train/images
val: ../valid/images
test: ../test/imagesnc: 10
names: ['cat', 'chicken', 'cow', 'dog', 'fox', 'goat', 'horse', 'person', 'racoon', 'skunk']roboflow:workspace: roboflow-100project: animals-ij5d2version: 2license: CC BY 4.0url: https://universe.roboflow.com/roboflow-100/animals-ij5d2/dataset/2此数据集共分为10类,训练、测试的地址都有给出。
在确保文件目录格式正确,存在yaml文件之后,打开pycharm终端控制器:
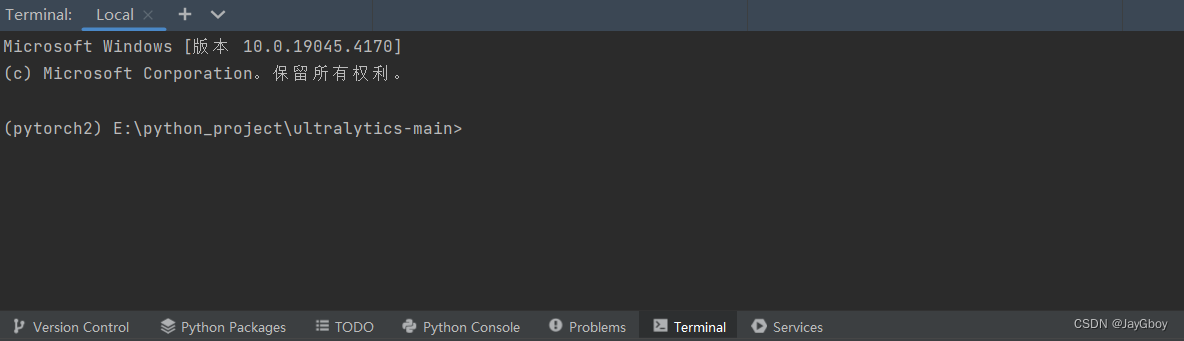
一定要进入所建的YOLOv8环境中。
模型训练在终端运行:
yolo detect train data=datasets/animals/data.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 