本文主要是介绍机器学习:基于心脏病数据集的XGBoost分类预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、简介
原理:
二、实战演练
1.数据准备
2.数据读取/载入
3.数据预处理
4.可视化处理
5.对离散变量进行编码
6.模型训练与预测
7.特征选择
8.通过调整参数获得更好的效果
核心参数调优
网格调参法
一、简介
XGBoost(eXtreme Gradient Boosting)是一种梯度提升决策树(Gradient Boosting Decision Tree,GBDT)的实现,是目前最流行的机器学习算法之一,被广泛应用于各种任务,如分类、回归和排序等。它由陈天奇在2016年开发,是Boosting算法家族的成员之一,可以通过增量的方式训练模型,逐步提高模型的准确性。
与传统的决策树不同,XGBoost采用的是一种优化算法,即梯度提升算法(Gradient Boosting)。梯度提升算法是一种串行的集成方法,通过逐步训练多个弱分类器(即决策树),使它们逐渐变得更强大。在每一轮迭代中,它会计算损失函数的负梯度,作为新的训练目标,再训练一个弱分类器来拟合这个目标。最终,将所有弱分类器组合起来,形成一个强分类器。
XGBoost的优势在于它的高效性和准确性。它能够处理大规模的数据集和高维度的特征空间,且在处理稀疏数据时也表现良好。此外,XGBoost的模型训练速度快,可以处理大规模的数据集,在比赛中多次获得第一名。
总之,XGBoost是一个强大且高效的机器学习算法,广泛应用于各种领域,特别是在竞赛中和实际业务中都有着重要的应用。
原理:
XGBoost底层实现了GBDT算法,并对GBDT算法做了一系列优化:
- 对目标函数进行了泰勒展示的二阶展开,可以更加高效拟合误差。
- 提出了一种估计分裂点的算法加速CART树的构建过程,同时可以处理稀疏数据。
- 提出了一种树的并行策略加速迭代。
- 为模型的分布式算法进行了底层优化。
XGBoost是基于CART树的集成模型,它的思想是串联多个决策树模型共同进行决策。
那么如何串联呢?XGBoost采用迭代预测误差的方法串联。举个通俗的例子,我们现在需要预测一辆车价值3000元。我们构建决策树1训练后预测为2600元,我们发现有400元的误差,那么决策树2的训练目标为400元,但决策树2的预测结果为350元,还存在50元的误差就交给第三棵树……以此类推,每一颗树用来估计之前所有树的误差,最后所有树预测结果的求和就是最终预测结果!
