本文主要是介绍CoAtNet实战:使用CoAtNet对植物幼苗进行分类(pytorch),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
虽然Transformer在CV任务上有非常强的学习建模能力,但是由于缺少了像CNN那样的归纳偏置,所以相比于CNN,Transformer的泛化能力就比较差。因此,如果只有Transformer进行全局信息的建模,在没有预训练(JFT-300M)的情况下,Transformer在性能上很难超过CNN(VOLO在没有预训练的情况下,一定程度上也是因为VOLO的Outlook Attention对特征信息进行了局部感知,相当于引入了归纳偏置)。既然CNN有更强的泛化能力,Transformer具有更强的学习能力,那么,为什么不能将Transformer和CNN进行一个结合呢?
谷歌的最新模型CoAtNet做了卷积 + Transformer的融合,在ImageNet-1K数据集上取得88.56%的成绩。今天我们就用CoAtNet实现植物幼苗的分类。
论文:https://arxiv.org/pdf/2106.04803v2.pdf
github复现:GitHub - chinhsuanwu/coatnet-pytorch: A PyTorch implementation of “CoAtNet: Marrying Convolution and Attention for All Data Sizes”.

项目结构
CoAtNet_demo
│
├─data
│ └─train
│ ├─Black-grass
│ ├─Charlock
│ ├─Cleavers
│ ├─Common Chickweed
│ ├─Common wheat
│ ├─Fat Hen
│ ├─Loose Silky-bent
│ ├─Maize
│ ├─Scentless Mayweed
│ ├─Shepherds Purse
│ ├─Small-flowered Cranesbill
│ └─Sugar beet
├─dataset
│ └─dataset.py
└─models
│ └─coatnet.py
│
└─train.py
│
└─test.py
数据集
数据集选用植物幼苗分类,总共12类。数据集连接如下:
链接:https://pan.baidu.com/s/1TOLSNj9JE4-MFhU0Yv8TNQ
提取码:syng
在工程的根目录新建data文件夹,获取数据集后,将trian和test解压放到data文件夹下面,如下图:
安装库,并导入需要的库
安装完成后,导入到项目中。
import torch.optim as optim
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
from dataset.dataset import SeedlingData
from torch.autograd import Variable
from models.coatnet import coatnet_0设置全局参数
设置使用GPU,设置学习率、BatchSize、epoch等参数
# 设置全局参数
modellr = 1e-4
BATCH_SIZE = 16
EPOCHS = 50
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
数据预处理
数据处理比较简单,没有做复杂的尝试,有兴趣的可以加入一些处理。
# 数据预处理transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
transform_test = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
数据读取
然后我们在dataset文件夹下面新建 init.py和dataset.py,在mydatasets.py文件夹写入下面的代码:
说一下代码的核心逻辑。
第一步 建立字典,定义类别对应的ID,用数字代替类别。
第二步 在__init__里面编写获取图片路径的方法。测试集只有一层路径直接读取,训练集在train文件夹下面是类别文件夹,先获取到类别,再获取到具体的图片路径。然后使用sklearn中切分数据集的方法,按照7:3的比例切分训练集和验证集。
第三步 在__getitem__方法中定义读取单个图片和类别的方法,由于图像中有位深度32位的,所以我在读取图像的时候做了转换。
代码如下:
# coding:utf8
import os
from PIL import Image
from torch.utils import data
from torchvision import transforms as T
from sklearn.model_selection import train_test_splitLabels = {'Black-grass': 0, 'Charlock': 1, 'Cleavers': 2, 'Common Chickweed': 3,'Common wheat': 4, 'Fat Hen': 5, 'Loose Silky-bent': 6, 'Maize': 7, 'Scentless Mayweed': 8,'Shepherds Purse': 9, 'Small-flowered Cranesbill': 10, 'Sugar beet': 11}class SeedlingData (data.Dataset):def __init__(self, root, transforms=None, train=True, test=False):"""主要目标: 获取所有图片的地址,并根据训练,验证,测试划分数据"""self.test = testself.transforms = transformsif self.test:imgs = [os.path.join(root, img) for img in os.listdir(root)]self.imgs = imgselse:imgs_labels = [os.path.join(root, img) for img in os.listdir(root)]imgs = []for imglable in imgs_labels:for imgname in os.listdir(imglable):imgpath = os.path.join(imglable, imgname)imgs.append(imgpath)trainval_files, val_files = train_test_split(imgs, test_size=0.3, random_state=42)if train:self.imgs = trainval_fileselse:self.imgs = val_filesdef __getitem__(self, index):"""一次返回一张图片的数据"""img_path = self.imgs[index]img_path=img_path.replace("\\",'/')if self.test:label = -1else:labelname = img_path.split('/')[-2]label = Labels[labelname]data = Image.open(img_path).convert('RGB')data = self.transforms(data)return data, labeldef __len__(self):return len(self.imgs)
然后我们在train.py调用SeedlingData读取数据 ,记着导入刚才写的dataset.py(from mydatasets import SeedlingData)
# 读取数据
dataset_train = SeedlingData('data/train', transforms=transform, train=True)
dataset_test = SeedlingData("data/train", transforms=transform_test, train=False)
# 导入数据
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
设置模型
- 设置loss函数为nn.CrossEntropyLoss()。