batch=4 lr0=0.01 resume=True注意:data=后要填写数据集文件夹中的yaml文件的绝对地址,相对地址可能会报错。
当然在训练的代码中会有许多参数,以上所填的是常用的训练参数,完整的训练参数如下:
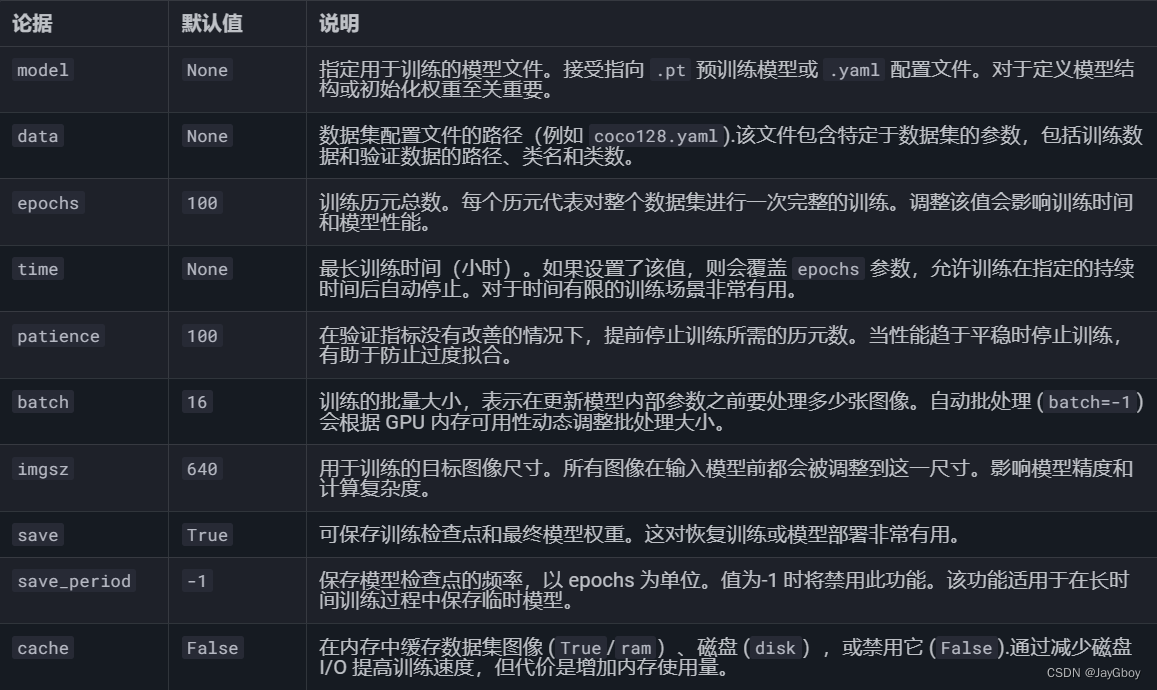

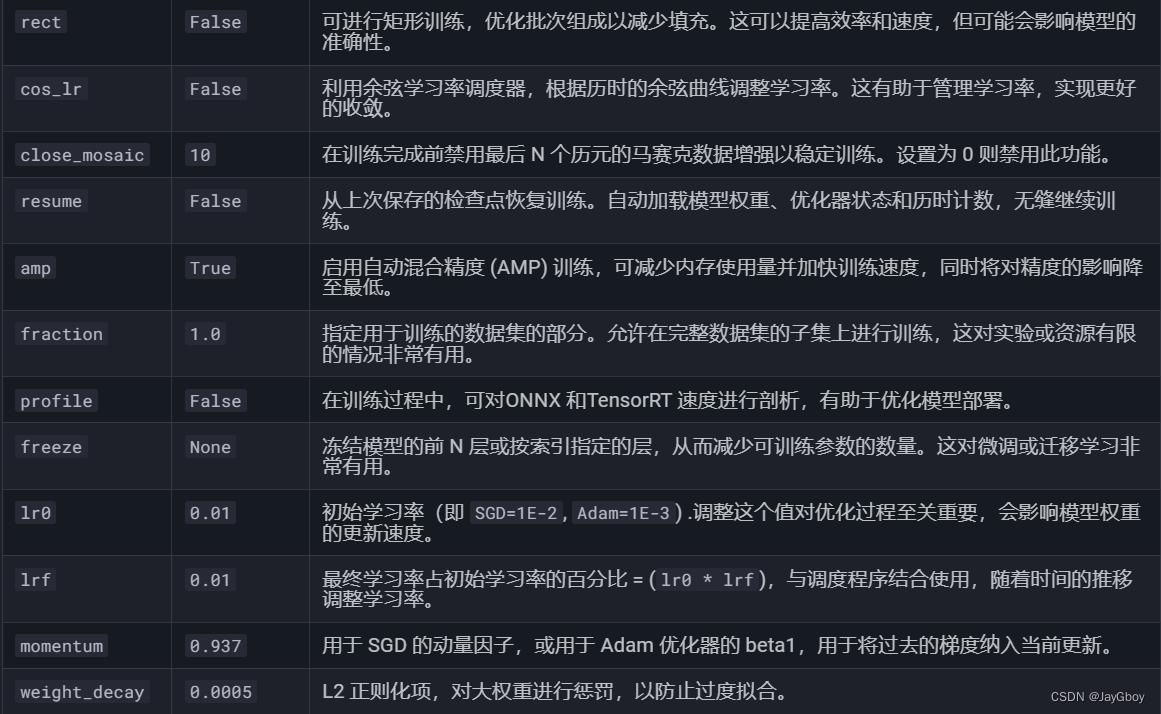
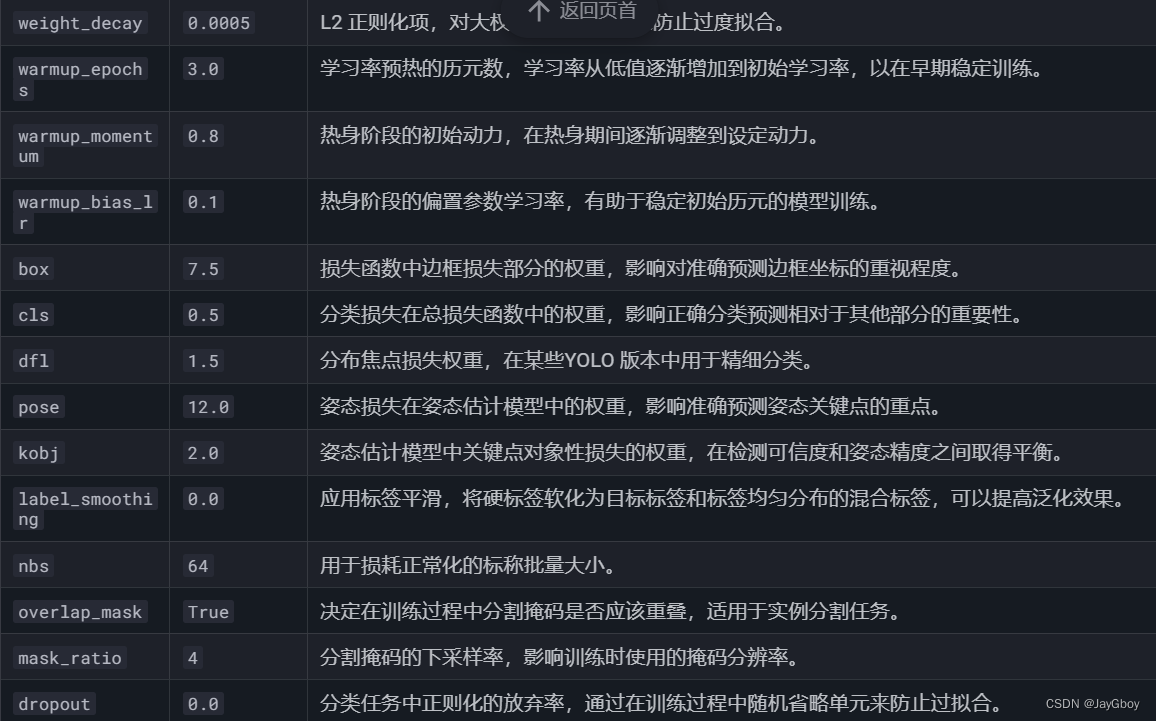
可参考YOLOv8文档:https://docs.ultralytics.com/modes/train/
