本文主要是介绍今日arXiv最热NLP大模型论文:COLING2024发布数据集揭示从莎士比亚时期开始的性别偏见,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言:利用大语言模型修正诗歌中的性别偏见
很多朋友可能都听过这么一句话,“女人,你的名字叫弱者”,通常会声称这是英国大文豪莎士比亚的名言。这句话是来源于莎士比亚最著名的戏剧作品 Hamlet,而且是由戏剧故事的主人公Hamlet王子说出。由此可见,从莎士比亚时期开始就有性别偏见的影子。
该研究收集了韵诗和诗歌的数据集,研究其中的性别刻板印象,并提出了一个97%的准确率模型来识别性别偏见。在此基础上,利用大语言模型(LLM)进行性别刻板印象的校正,并与人类的干预进行了对比。这项工作揭示了文学作品中性别刻板印象的普遍性及利用LLM修正性别刻板印象的潜力,对提升性别平等意识,促进艺术表达的包容性做出了贡献。
论文标题:
Revisiting The Classics: A Study on Identifying and Rectifying Gender Stereotypes in Rhymes and Poems
论文链接:
https://arxiv.org/pdf/2403.11752.pdf
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
数据集构建:收集并标注诗歌中的性别刻板印象
1. 数据来源与多样性
构建数据集的过程涉及收集儿童童谣和适合青少年的诗歌,来源包括莎士比亚和弗罗斯特等著名诗人的作品,以及如Mother Goose这样的流行集合。为确保数据集的多样性,研究者们在文学和教育领域的教育工作者的广泛咨询后,从多种出版来源收集了童谣和诗歌。此外,研究者们还使用了20份来自11种不同语言的公开翻译诗歌,以创建一个代表广泛童谣和诗歌的丰富资源。
2. 标注过程与可靠性
标注工作分为两个阶段进行。第一阶段是建立注释指南,使用数据集的一个子集。第二阶段根据已建立的指南标注剩余数据集。两位年龄分别为22岁和23岁的注释员,非英语母语者,经过17年的英语语言培训,负责50首童谣和诗歌的注释工作。为了确保客观性,注释员在不知道他们正在注释的诗歌或童谣的身份的情况下进行注释。通过多次迭代直到达到令人满意的注释员间可靠性得分。
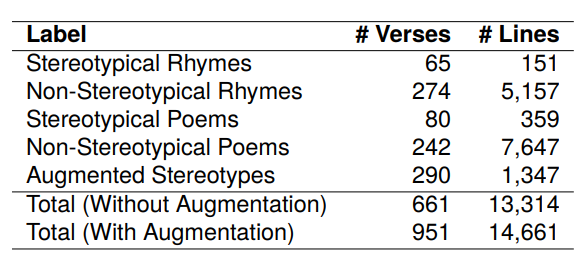
3. 文本扩展与类别不平衡问题
由于数据集中存在类别不平衡问题,研究者们使用了增强技术来增加训练集中非刻板印象诗歌的数量。数据增强是通过使用GPT-3.5合成诗歌和童谣的同义词版本来执行的。增强的结果是刻板印象诗歌和童谣的数量翻了一番,总数增加到290。通过这种方式,研究者们能够在不影响偏见的情况下增加文本的数量,以便更好地进行分析和研究。
性别刻板印象的自动识别
1. 传统机器学习方法与BERT模型的应用
为了解决不稳定性问题,研究者首先观察到,随着监督式微调(SFT)数据的指数级增加,准确率呈现出线性甚至超线性的提升。此外,当使用所有可用的GSM8K和MATH训练数据时,准确率远未达到饱和状态。这一观察鼓励研究者进一步扩大SFT数据规模。然而,公开可用的真实数学问题数据量有限,这限制了持续扩展的可能性。
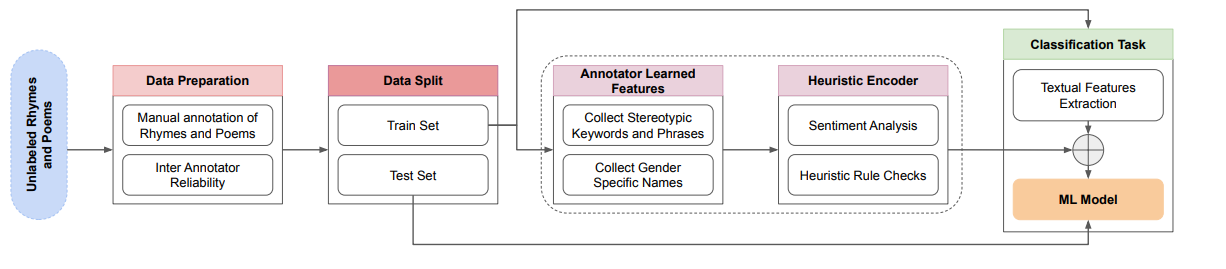
2. 创新的启发式编码器
为了克服真实数据不足的限制,研究者转向合成数据。采用GPT-4 Turbo模型来生成合成数学问题,并通过简单的验证器(同样基于GPT-4 Turbo)来提高问题的质量。通过这种方法,能够显著提高模型生成正确答案的可靠性。例如,将GSM8K的SFT数据从7.5K扩展到960K,将MATH的SFT数据从7.5K扩展到480K。这种数据扩展表现出近乎完美的扩展行为,并使模型成为第一个在GSM8K和MATH上分别超过80%和40%准确率的标准LLaMA-2 7B基础模型。
