本文主要是介绍PieCloudDB Database 3.0 正式发布丨数仓虚拟化流转数据要素,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
3月14日,拓数派 2024 年度战略暨新产品发布会在上海国际会议中心成功举行。本次大会的主题为「数仓虚拟化 流转数据要素」,吸引了众多业内资深专家和合作伙伴参与,共同探讨数据要素流转和数字技术创新等热门话题。
拓数派创始人兼 CEO 冯雷(Ray Von)携产品团队重磅发布了备受期待的云原生虚拟数仓 PieCloudDB Database 3.0 版本,并分享了数仓虚拟化技术的最新成果和在数据要素产业中的最佳实践。 发布会详情请参考官方新闻。

PieCloudDB 3.0 发布仪式
拓数派创始人兼 CEO 冯雷(Ray Von)在发布会环节分享了公司 2024 年度在数据领域的战略布局:聚焦云原生虚拟数仓引擎,为数据要素价值释放保驾护航。PieCloudDB 采用首创数仓虚拟化技术,在私有/公有云里打造了元数据、数据资产(存储)、计算分离的 eMPP(elastic MPP)架构,能够消除当下传统方案在数据隐私、灵活性和大模型计算延展性等方面存在的挑战,从底层结构上消除结构化数据孤岛,在更大范围内支持数据要素流转,真正实现数据「可用不可见」,让模型更大更快更准,并达到「数据入库不出户:不跑数据,跑计算」的安全状态。
PieCloudDB 内核技术持续突破,进行再一次升级,正式发布 3.0 版本。在这一新版本中,PieCloudDB 在存储、元数据、执行器等各个模块均进行了大量升级。
简墨:自研的数据存储底座
