本文主要是介绍文献速递:基于SAM的医学图像分割---医疗 SAM 适配器:适配用于医学图像分割的 Segment Anything 模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Title
题目
Medical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation
医疗 SAM 适配器:适配用于医学图像分割的 Segment Anything 模型
01
文献速递介绍
最近,Segmentation Anything 模型(SAM)(Kirillov 等人,2023年)因其强大和多功能的视觉分割模型能力而受到了显著关注。它可以基于用户提示生成多样化和详细的分割掩模。尽管在自然图像上表现出色,许多最近的研究也显示(Deng 等人,2023年;Roy 等人,2023年;He 等人,2023年),其在医学图像分割上的表现不尽人意。使医学图像分割变得互动,例如采用像 SAM 这样的技术,具有巨大的临床价值。互动系统可以根据临床医生指示的兴趣区域进行优先级划分,为他们提供更加沉浸式和个性化的体验。例如,在单个眼底图像中,常常有血管、视盘、视杯和黄斑等重叠和错综复杂的结构。互动式分割可以极大地帮助临床医生有效区分这些复杂结构中的目标组织。考虑到获取大规模标注数据集的难度,采用像 SAM 这样的基础互动模型对于临床使用变得至关重要。
SAM 在医学图像上的有限表现是由于它缺乏医学特定知识,包括低图像对比度、模糊的组织边界和微小的病变区域等挑战。解决这一问题的最先进(SOTA)方法是在医学数据上完全微调原始的 SAM 模型(Ma 和 Wang 2023),这在计算和内存占用方面都相当昂贵。此外,是否真的需要完全微调还存在疑问,因为之前的研究已经显示出预训练的视觉模型对医学图像有强大的迁移能力(Raghu 等人,2019;Xie 和 Richmond,2018)。
在本文中,我们尝试用最小的努力将训练良好的 SAM 适配到医学图像分割上。技术上,我们选择使用一种叫做适配(Adaption)的参数高效微调(PEFT)技术来微调预训练的 SAM(Hu 等人,2021)。适配已经成为自然语言处理(NLP)中广泛使用的流行技术,用于微调基础预训练模型以适应各种下游任务。适配的主要思想是将带有部分参数的适配器模块插入到原始模型中,并且只更新少量额外的适配器参数,同时保持大型预训练模型冻结。
Abstract
摘要
The Segment Anything Model (SAM) has recently gained popularity in the field of image segmentation due to its im pressive capabilities in various segmentation tasks and its prompt-based interface. However, recent studies and indi vidual experiments have shown that SAM underperforms in medical image segmentation, since the lack of the medical specific knowledge. This raises the question of how to en hance SAM’s segmentation capability for medical images. In this paper, instead of fine-tuning the SAM model, we pro pose the Medical SAM Adapter (Med-SA), which incorpo rates domain-specific medical knowledge into the segmenta tion model using a light yet effective adaptation technique. In Med-SA, we propose Space-Depth Transpose (SD-Trans) to adapt 2D SAM to 3D medical images and Hyper-Prompting Adapter (HyP-Adpt) to achieve prompt-conditioned adap tation. We conduct comprehensive evaluation experiments on 17 medical image segmentation tasks across various im age modalities. Med-SA outperforms several state-of-the-art
(SOTA) medical image segmentation methods, while updat ing only 2% of the parameters. Our code is released at https:
//github.com/KidsWithTokens/Medical-SAM-Adapter.
Segment Anything
模型(SAM)最近由于其在各种分割任务中的卓越能力以及基于提示的接口,在图像分割领域获得了广泛的流行。然而,最近的研究和个体实验表明,SAM 在医学图像分割中表现不佳,原因是缺乏医学特定知识。这引发了如何提高 SAM 对医学图像分割能力的问题。在这篇论文中,我们不是对 SAM 模型进行微调,而是提出了医疗 SAM 适配器(Med-SA),它使用一种轻量级而有效的适配技术,将特定领域的医学知识整合到分割模型中。在 Med-SA 中,我们提出空间-深度转置(SD-Trans)以适配 2D 的 SAM 至 3D 医学图像,和超级提示适配器(HyP-Adpt)以实现基于提示的适配。我们在 17 个医学图像分割任务上进行了全面的评估实验,涵盖各种图像模式。Med-SA 在仅更新 2% 的参数的情况下,超越了多个最先进(SOTA)的医学图像分割方法。我们的代码已在 https://github.com/KidsWithTokens/Medical-SAM-Adapter 发布。
METHOD
方法
Preliminary: SAM architecture
To begin with, we provide an overview of the SAM architec ture. SAM comprises three main components: an image en coder, a prompt encoder, and a mask decoder. The image en coder is based on a standard Vision Transformer (ViT) pre trained by MAE. Specifically, we use the ViT-H/16 variant,
which employs 14×14 windowed attention and four equally spaced global attention blocks, as shown in 1 (a). The out put of the image encoder is a 16× downsampled embedding of the input image. The prompt encoder can be either sparse (points, boxes) or dense (masks). In this paper, we focus only on the sparse encoder, which represents points and boxes as positional encodings summed with learned embeddings for each prompt type. The mask decoder is a Transformer de coder block modified to include a dynamic mask prediction head. The decoder uses two-way cross-attention to learn the interaction between the prompt and image embeddings. Af ter that, SAM upsamples the image embedding, and an MLP maps the output token to a dynamic linear classifier, which predicts the target mask of the given image.
初步:SAM 架构
首先,我们提供 SAM 架构的概览。SAM 包含三个主要部分:图像编码器、提示编码器和掩码解码器。图像编码器基于经 MAE 预训练的标准视觉 Transformer(ViT)。具体来说,我们使用 ViT-H/16 变体,该变体采用 14×14 窗口注意力和四个等间距的全局注意力块,如图 1(a)所示。图像编码器的输出是输入图像的 16×下采样嵌入。提示编码器可以是稀疏的(点、框)或密集的(掩码)。在本文中,我们仅关注稀疏编码器,它将点和框表示为位置编码与每种提示类型的学习嵌入相加。掩码解码器是一个修改过的 Transformer 解码器块,增加了动态掩码预测头。解码器使用双向交叉注意力学习提示和图像嵌入之间的交互。之后,SAM 对图像嵌入进行上采样,一个 MLP 将输出令牌映射到动态线性分类器,该分类器预测给定图像的目标掩码。
CONCLUSION
结论
In this paper, we have extended SAM, a powerful general segmentation model, to address medical image segmenta tion, introducing Med-SA. Leveraging parameter-efficient adaptation with simple yet effective SD-Trans and HyP Adpt, we have achieved substantial improvements over the original SAM model. Our approach has resulted in SOTA performance across 17 medical image segmentation tasks spanning 5 different image modalities. We anticipate that this work will serve as a stepping stone towards advancing foundation medical image segmentation and inspire the de velopment of novel fine-tuning techniques.
在本文中,我们扩展了 SAM——一个强大的通用分割模型,以解决医学图像分割问题,引入了 Med-SA。利用参数高效的适配以及简单而有效的 SD-Trans 和 HyP-Adpt,我们在原始 SAM 模型的基础上取得了显著的改进。我们的方法在 17 个医学图像分割任务上获得了 SOTA 表现,这些任务涵盖了 5 种不同的图像模态。我们预期,这项工作将成为推进基础医学图像分割发展的垫脚石,并激发新的微调技术的开发。
Fig
图
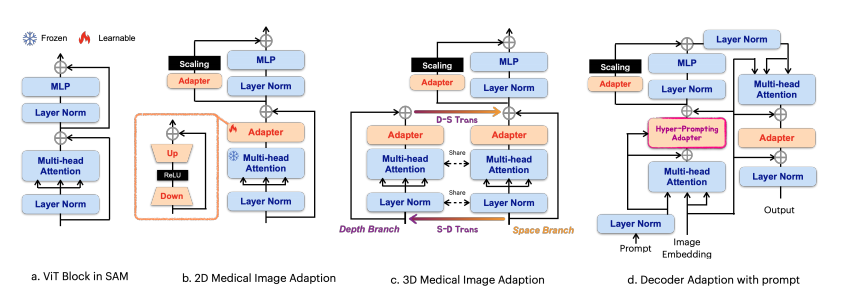
Figure 1: Med-SA architecture. We use (b) as the encoder with standard Adapter to process 2D medical images, and (c) incorporating SD-Trans to process 3D images. Then we use (d) as the decoder with HyP-Adpt to incorporate the prompts.
图 1:Med-SA 架构。我们使用 (b) 作为带有标准适配器的编码器来处理 2D 医学图像,并且使用 (c) 结合 SD-Trans 来处理 3D 图像。然后我们使用 (d) 作为解码器,配合 HyP-Adpt 来整合提示。