- 设置模型为coatnet_0,修改最后一层全连接输出改为12。
- 优化器设置为adam。
- 学习率调整策略改为余弦退火
# 实例化模型并且移动到GPU
criterion = nn.CrossEntropyLoss()model_ft = coatnet_0()
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, 12)
model_ft.to(DEVICE)
# 选择简单暴力的Adam优化器,学习率调低
optimizer = optim.Adam(model_ft.parameters(), lr=modellr)
cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer,T_max=20,eta_min=1e-9)
# 定义训练过程def train(model, device, train_loader, optimizer, epoch):model.train()sum_loss = 0total_num = len(train_loader.dataset)print(total_num, len(train_loader))for batch_idx, (data, target) in enumerate(train_loader):data, target = Variable(data).to(device), Variable(target).to(device)output = model(data)loss = criterion(output, target)optimizer.zero_grad()loss.backward()optimizer.step()print_loss = loss.data.item()sum_loss += print_lossif (batch_idx + 1) % 10 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),100. * (batch_idx + 1) / len(train_loader), loss.item()))ave_loss = sum_loss / len(train_loader)print('epoch:{},loss:{}'.format(epoch, ave_loss))# 验证过程
def val(model, device, test_loader):model.eval()test_loss = 0correct = 0total_num = len(test_loader.dataset)print(total_num, len(test_loader))with torch.no_grad():for data, target in test_loader:data, target = Variable(data).to(device), Variable(target).to(device)output = model(data)loss = criterion(output, target)_, pred = torch.max(output.data, 1)correct += torch.sum(pred == target)print_loss = loss.data.item()test_loss += print_losscorrect = correct.data.item()acc = correct / total_numavgloss = test_loss / len(test_loader)print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(avgloss, correct, len(test_loader.dataset), 100 * acc))# 训练for epoch in range(1, EPOCHS + 1):train(model_ft, DEVICE, train_loader, optimizer, epoch)cosine_schedule.step()val(model_ft, DEVICE, test_loader)
torch.save(model_ft, 'model.pth')
测试
测试集存放的目录如下图:
第一步 定义类别,这个类别的顺序和训练时的类别顺序对应,一定不要改变顺序!!!!
classes = ('Black-grass', 'Charlock', 'Cleavers', 'Common Chickweed','Common wheat', 'Fat Hen', 'Loose Silky-bent','Maize', 'Scentless Mayweed', 'Shepherds Purse', 'Small-flowered Cranesbill', 'Sugar beet')第二步 定义transforms,transforms和验证集的transforms一样即可,别做数据增强。
transform_test = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
第三步 加载model,并将模型放在DEVICE里。
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = torch.load("model.pth")
model.eval()
model.to(DEVICE)
第四步 读取图片并预测图片的类别,在这里注意,读取图片用PIL库的Image。不要用cv2,transforms不支持。
path = 'data/test/'
testList = os.listdir(path)
for file in testList:img = Image.open(path + file)img = transform_test(img)img.unsqueeze_(0)img = Variable(img).to(DEVICE)out = model(img)# Predict_, pred = torch.max(out.data, 1)print('Image Name:{},predict:{}'.format(file, classes[pred.data.item()]))
测试完整代码:
import torch.utils.data.distributed
import torchvision.transforms as transforms
from PIL import Image
from torch.autograd import Variable
import osclasses = ('Black-grass', 'Charlock', 'Cleavers', 'Common Chickweed','Common wheat', 'Fat Hen', 'Loose Silky-bent','Maize', 'Scentless Mayweed', 'Shepherds Purse', 'Small-flowered Cranesbill', 'Sugar beet')
transform_test = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = torch.load("model.pth")
model.eval()
model.to(DEVICE)path = 'data/test/'
testList = os.listdir(path)
for file in testList:img = Image.open(path + file)img = transform_test(img)img.unsqueeze_(0)img = Variable(img).to(DEVICE)out = model(img)# Predict_, pred = torch.max(out.data, 1)print('Image Name:{},predict:{}'.format(file, classes[pred.data.item()]))
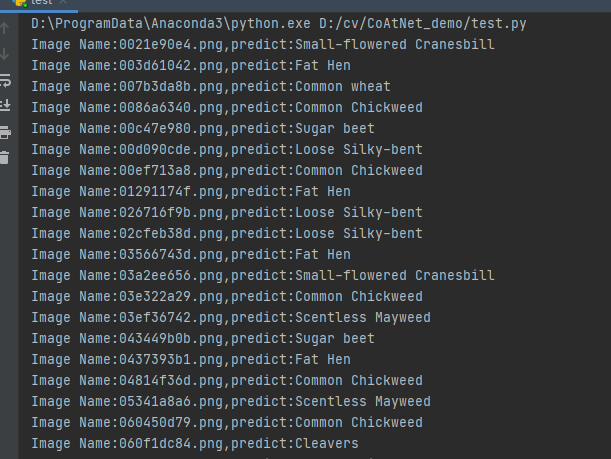
运行结果:
这篇关于CoAtNet实战:使用CoAtNet对植物幼苗进行分类(pytorch)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