XGBoost的基模型是CART回归树,它有两个特点:(1)CART树,是一颗二叉树。(2)回归树,最后拟合结果是连续值。
具体来说,XGBoost使用决策树作为基分类器,每个决策树都是通过梯度提升算法来训练的。在训练过程中,XGBoost会计算损失函数的负梯度,并用这个负梯度来训练一个新的决策树,通过不断地迭代,最终得到一个具有很强泛化能力的强分类器。
为了防止过拟合,XGBoost引入了正则化技术,包括L1正则化和L2正则化。L1正则化可以使模型更加稀疏,而L2正则化可以防止模型权重过大,从而避免过拟合。
除此之外,XGBoost还采用了一些优化技术,如缓存访问技术、数据压缩技术、多线程并行计算等,使得XGBoost在训练和预测速度上具有很高的效率。
二、实战演练
1.数据准备
下载阿里云提供的一个天气数据集,在pycharm之类的跑以下代码下载保存(原文是基于天气预测,举一反三学习就用心脏病这个数据集)
import requestsurl = 'https://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/7XGBoost/train.csv'
response = requests.get(url)
with open('train.csv', 'wb') as f:f.write(response.content)
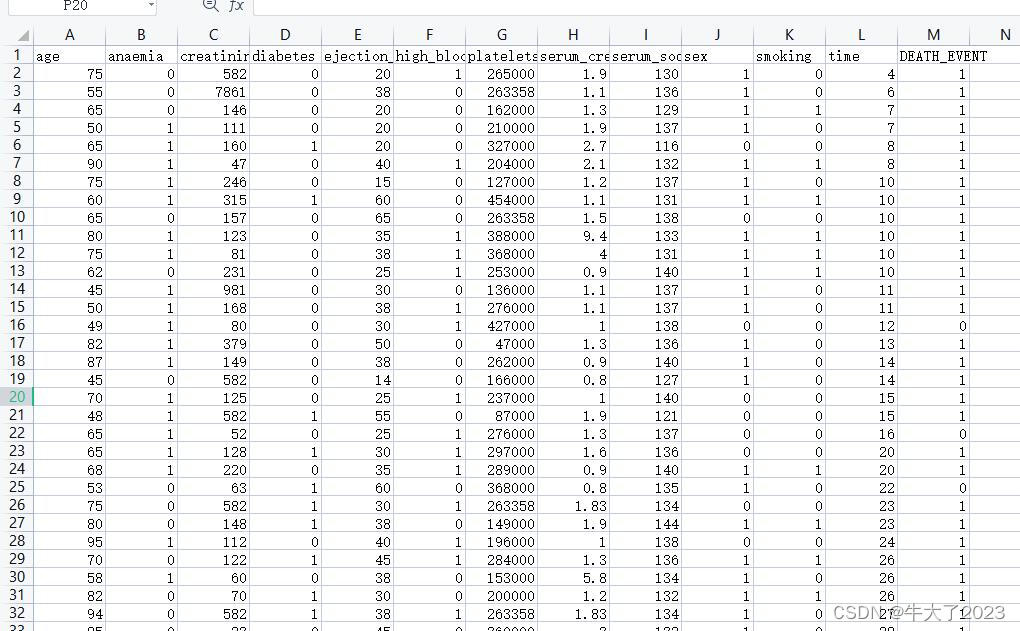
最上面分别是:年龄、是否贫血、肌酸磷酸激酶、是否糖尿病、射血分数、是否高血压、血小板血清、creatine血清_钠、性别、是否吸烟、时间、是否死亡。
原文是预测是否明天下雨,这里就预测死亡了。
2.数据读取/载入
放同一目录下,直接读即可
## 基础函数库
import numpy as np
import pandas as pd## 绘图函数库
import matplotlib.pyplot as plt
import seaborn as sns
## 我们利用Pandas自带的read_csv函数读取并转化为DataFrame格式data = pd.read_csv('heart.csv')可以打印查看下
## 利用.info()查看数据的整体信息
data.info()
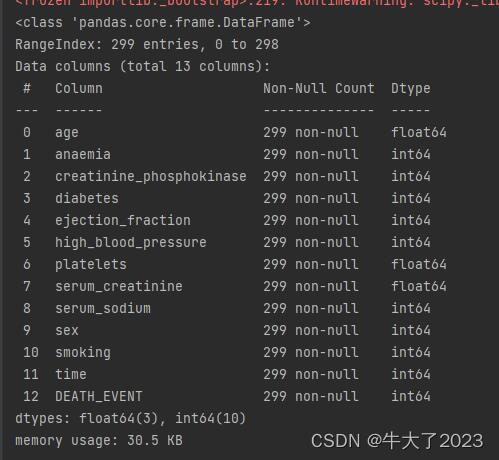
基本上都是整形和浮点型。
3.数据预处理
心脏病数据没啥问题这里不再演示,以下是说明:
简单查看数据,如果有缺少的(NaN)就用-1填补上。