拓数派自研的简墨存储,其目标是利用云原生的设计与现代化的硬件和设施,打造满足不同云场景下的高性能计算系统的数据存储底座。
在大数据时代,数据以特定格式的文件形式存储,各大数据厂商对存储格式和组织形式都进行了深入的创新。拓数派为了追求极致的性能、获取更灵活的数据单元、构建基于文件的统计信息、并紧密支持文件级别的查询优化和上层特性,自研了全新的存储格式 janm。在 PieCloudDB 最新版本,janm 与开源存储格式 parquet 的初步性能对比中,可以看到 janm 在多个方面均比 parquet 有了倍数级的提升。
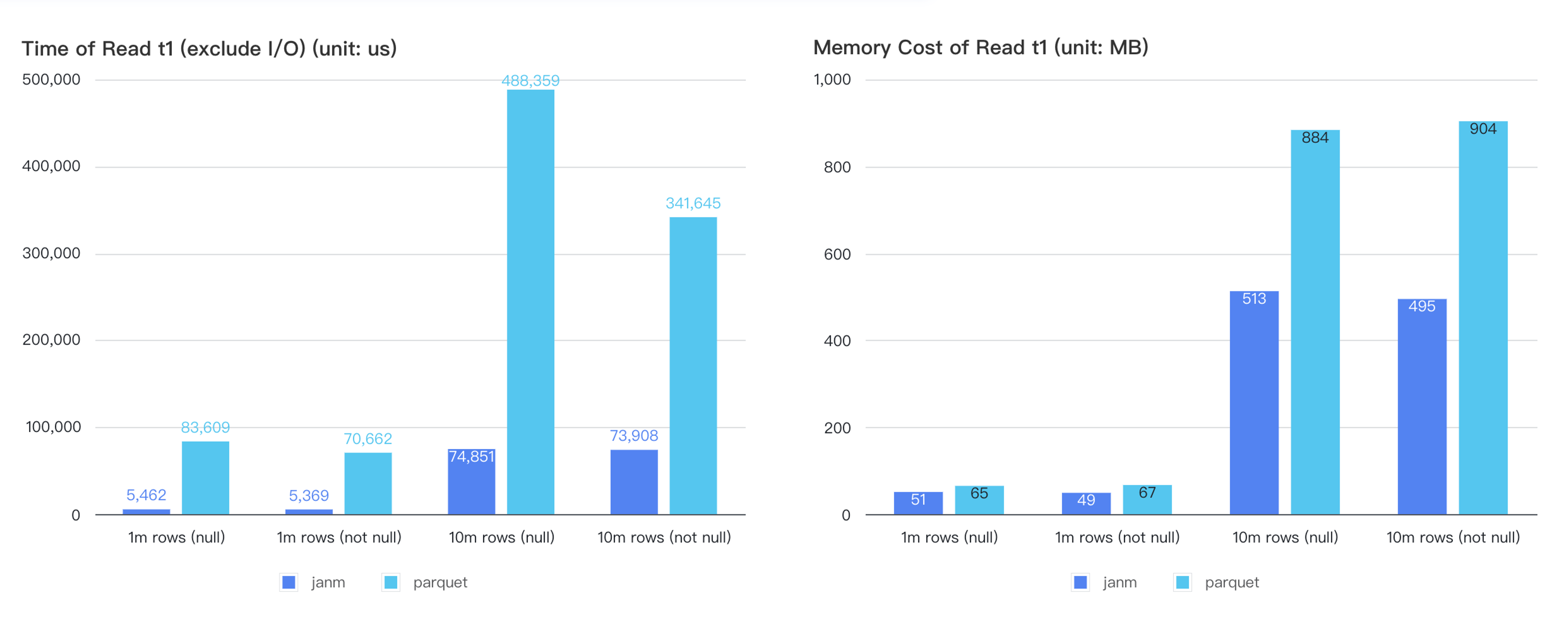
janm 与 parquet 文件格式的初步性能对比
此外,为了简化大数据时代数据处理的各个流程,简墨对数据文件进行了更高效的组织。简墨也考虑到云原生的设计和弹性的支持,来避免全局有序,让数据组织更加简单、减少数据移动,提高效率,支持分布式计算,避免数据倾斜,并适用于多集群,可完美支持弹性和最大化集群资源利用率。
简墨会定期自动对数据文件进行自适应管理,快速筛选出需要进行 recluster 的文件,增量式的将数据根据索引列将数据快速聚集到新的文件中。并支持利用数据文件建立新的索引形式来进一步提升对索引列的点查性能。
新一代向量化执行引擎
PieCloudDB 新一代向量化执行器采用插件化执行方式,可根据代价(cost)自适应选择执行引擎,自动匹配最优的执行引擎。执行引擎基于高效内存列存格式,高效转换行列混存的 janm 存储格式到内存中。并支持现有绝大部分类型,做到完备的进行函数处理。
