本文主要是介绍对一亿个数据排序时间少于1秒排序算法WaveSort,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:干货干货,作者偶然在工作中悟出来了一种排序算法,听标题就很牛逼,下面开始一一让大家了解此算法。
一、首先我们直接与现有的排序算法:快速排序、C++库里的Sort、计数法桶排序进行速度对比
1、如图所示,这就是测试所需要的数据和方法。

2、用1000个升序数据进行排序,小于几毫秒我就不写了,直接写毫秒
C++Sort时间为:2ms,快排:2ms,波浪:1ms,桶排1ms,桶排永远都很快,它是消耗空间获取速度的,如果不懂桶排可以先去学习下。




3、1000个升序数据,然后随机打乱1000次,注意打乱是指随机1000个位置,然后每个位置的数也随机,所以最后出来的数据大多数可能都是有点顺序的。
C++Sort时间为:2ms,快排:1ms,波浪:1ms,桶排1ms




3、用10000个升序数据进行排序
C++Sort时间为:7ms,快排:127ms,波浪:1ms,桶排1ms




4、10000个升序数据,然后随机打乱10000次
C++Sort时间为:16ms,快排:2ms,波浪:45ms,桶排1ms

![]()

![]()
4、一百万个升序数据
C++Sort时间为:968ms,快排:作者等不下去了,波浪:3ms,桶排15ms,有序作者的O(n)的,快排O(N^2),到这里其实作者的排序算法作用还没很好体现,下面开始就露出水面了。



5、一百万个升序数据,随机打乱10000次
C++Sort时间为:973ms,快排:等不下去,波浪:220ms,桶排14ms



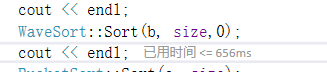
5、一百万个升序数据,随机打乱一百万次
C++Sort时间为:994ms,快排:等不下去,波浪:656ms,桶排15ms


6、一千万个升序数据
C++Sort时间为:等不下去,快排:等不下去,波浪:23ms,桶排140ms


6、一千万个升序数据,随机打乱一千万次
C++Sort时间为:12s,快排:等不下去,波浪:666ms,桶排139ms



7、一亿万个升序数据
C++Sort时间为:等不下去,快排:等不下去,波浪:226ms,桶排1391ms


7、一亿万个升序数据,随机打乱1次
C++Sort时间为:等不下去,快排:等不下去,波浪:224ms,桶排1370ms


8、一亿万个升序数据,随机打乱一万次
C++Sort时间为:等不下去,快排:等不下去,波浪:430ms,桶排1378ms


9、一亿万个升序数据,随机打乱一百万次
C++Sort时间为:等不下去,快排:等不下去,波浪:868ms,桶排1409ms


10、一亿万个升序数据,随机打乱亿万次
C++Sort时间为:等不下去,快排:等不下去,波浪:868ms,桶排1397ms


11、一亿万个升序数据,随机打乱一亿万次,波浪的空间复杂度是O(1),不管多少次,波浪空间复杂度都是O(1),递归次数2,其实递归是1,因为加了优化多了个函数还没介绍,后面介绍。

从以上测试表明作者的波浪是不是屌爆了,是的,其实波浪算法也是有优缺点的,如果读者有认真读或许已经猜到了。
优点:如果数据越有序速度越快,平均时间复杂度O (nlogn),最快O(n),最慢O(n^2)
缺点:很乱的一组数据非常不友好,它跟快排是相反的,快排越乱越快,但是好处是快排超过百万数据就算很乱也要排很久
波浪就算1亿个数据,只要不要乱到完全无序还有点秩序都非常快。
二、波浪算法优化
假设在一亿个数据中被改变了几百万或几千万数据,这时的数据虽然还有点点秩序但其实很乱了,这个时候如果用快速排序先排N遍到有点秩序了再用波浪排就会提高速度,下面作者表演针对这类数据的优化操作。
1、一亿万个升序数据,随机打乱一亿次,进行在波浪排序前先快速排序递归10000遍,第三个参数就是快排递归几遍。
优化前:886ms,优化后:539ms,


2、一亿万个升序数据,随机打乱一百万次
优化前:913ms,优化后:565ms,


3、一亿万个升序数据,随机打乱十万次
优化前:869ms,优化后:764ms,


4、一亿万个升序数据,随机打乱一万次
优化前:445ms,优化后:1456ms,


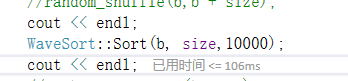
5、十万个升序数据,随机打乱十万次
优化前:445ms,优化后:106ms,

测试所得:此类优化作者已经测试只适用于数据超过10万,数据低于10万时快排递归次数设置为0合适,并且数据被打乱小于100000都不要使用哪怕一次递归快排。
总结:波浪非常适用有秩序的数据组中改变一些值导致无序的数据组进行排序,如果你有一股已排序数据,当其中一个或多个数据发生改变导致秩序变化时,这时候波浪就是最好选择。、
三、实现原理
下面是以升序排序为例,index会一直往右边移动,当发现当前元素大于下一个元素时,这时将下一个元素往回滚动并与每一个元素比较,比它大的都往后面挪动一次,直到找到等于或小于它的元素时就将它放到该元素后面,然后index继续右移判断,就这样以此类推。
数据3、4、2、5、7、10、4,波浪排序比较13次,快速排序比较23


源码:
int counts = 0;
int Prob = 0;
class WaveSort
{
public:template<class T>static void SortFaser(T *arr, int left, int right){if (left < right){if (counts++ >= Prob)return;int tmp = Tmp(&*arr, left, right);SortFaser(&*arr, left, tmp - 1);SortFaser(&*arr, tmp + 1, right);}}template<class T>static int Tmp(T * arr, int left, int right){T tmp = arr[left];while (left < right){while (left < right && tmp <= arr[right]){right--;}arr[left] = arr[right];while (left < right && tmp >= arr[left]){left++;}arr[right--] = arr[left];}arr[left] = tmp;return left;}template<class T>static void Sort(T * arr,const int nLen,int FaserCount){Prob = FaserCount;//快排递归次数SortFaser(arr, 0, nLen - 1);if(nLen <= 1) {return;}T oCompareItem;int nEnd = -1;int eIndex = -1;int bIndex = -1;bool isOne = true;while(true){/*for(int i = 0; i < 16; i++){cout<<arr[i]<<" ";}cout<<endl;*///找到第一个小于自己前一个元素的元素for(eIndex = eIndex + 1; eIndex < nLen - 1; eIndex++){if(arr[eIndex] > arr[eIndex + 1]){oCompareItem = arr[eIndex + 1];nEnd = eIndex;break;} }//不需要排序或已经到结尾了if(nEnd == -1 || eIndex == nLen - 1){return;}arr[nEnd + 1] = arr[nEnd--];isOne = true;//把前面大于自己的元素往后移动一位for(bIndex = nEnd; bIndex >= 0; bIndex--){if(arr[bIndex] > oCompareItem){arr[bIndex + 1] = arr[bIndex];}else{arr[bIndex + 1] = oCompareItem;isOne = false;break;} }if(isOne){arr[0] = oCompareItem;}} }
};完整工程文件
这篇关于对一亿个数据排序时间少于1秒排序算法WaveSort的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