按回车即可开始训练数据集,系统将自动将训练好的模型保存至runs/detect/train文件夹下:
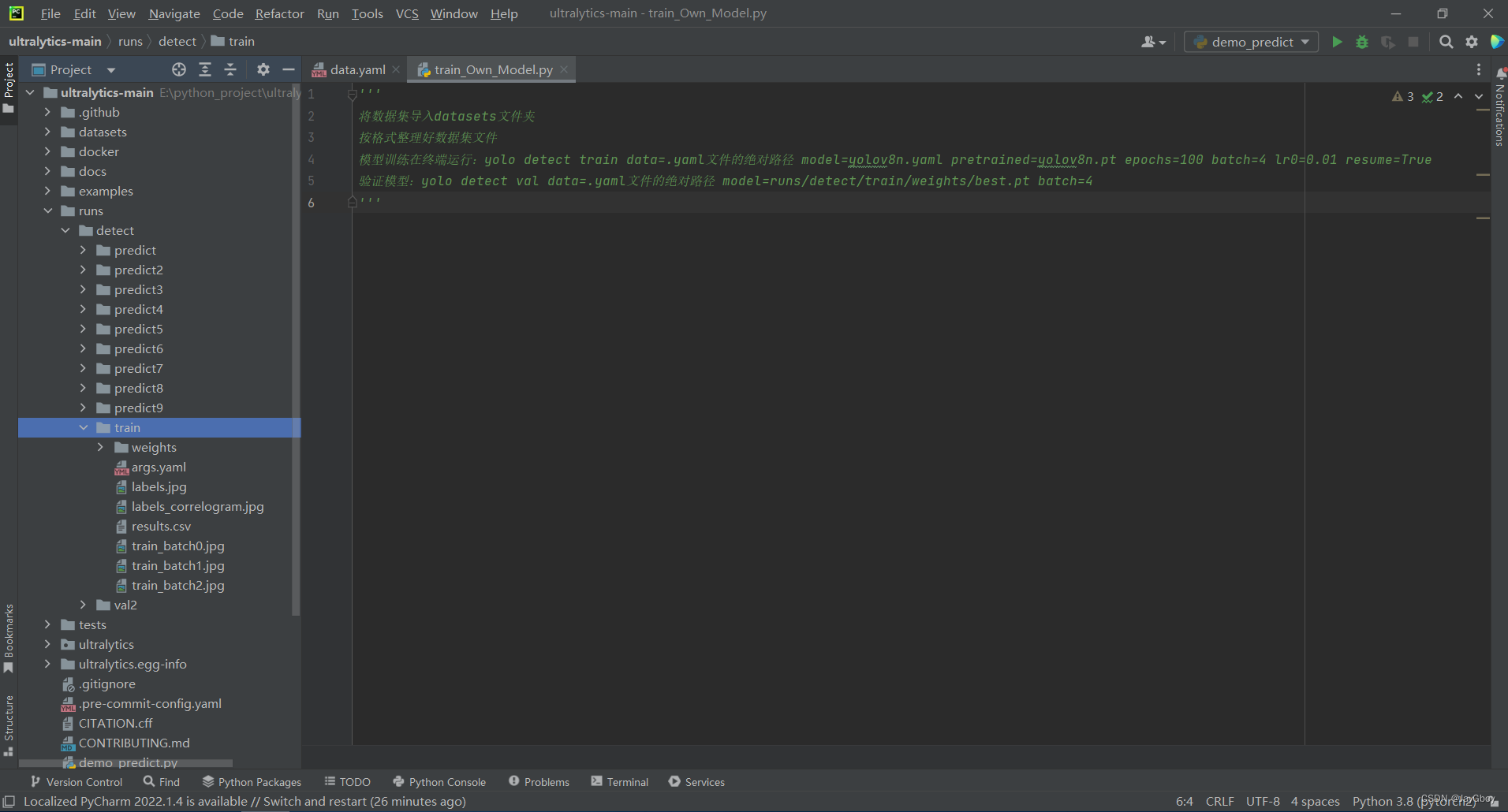
其中weights文件中为,最后一次训练的模型last.pt以及效果最好的一次模型best.pt
以及数据集的标签图等:
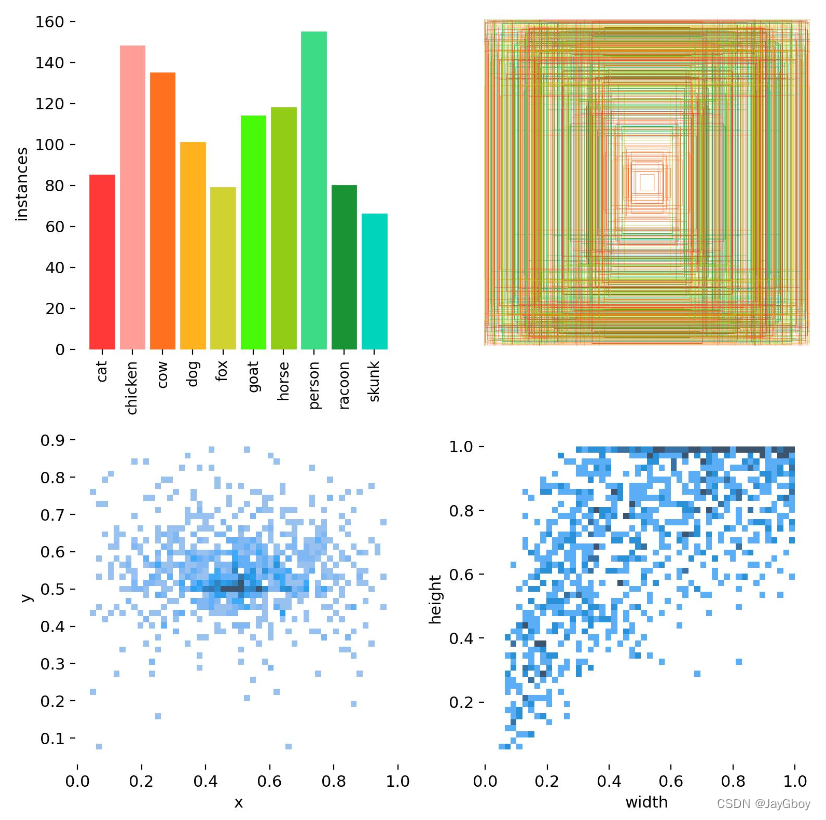
验证数据集
在终端命令行输入:
yolo detect val