本文主要是介绍如何兼顾性能+实时性处理缓冲数据?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、实例演示
二、待处理的批量数据:Batch
我们经常会遇到这样的数据处理应用场景:我们利用一个组件实时收集外部交付给它的数据,并由它转发给一个外部处理程序进行处理。考虑到性能,它会将数据存储在本地缓冲区,等累积到指定的数量后打包发送;考虑到实时性,数据不能在缓冲区存太长的时间,必须设置一个延时时间,一旦超过这个时间,缓冲的数据必须立即发出去。看似简单的需求,如果需要综合考虑性能、线程安全、内存分配,要实现起来还真有点麻烦。这个问题有不同的解法,本文提供一种实现方案。
一、实例演示
二、待处理的批量数据:Batch<T>
三、接收、缓冲、打包和处理数据:Batcher<T>
一、实例演示
我们先来看看最终达成的效果。在如下这段代码中,我们使用一个Batcher<string>对象来接收应用分发给它的数据,该对象最终会在适当的时机处理它们。调用Batcher<string>构造函数的三个参数分别表示:
-
processor:批量处理数据的委托对象,它指向的Process方法会将当前时间和处理的数据量输出到控制台上;
-
batchSize:单次处理的数据量,当缓冲的数据累积到这个阈值时会触发数据的自动处理。我们将这个阈值设置为10;
-
interval:两次处理处理的最长间隔,我们设置为5秒;
var batcher = new Batcher<string>(processor:Process,batchSize:10,interval: TimeSpan.FromSeconds(5));
var random = new Random();
while (true)
{var count = random.Next(1, 4);for (var i = 0; i < count; i++){batcher.Add(Guid.NewGuid().ToString());}await Task.Delay(1000);
}static void Process(Batch<string> batch)
{using (batch){Console.WriteLine($"[{DateTimeOffset.Now}]{batch.Count} items are delivered.");}
}
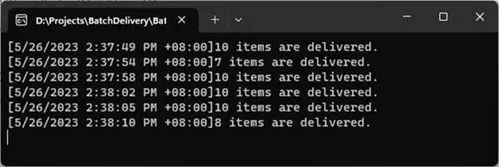
如上面的代码片段所示,在一个循环中,我们每隔1秒钟随机添加1-3个数据项。从下图中可以看出,Process方法的调用具有两种触发条件,一是累积的数据量达到设置的阈值10,另一个则是当前时间与上一次处理时间间隔超过5秒。
二、待处理的批量数据:Batch<T>
除了上面实例涉及的Batcher<T>,该解决方案还涉及两个额外的类型,如下这个Batch<T>类型表示最终发送的批量数据。为了避免缓冲数据带来的内存分配,我们使用了一个单独的ArrayPool<T>对象来创建池化的数组,这个功能体现在静态方法CreatePooledArray方法上。
由于构建Batch<T>对象提供的数组来源于对象池,在处理完毕后必须回归对象池,所以我们让这个类型实现了IDisposable接口,并将这一操作实现在Dispose方法种。在调用ArrayPool<T>对象的Return方法时,我们特意将数组清空。由于提供的数组来源于对象池,所以并不能保证每个数据元素都承载了有效的数据,实现的迭代器和返回数量的Count属性对此作了相应的处理。
public sealed class Batch<T> : IEnumerable<T>, IDisposable where T : class
{private bool _isDisposed;private int? _count;private readonly T[] _data;private static readonly ArrayPool<T> _pool = ArrayPool<T>.Create();public int Count{get{if (_isDisposed) throw new ObjectDisposedException(nameof(Batch<T>));if(_count.HasValue) return _count.Value;var count = 0;for (int index = 0; index < _data.Length; index++){if (_data[index] is null){break;}count++;}return (_count = count).Value;}}public Batch(T[] data) => _data = data ?? throw new ArgumentNullException(nameof(data));public void Dispose(){_pool.Return(_data, clearArray: true);_isDisposed = true;}public IEnumerator<T> GetEnumerator() => new Enumerator(this);IEnumerator IEnumerable.GetEnumerator() => GetEnumerator();public static T[] CreatePooledArray(int batchSize) => _pool.Rent(batchSize);private void EnsureNotDisposed(){if (_isDisposed) throw new ObjectDisposedException(nameof(Batch<T>));}private sealed class Enumerator : IEnumerator<T>{private readonly Batch<T> _batch;private readonly T[] _data;private int _index = -1;public Enumerator(Batch<T> batch){_batch = batch;_data = batch._data;}public T Current{get { _batch.EnsureNotDisposed(); return _data[_index]; }}object IEnumerator.Current => Current;public void Dispose() { }public bool MoveNext(){_batch.EnsureNotDisposed();return ++_index < _data.Length && _data[_index] is not null;}public void Reset(){_batch.EnsureNotDisposed();_index = -1;}}