## 进行简单的数据查看,我们可以利用 .head() 头部.tail()尾部
data.head()data = data.fillna(-1)
data.tail()如果数据集中的负样本数量远大于正样本数量,这种常见的问题叫做“数据不平衡”问题,在某些情况下需要进行一些特殊处理。(像我这个负样本死亡为96没死亡为203就不用处理)
print(pd.Series(data['DEATH_EVENT']).value_counts())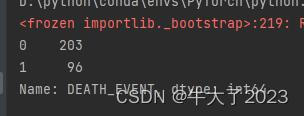
## 对于特征进行一些统计描述
data.describe()
4.可视化处理
为了方便,先纪录数字特征与非数字特征:
numerical_features = [x for x in data.columns if data[x].dtype == np.float]
category_features = [x for x in data.columns if data[x].dtype != np.float and x != 'DEATH_EVENT']
## 选取三个特征与标签组合的散点可视化
sns.pairplot(data=data[['age',
'creatinine_phosphokinase',
'ejection_fraction'] + ['DEATH_EVENT']], diag_kind='hist', hue= 'DEATH_EVENT')
plt.show()
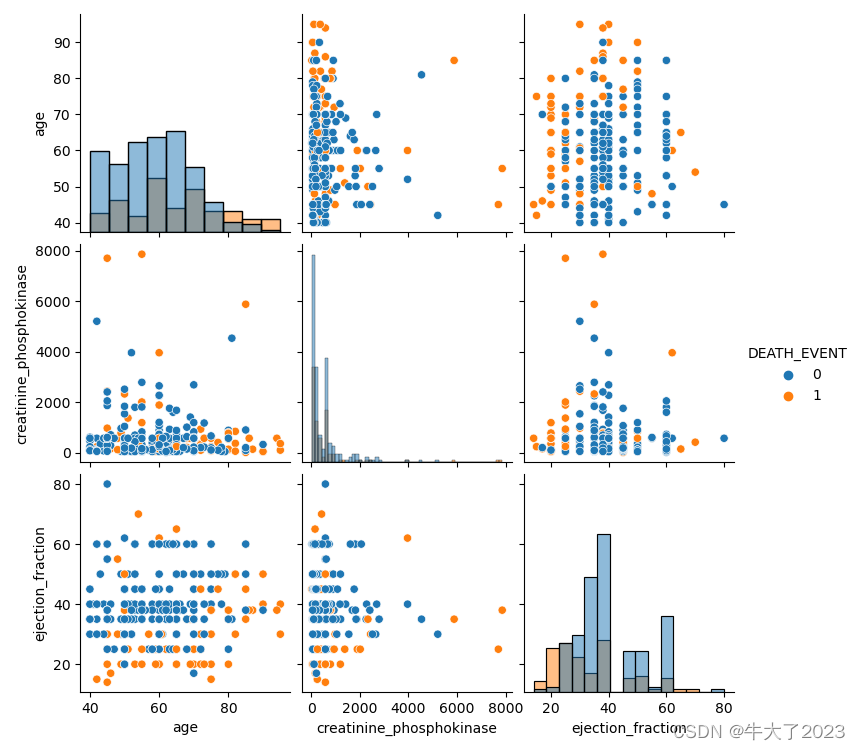
从上图可以发现,在2D情况下不同的特征组合对于心脏病人是否死亡的散点分布,以及大概的区分能力。我认为ejection_fraction与其他特征的组合更具有区分能力(不太会看其实)
for col in data[numerical_features].columns:if col != 'DEATH_EVENT':sns.boxplot(x='DEATH_EVENT', y=col, saturation=0.5, palette='pastel', data=data)plt.title(col)plt.show()
打印箱型图
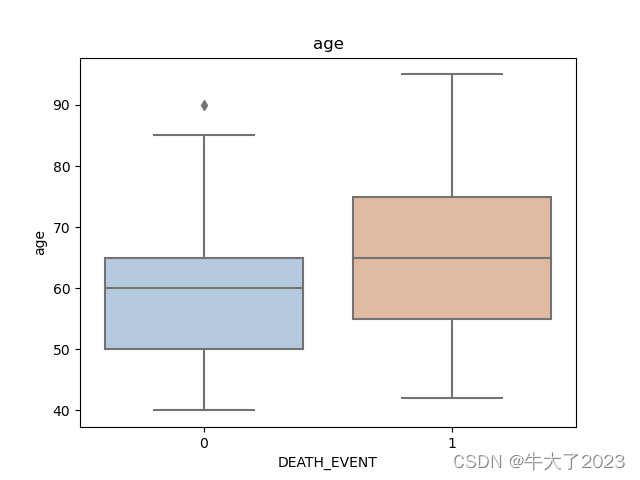
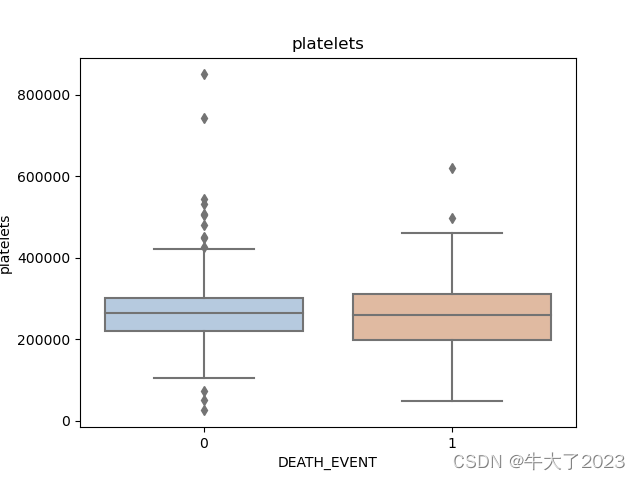
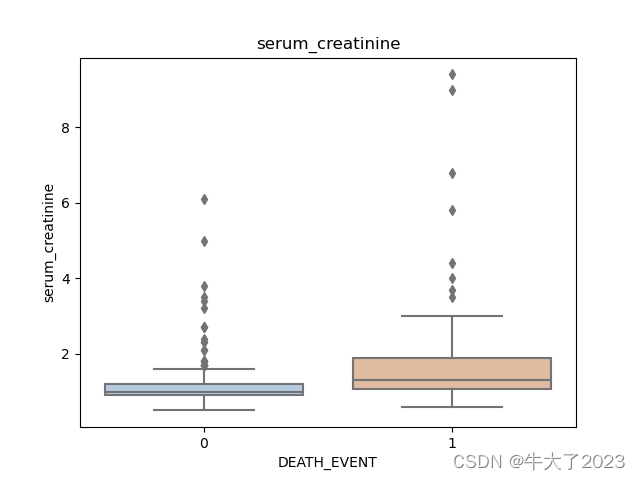
可以得到不同类别在不同特征上的分布差异情况。