data=E:\python_project\ultralytics-main\datasets\animals\data.yaml model=runs/detect/train/weights/best.pt batch=4产生输出:
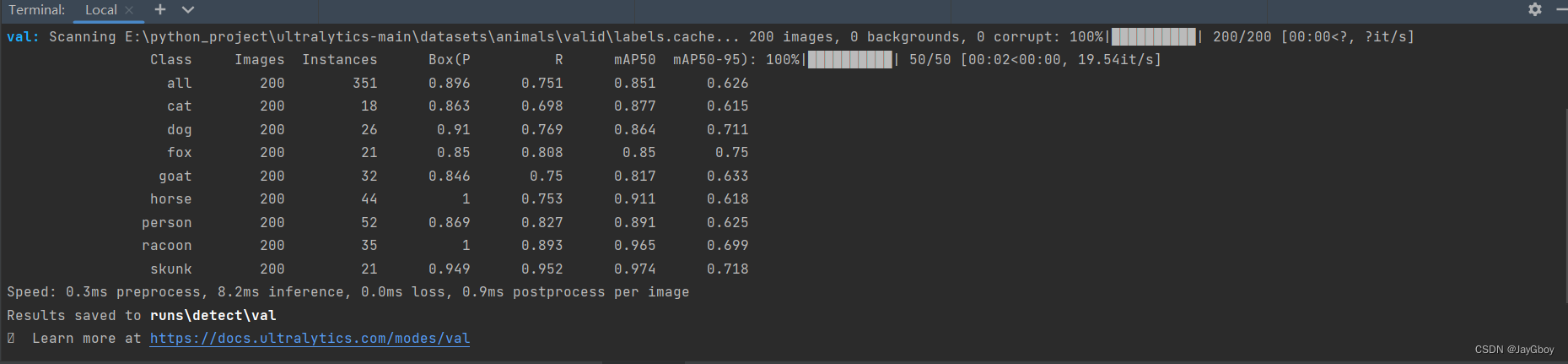
其验证结果将保存至runs\detect\val文件夹下:
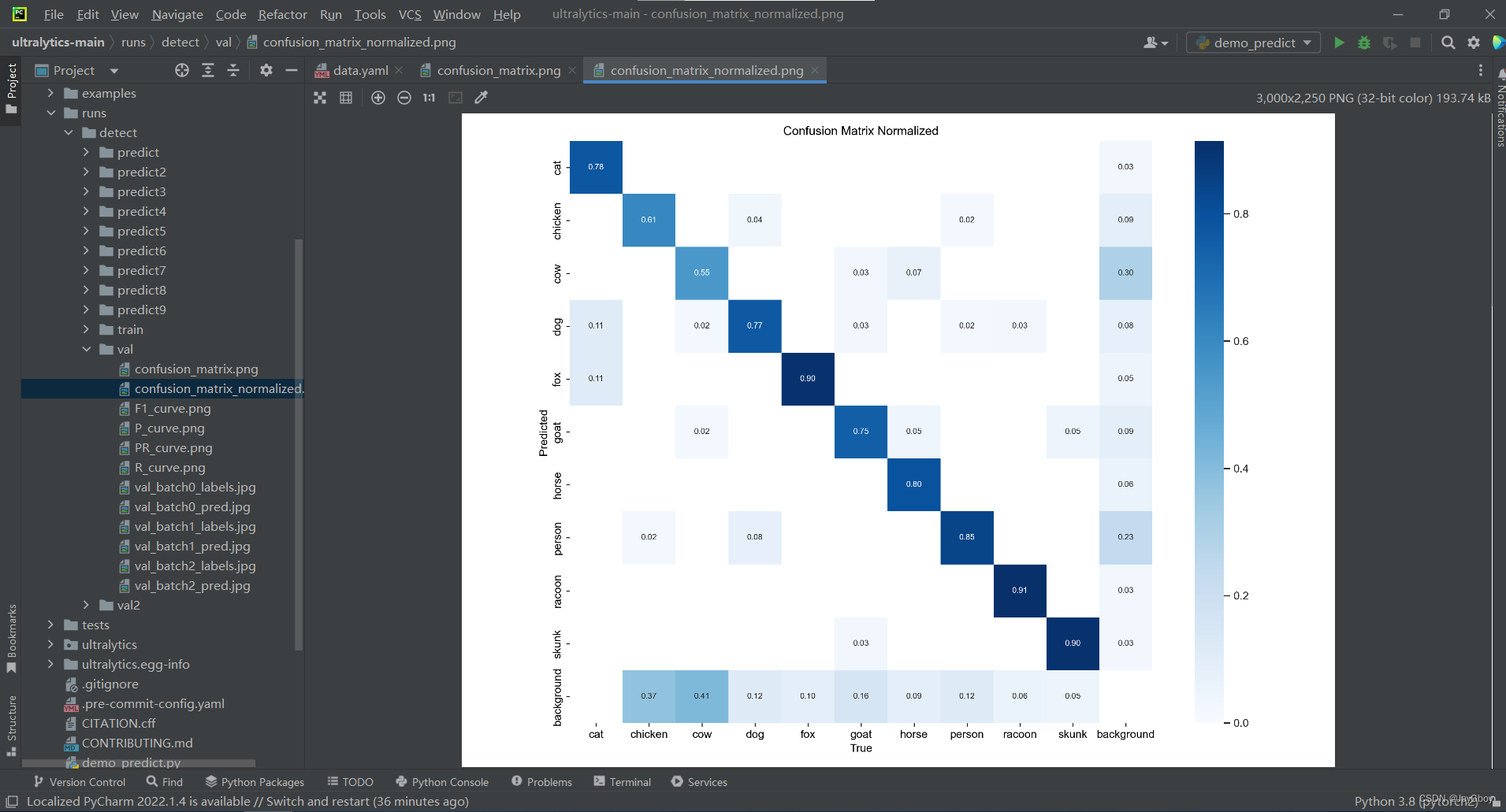
可以看出训练的模型产生了较好的预测结果。
模型导出
使用下面的命令就可以导出模型:
yolo task=detect mode=export model=ultralytics/yolo/v8/detect/runs/detect/train/weights/best.pt
参考
2023最新-用yolov8训练自己的数据集
http://t.csdnimg.cn/q6Gbb
YOLOv8教程系列:一、使用自定义数据集训练YOLOv8模型
http://t.csdnimg.cn/H5et2
这篇关于YOLOv8:Roboflow公开数据集训练模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