目前,PieCloudDB 向量化执行器已完成 sort, agg, join, scan, motion, filter 等大部分算子的改造,并将在 Runtime filter、低基数等其他优化算法上继续优化。如今,PieCloudDB 向量化执行器已在业内常用的决策支持基准测试 TPC-H 中展现了令人瞩目的性能提升。此外,执行器还搭配上 trace 系统,做到查询可视化和查询链路可追踪。
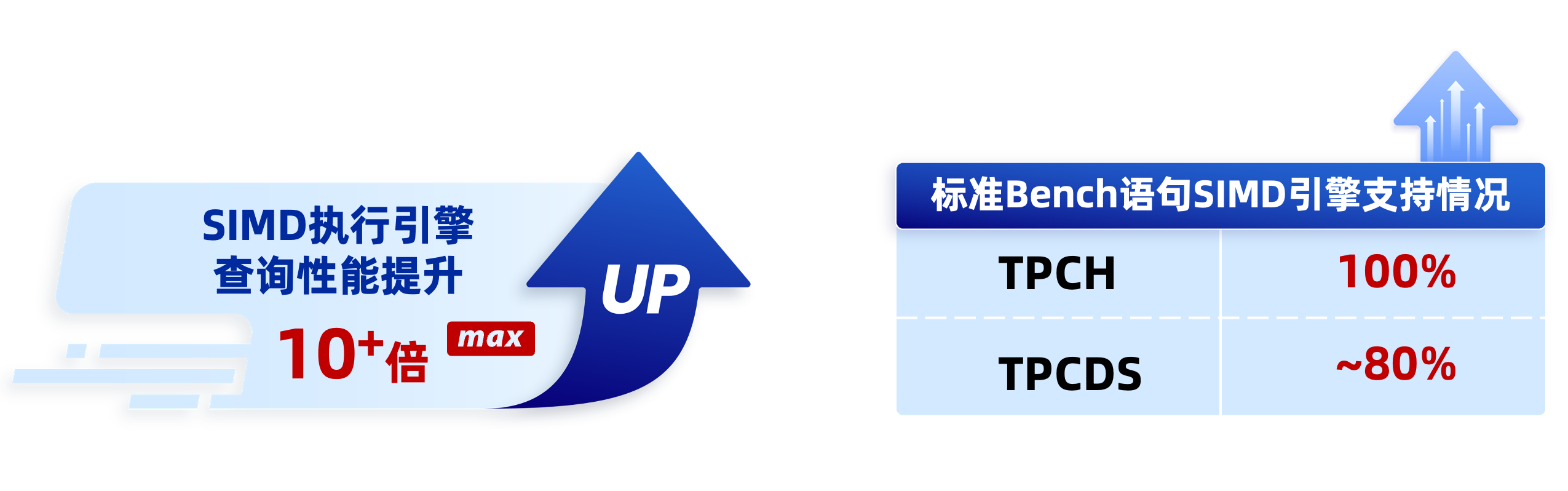
SIMD 执行引擎性能提升
PieCloudDB 向量化执行器将不断迭代,并在不久的未来在 pipeline、Serverless、软硬结合、调度方面有更多的提升。
木牍:下一代元数据管理系统
PieCloudDB 原有的元数据管理系统将元数据进行分离,采用开源 KV 数据库 FoundationDB 来存储元数据、事务和锁数据,并利用全局缓存系统 GMEMOS 来缓存元数据、事务 ID 和快照等数据。原有的系统中,元数据被持久化存储,可支持多集群多租户等特性。
为了能够进一步对齐 πDataCS「一份存储,多引擎计算」的使命,PieCloudDB 进一步演进,打造了下一代元数据管理系统木牍。新一代的元数据管理系统全自研打造,可进一步释放 PieCloudDB 存算分离架构的优势,在数据要素流转中发挥更大的价值。
对比上一代元数据管理系统,木牍性能达到倍数级提升,整体 DDL 性能上升了 40 多倍,DML 元数据查询延迟降低了 60%,并发连接数提升达 20+ 倍。

对比上一代 Mstore 的性能提升
架构上,新一代元数据管理系统木牍使用全新设计的 M(meta)节点替换了 FoundataionDB,采用全模块化设计,具备更高的性能。并完全兼容 PostgreSQL 生态的各类工具,更加开放包容。