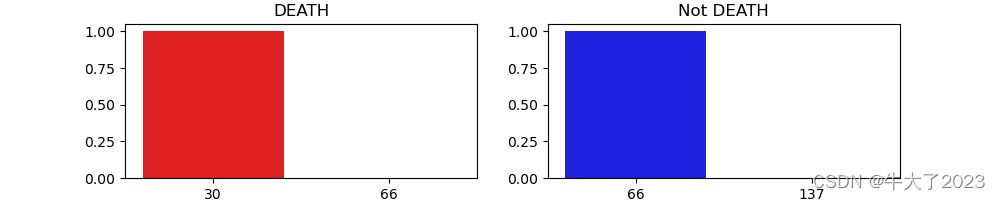
可以进行数据分析,比如分析吸烟与死亡的关系
tlog = {}
for i in category_features:tlog[i] = data[data['DEATH_EVENT'] == 1][i].dropna().value_counts()flog = {}
for i in category_features:flog[i] = data[data['DEATH_EVENT'] == 0][i].dropna().value_counts()plt.figure(figsize=(10,2))
plt.subplot(1,2,1)
plt.title('DEATH')
sns.barplot(x = pd.DataFrame(tlog['smoking'][:2]).sort_index()['smoking'], y = pd.DataFrame(tlog['smoking'][:2]).sort_index().index, color = "red")
plt.subplot(1,2,2)
plt.title('Not DEATH')
sns.barplot(x = pd.DataFrame(flog['smoking'][:2]).sort_index()['smoking'], y = pd.DataFrame(flog['smoking'][:2]).sort_index().index, color = "blue")
plt.show()
5.对离散变量进行编码
由于XGBoost无法处理字符串类型的数据,我们需要一些方法讲字符串数据转化为数据。一种最简单的方法是把所有的相同类别的特征编码成同一个值,例如女=0,男=1,狗狗=2,所以最后编码的特征值是在[0,特征数量−1]之间的整数。除此之外,还有独热编码、求和编码、留一法编码等等方法可以获得更好的效果。
代码如下,但本文用的心脏病数据集都是整形和浮点型,因此不用处理。
## 把所有的相同类别的特征编码为同一个值
def get_mapfunction(x):mapp = dict(zip(x.unique().tolist(),range(len(x.unique().tolist()))))def mapfunction(y):if y in mapp:return mapp[y]else:return -1return mapfunction