3. 模型性能比较与分析
在性能比较方面,BERTSS模型在所有指标上表现最佳,尤其是在召回率方面达到了0.81,这意味着它在减少假阴性方面表现出色,这在本研究的背景下比精确度更为重要。研究还发现,较短文本的模型性能通常优于较长文本。此外,启发式编码器的使用在长文本输入中提高了模型性能5%,在短文本上则提高了1-2%的重要指标,如精确度、召回率和F1分数。
总体而言,这些模型的比较和分析表明,结合启发式编码器的传统机器学习方法和BERT模型在自动识别性别刻板印象方面具有潜力,尤其是在处理儿童诗歌和青少年适宜诗歌的数据集时。通过这些方法的应用,研究为未来在文学作品中识别和纠正性别偏见提供了基础。
性别刻板印象的矫正方法
1. 人工与大语言模型(ChatGPT)的矫正对比
本研究中,人工注释由两位年轻的非母语英语使用者完成,他们通过多轮迭代,达到了较高的一致性。而大型语言模型的矫正能力则通过使用GPT-3.5进行文本增强和分类任务的实验来评估。在矫正性别刻板印象的任务中,人工注释和ChatGPT的矫正结果在减少刻板印象和保持创造性方面没有显著差异。
2. 矫正过程与创造性保持
在矫正过程中,一个拥有20年教育经验的教育工作者参与了人工矫正,他们在保持原文韵律和句式的同时,对20首童谣和20首诗进行了现代化的改写。而ChatGPT的矫正则是通过特定的提示来实现,旨在去除性别刻板印象,同时尽可能保持原文的句式和韵律。两种方法都在保持文本原有美感的同时进行了创造性的改写。
3. 矫正效果的验证与分析
矫正效果的验证通过一项调查来完成,调查对象包括17名参与者,他们对人工和ChatGPT矫正的文本进行了评价。评价标准包括性别刻板印象的减少程度和避免刻板印象时的创造性。统计分析显示,在减少性别刻板印象和保持创造性方面,人工矫正和ChatGPT矫正之间没有显著差异。这表明大型语言模型在矫正性别刻板印象方面的潜力,它们可以在不需要人工干预的情况下有效地减少儿童童谣和诗歌中的性别偏见。

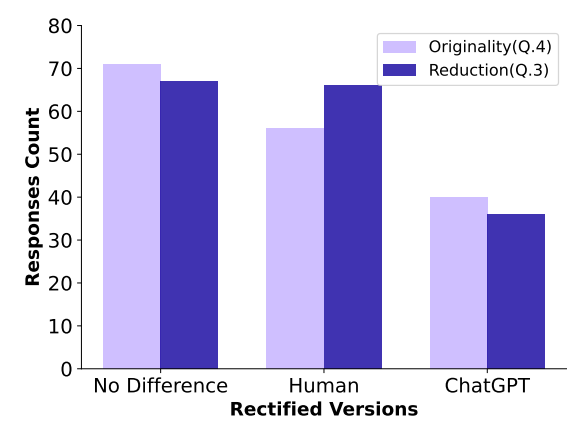
综上所述,本研究表明,通过人工注释和大语言模型的矫正,可以有效地矫正文学作品中的性别刻板印象,同时保持文本的创造性。这为未来使用大型语言模型来矫正文学作品中的性别偏见提供了有价值的见解和方法。
结论与展望
1. 研究贡献
本研究的贡献在于对儿童押韵诗和诗歌中性别刻板印象的识别与矫正。通过创建一个公开的数据集,手动标注了包含性别刻板印象的诗句,为未来的研究提供了宝贵的资源。研究结果表明,尽管社会价值观已发生显著变化,但一些古老的儿歌和诗歌仍然在传播性别刻板印象,这可能会对儿童的性别认同和行为产生长远影响。
2. 大语言模型在矫正文学作品中的潜力
实验表明,大语言模型(LLMs)在矫正文学作品中显示出了巨大的潜力。通过与人类教育工作者的矫正成果进行比较,发现LLMs在减少性别刻板印象和保持创造性方面与人类相当。这一发现揭示了LLMs在教育和文学创作中的应用前景,特别是在自动矫正性别偏见的文本内容方面。
3. 未来研究方向
未来的研究应当考虑扩大数据集的多样性,包括更多的文化背景和语言版本。此外,研究应当涉及更多的注释者,以确保对文本的理解和标注更为全面和精确。研究者还建议探索其他大语言模型,如Google Bard和Meta LLaMA-2,以评估它们在文学作品矫正方面的有效性。此外,未来的研究还应当关注如何将这些技术应用于实际教育环境中,以促进性别平等和多样性的教育目标。

这篇关于今日arXiv最热NLP大模型论文:COLING2024发布数据集揭示从莎士比亚时期开始的性别偏见的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