M 节点被用来统一管理元数据和 PieCloudDB 状态信息,接入了简墨存储底座,所有存储统一化,用于存储 catalog 数据。打造了独立的锁、事务和快照管理器,进一步提高并发性能。此外,木牍支持高可用和增量备份,统一缓存支持多个集群使用,并支持执行器直接查询元数据和事务信息,减少执行器查询延迟,降低系统负载。
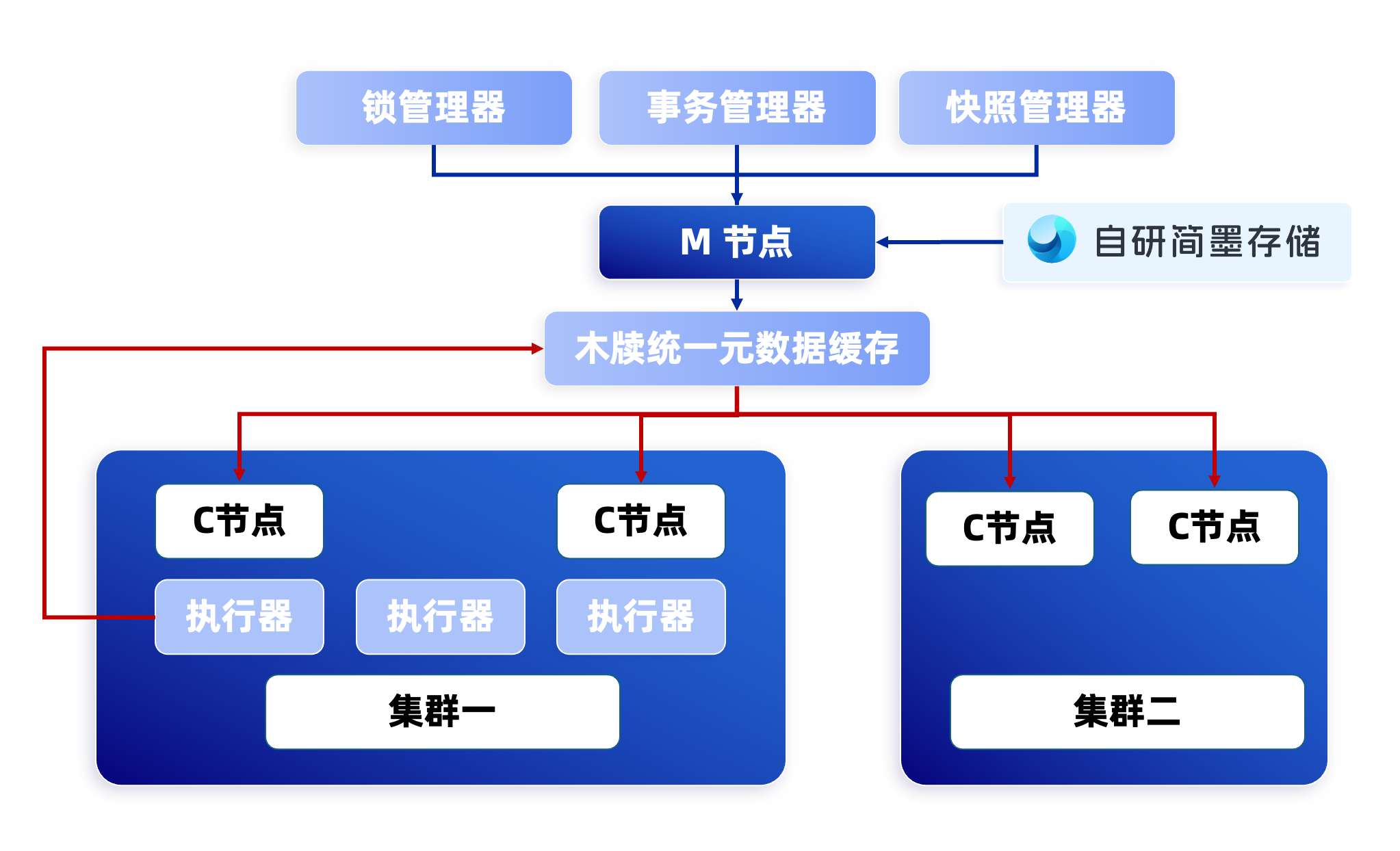
木牍元数据管理系统架构
而木牍的协调节点(C节点)负责将查询分发至执行器,从元数据缓存收集所需要的信息。简化了原有 QD 的功能,降低了主节点的负载。
生态和平台演进
除了存储底座、元数据管理系统和执行器模块的迭代,PieCloudDB 生态和平台也发布了大量功能和更新,包括:
- 开源表格式 Iceberg 查询
- csv, json, parquet, orc 文件可做直接 SQL 查询
- PieCloudVector 的增强(性能、HA、GPU)
- Flink Connector
- Spark Connector
- 数据源一致性校验
- 全链路 arm 支持
- 数据库系统、查询更完备的可视化检测
…
未来,拓数派将持续深入探索数据领域,加强核心技术攻关能力,与行业与生态伙伴紧密合作,共同探索数据要素产业的最佳实践。通过产品的不断创新,期待为客户提供更强大、可靠的数据技术支持。
这篇关于PieCloudDB Database 3.0 正式发布丨数仓虚拟化流转数据要素的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