for i in category_features:data[i] = data[i].apply(get_mapfunction(data[i]))6.模型训练与预测
## 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。
from sklearn.model_selection import train_test_split## 选择其类别为0和1的样本 (不包括类别为2的样本)
data_target_part = data['RainTomorrow']
data_features_part = data[[x for x in data.columns if x != 'RainTomorrow']]## 测试集大小为20%, 80%/20%分
x_train, x_test, y_train, y_test = train_test_split(data_features_part, data_target_part, test_size = 0.2, random_state = 2020)
#查看标签数据
print(y_train[0:2],y_test[0:2])# 打印修改后的结果
print(y_train[0:2],y_test[0:2])
导入XGBoost模型
## 导入XGBoost模型
from xgboost.sklearn import XGBClassifier
## 定义 XGBoost模型
clf = XGBClassifier(use_label_encoder=False)
# 在训练集上训练XGBoost模型
clf.fit(x_train, y_train)
注意:控制台导入下载的时候要关掉梯子!
否则就有这种报错:WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ProxyError('Cannot connect to proxy.', timeout('_ssl.c:1112: The handshake operation timed out'))': /pypi/web/simple/xgboost/
## 在训练集和测试集上分布利用训练好的模型进行预测
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
from sklearn import metrics## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict))
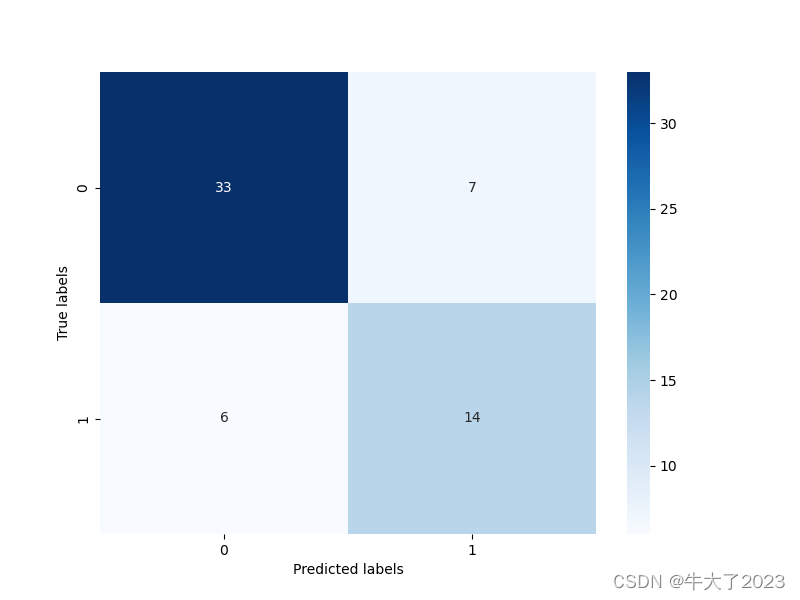
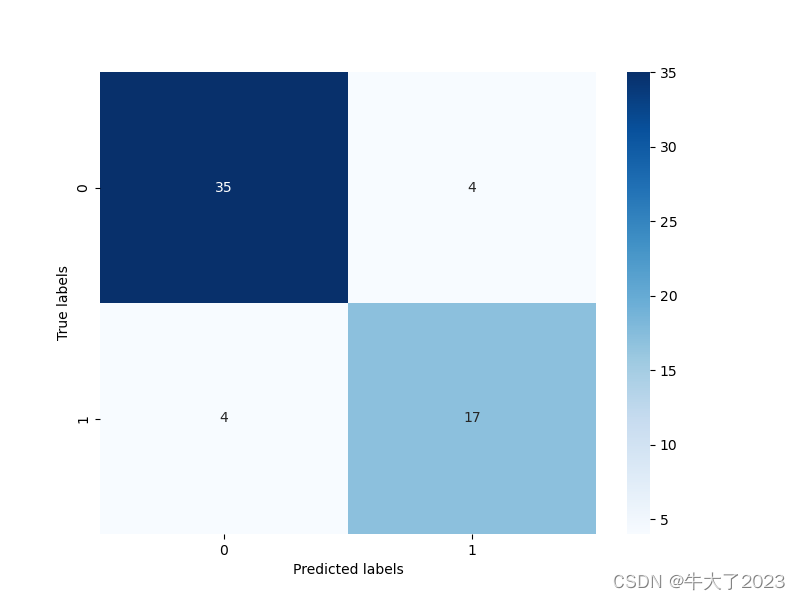
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict))## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()

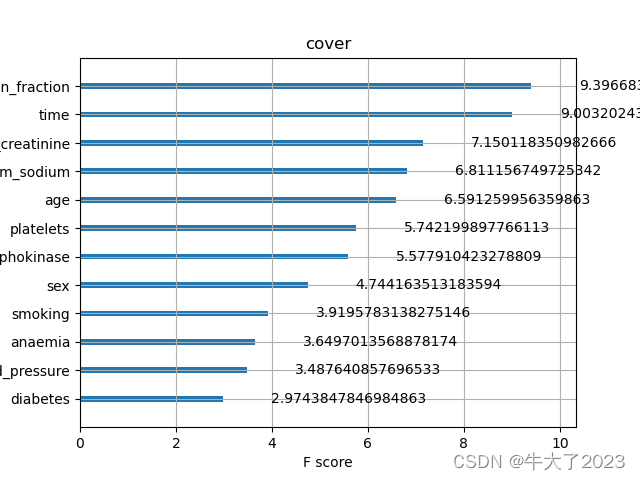
7.特征选择
XGBoost的特征选择属于特征选择中的嵌入式方法,在XGboost中可以用属性feature_importances_去查看特征的重要度。
plt.figure(figsize=(8, 6))
sns.barplot(y=data_features_part.columns, x=clf.feature_importances_)
plt.show()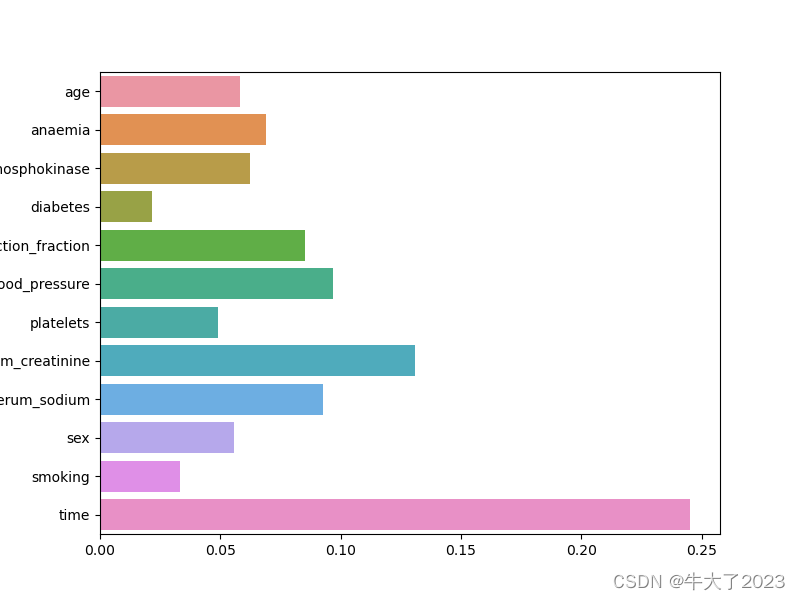
从图中我们可以发现得病时间是决定是否死亡最重要的因素。
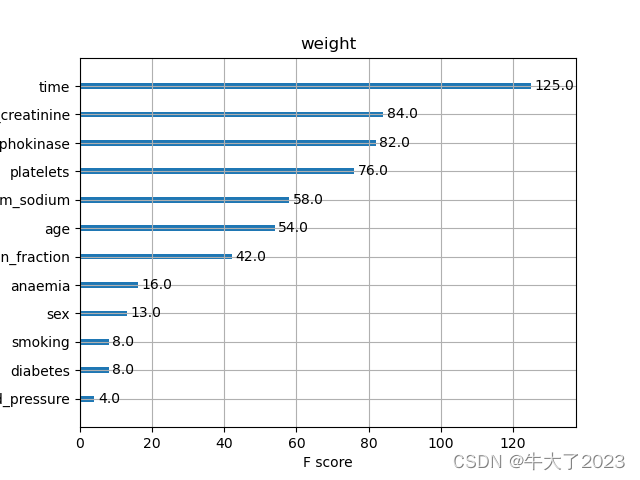
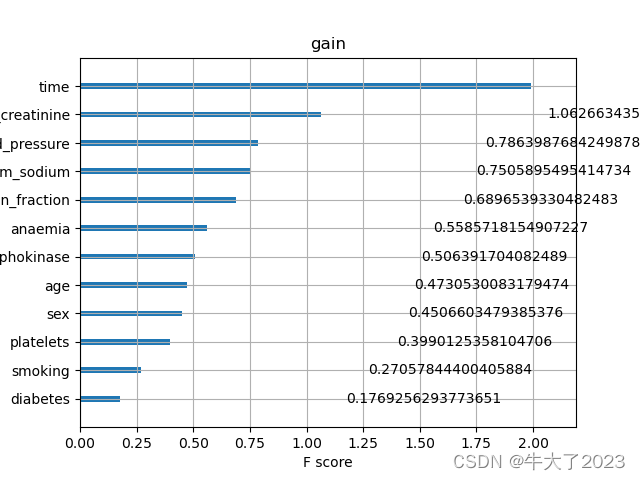
初次之外,我们还可以使用XGBoost中的下列重要属性来评估特征的重要性。
- weight:是以特征用到的次数来评价
- gain:当利用特征做划分的时候的评价基尼指数
- cover:利用一个覆盖样本的指标二阶导数(具体原理不清楚有待探究)平均值来划分。
- total_gain:总基尼指数
- total_cover:总覆盖
acc= 0.7833333333333333
这些图同样可以帮助我们更好的了解其他重要特征。
8.通过调整参数获得更好的效果
以下是几个重要的参数
1. learning_rate: 有时也叫作eta,系统默认值为0.3。每一步迭代的步长,很重要。太大了运行准确率不高,太小了运行速度慢。
2. subsample:系统默认为1。这个参数控制对于每棵树,随机采样的比例。减小这个参数的值,算法会更加保守,避免过拟合, 取值范围零到一。
3. colsample_bytree:系统默认值为1。我们一般设置成0.8左右。用来控制每棵随机采样的列数的占比(每一列是一个特征)。
4. max_depth: 系统默认值为6,我们常用3-10之间的数字。这个值为树的最大深度。这个值是用来控制过拟合的。max_depth越大,模型学习的更加具体。