}
三、接收、缓冲、打包和处理数据:Batcher<T>
最终用于打包的Batcher<T>类型定义如下。在构造函数中,我们除了提供上述两个阈值外,还提供了一个Action<Batch<T>>委托完成针对打包数据的处理。针对缓冲数据的处理实现在Process方法中。
public sealed class Batcher<T> where T : class
{private readonly int _interval;private readonly int _batchSize;private readonly Action<Batch<T>> _processor;private volatile Container _container;private readonly Timer _timer;private readonly ReaderWriterLockSlim _lock = new();public Batcher(Action<Batch<T>> processor, int batchSize, TimeSpan interval){_interval = (int)interval.TotalMilliseconds;_batchSize = batchSize;_processor = processor;_container = new Container(batchSize);_timer = new Timer(_ => Process(), null, _interval, Timeout.Infinite);}private void Process(){if (_container.IsEmpty) return;_lock.EnterWriteLock();try{if (_container.IsEmpty) return;var container = Interlocked.Exchange(ref _container, new Container(_batchSize));_ = Task.Run(() => _processor(container.AsBatch()));_timer.Change(_interval, Timeout.Infinite);}finally{_lock.ExitWriteLock();}}public void Add(T item){_lock.EnterReadLock();bool success = false;try{success = _container.TryAdd(item);}finally{_lock.ExitReadLock();}if (!success){Process();new SpinWait().SpinOnce();Add(item);}}private sealed class Container{private volatile int _next = -1;private readonly T[] _data;public bool IsEmpty => _next == -1;public Container(int batchSize) => _data = Batch<T>.CreatePooledArray(batchSize);public bool TryAdd(T item){var index = Interlocked.Increment(ref _next);if (index > _data.Length - 1) return false;_data[index] = item;return true;}public Batch<T> AsBatch() => new(_data);}
}
我们创建了一个内部类型Container作为存放数据的容器,具体数据存放在一个数组中,字段_index代表下一个添加数组存放的索引。TryAdd方法将指定的数据添加到数组中,我们使用InterLocked.Increase方法解决并发问题。如果越界返回False,表示添加失败,否则返回True,表示成功添加。Container的数组通过Batch<T>的静态方法CreatePooledArray提供的。Container类型还提供了一个AsBatch方法将数据封装成Batch<T>对象。
使用者在处理数据的时候,只需要将待处理数据作为Add方法的参数添加到缓冲区就可以了。Add方法会调用Container的TryAdd方法将指定的对象添加了池化数组中。如果TryAdd返回false,意味着数组存满了,由于此时正在发生Container替换操作,所以我们利用自旋等待的方式提高效率。
我们通过一个Timer解决缓冲数据的及时处理的问题。由于Porcess方法承载的针对缓冲数据的处理有两种触发形式:缓存数据数量超过阈值,缓冲时间超过设置的时限,我们不得不使用一个ReaderWriterLockSlim解决该方法和Add方法之间针对同一个Container对象的争用问题(我的初衷是提供完全无锁的设计,想了很久发现很难,有兴趣的朋友不妨可以想想完全无锁的解决方案是否可行)。
引入地址
这篇关于如何兼顾性能+实时性处理缓冲数据?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