Figure 2: HyP-Adpt architecture. We utilize Prompt Embed ding to generate the weights that are applied to the Adapter Embedding.
图 2:HyP-Adpt 架构。我们利用提示嵌入来生成应用于适配器嵌入的权重。

Figure 3: Visual comparison of Med-SA and SAM on abdominal multi-organ segmentation. We use Check mark to represent SAM correctly found the organ and Cross to represent it lost.
图 3:Med-SA 与 SAM 在腹部多器官分割上的视觉比较。我们使用勾选标记表示 SAM 正确找到了器官,使用叉号表示它未能找到。

Figure 4: Visual comparison of Med-SA and SAM on medical image segmentation with four different modalities. Top-left:optic disc and cup segmentation from the fundus image. Top-right: brain tumor segmentation from the Brain MRI. Bottom-left: melanoma segmentation from the dermoscopic image. Bottom-right: thyroid nodule segmentation from the ultrasound image.
图 4:Med-SA 与 SAM 在四种不同模态的医学图像分割上的视觉比较。左上角:来自眼底图像的视盘和视杯分割。右上角:来自脑部 MRI 的脑瘤分割。左下角:来自皮肤镜图像的黑色素瘤分割。右下角:来自超声图像的甲状腺结节分割。
Table
表

Table 1: The comparison of Med-SA with SOTA segmentation methods over BTCV dataset evaluated by Dice Score. Best results are denoted as bold.
表 1:Med-SA 与 SOTA 分割方法在 BTCV 数据集上通过 Dice 得分评估的比较。最佳结果以加粗表示。

Table 2: The comparison of Med-SA with SAM and SOTA segmentation methods on different image modalities. The grey background denotes the methods are proposed for that/those particular tasks. Performance is omitted (-) if the algorithm fails
over 70% of the samples.
表 2:Med-SA 与 SAM 和 SOTA 分割方法在不同图像模态上的比较。灰色背景表示该方法是针对那些特定任务提出的。如果算法在超过 70% 的样本中失败,性能将被省略(-)。

Table 3: An ablation study on SD-Trans and HyP-Adpt.、
表 3:对 SD-Trans 和 HyP-Adpt 的消融研究。
这篇关于文献速递:基于SAM的医学图像分割---医疗 SAM 适配器:适配用于医学图像分割的 Segment Anything 模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