核心参数调优
1.eta[默认0.3]
通过为每一颗树增加权重,提高模型的鲁棒性。
典型值为0.01-0.2。2.min_child_weight[默认1]
决定最小叶子节点样本权重和。
这个参数可以避免过拟合。当它的值较大时,可以避免模型学习到局部的特殊样本。
但是如果这个值过高,则会导致模型拟合不充分。3.max_depth[默认6]
这个值也是用来避免过拟合的。max_depth越大,模型会学到更具体更局部的样本。
典型值:3-104.max_leaf_nodes
树上最大的节点或叶子的数量。
可以替代max_depth的作用。
这个参数的定义会导致忽略max_depth参数。5.gamma[默认0]
在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。Gamma指定了节点分裂所需的最小损失函数下降值。
这个参数的值越大,算法越保守。这个参数的值和损失函数息息相关。6.max_delta_step[默认0]
这参数限制每棵树权重改变的最大步长。如果这个参数的值为0,那就意味着没有约束。如果它被赋予了某个正值,那么它会让这个算法更加保守。
但是当各类别的样本十分不平衡时,它对分类问题是很有帮助的。7.subsample[默认1]
这个参数控制对于每棵树,随机采样的比例。
减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。
典型值:0.5-18.colsample_bytree[默认1]
用来控制每棵随机采样的列数的占比(每一列是一个特征)。
典型值:0.5-19.colsample_bylevel[默认1]
用来控制树的每一级的每一次分裂,对列数的采样的占比。
subsample参数和colsample_bytree参数可以起到相同的作用,一般用不到。10.lambda[默认1]
权重的L2正则化项。(和Ridge regression类似)。
这个参数是用来控制XGBoost的正则化部分的。虽然大部分数据科学家很少用到这个参数,但是这个参数在减少过拟合上还是可以挖掘出更多用处的。11.alpha[默认1]
权重的L1正则化项。(和Lasso regression类似)。
可以应用在很高维度的情况下,使得算法的速度更快。12.scale_pos_weight[默认1]
在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。
网格调参法
调节模型参数的方法有贪心算法、网格调参、贝叶斯调参等。这里我们采用网格调参,它的基本思想是穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果
## 从sklearn库中导入网格调参函数
from sklearn.model_selection import GridSearchCV## 定义参数取值范围
learning_rate = [0.1, 0.3,]
subsample = [0.8]
colsample_bytree = [0.6, 0.8]
max_depth = [3,5]parameters = { 'learning_rate': learning_rate,'subsample': subsample,'colsample_bytree':colsample_bytree,'max_depth': max_depth}
model = XGBClassifier(n_estimators = 20)## 进行网格搜索
clf = GridSearchCV(model, parameters, cv=3, scoring='accuracy',verbose=1,n_jobs=-1)clf = clf.fit(x_train, y_train)
## 在训练集和测试集上分布利用最好的模型参数进行预测## 定义带参数的 XGBoost模型
clf = XGBClassifier(colsample_bytree = 0.6, learning_rate = 0.3, max_depth= 8, subsample = 0.9)
# 在训练集上训练XGBoost模型
clf.fit(x_train, y_train)train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict))## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
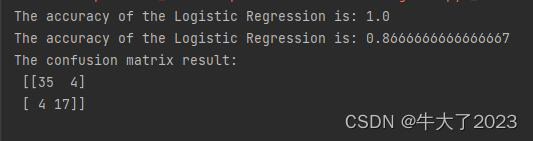
更多调参技巧请参考:【机器学习笔记】【随机森林】【乳腺癌数据上的调参】_n_estimators_桜キャンドル淵的博客-CSDN博客
原文:A.机器学习入门算法(六)基于天气数据集的XGBoost分类预测_汀、人工智能的博客-CSDN博客
这篇关于机器学习:基于心脏病数据集的XGBoost分类预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




