本文主要是介绍李宏毅学习笔记14.ELMO、BERT、GPT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 之前的做法
- 独热编码
- Word Class
- Word Embedding
- 缺点
- 一词多义
- Embeddings from Language Model(ELMO)
- Bidirectional Encoder Representations from Transformers
- Training of BERT
- Approach 1:MaskedLM
- Approach 2:Next Sentence Prediction
- How to use BERT
- Case 1
- Case 2
- Case 3
- Case 4
- Enhanced Representation through Knowledge Integration(ERNIE)
- BERT 结果分析
- Generative Pre-Training(GPT)
前言
这块内容也是2020版新加的内容,比较新。
Putting Words into Computers
Introduction of ELMO,BERT,GPT
本节内容是如何在电脑上表示(或是说让电脑理解)人类的文字。
之前的做法
独热编码
缺点:词汇之前没有关联。

Word Class
缺点:太粗糙,同样无法表达猫狗走兽和飞鸟的区别。

Word Embedding

这样的表示可以用于很多方面:

缺点
一词多义
A word can have multiple senses.
Have you paid that money to the bank yet?
It is safest to deposit your money in the bank.
The victim was found lying dead on the river bank.
They stood on the river bank to fish.
The four word tokens have the same word type.
In typical word embedding,each word type has an embedding.
第一句和第二句都是银行,第三句和第四句一样
但是语义是非常丰富的,例如:
The hospital has its own blood bank.
这里还是不是银行的意思?

应该用上下文词向量来解决这个问题:
Contextualized Word Embedding
· Each word token has its ownembedding(even though it has the same word type)
· The embeddings of word tokens also depend on its context.

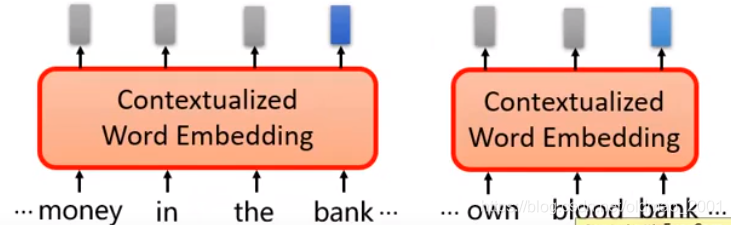
尽管下面两个bank的意思会不一样,但是在向量表示上应该比较相近。解决这个问题就是ELMO了:
Embeddings from Language Model(ELMO)
ELMO是芝麻街动画片的人物名

https://arxiv.org/abs/1802.05365
RNN-based language models (trained from lots of sentences)不需要标签就可以训练,只要有句子就可以:

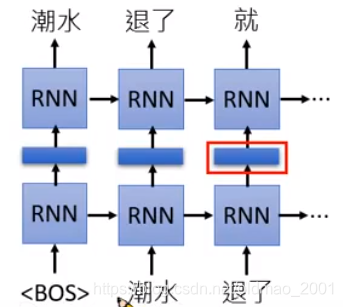
红色框部分就是上下文相关的词向量表示。当上下文不一样,这里的结果也会不一样:
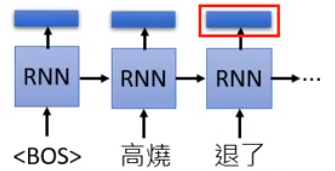
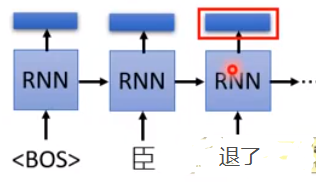
上面的例子只学习了上文,要看下文就要训练一个反向的RNN
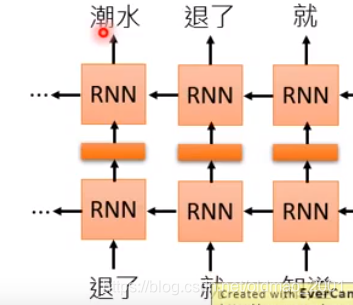
然后把前向和后向的结果concat起来即可
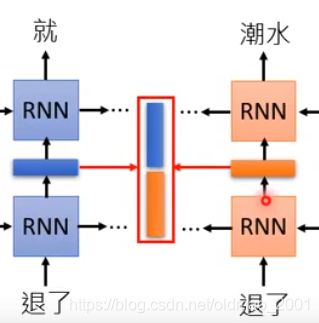
除了前向和后向之外,还可做deep

每层都有输出向量表示,ELMO是所有的隐藏层表示都要。这里不是简单的concat,而是做加权
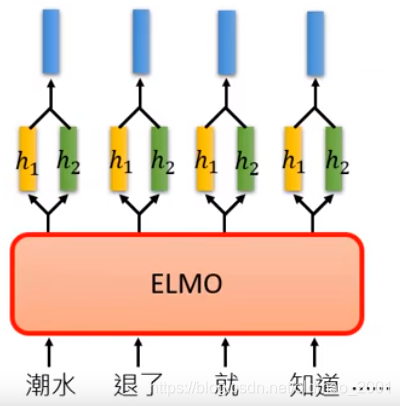
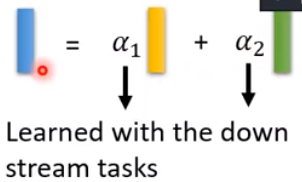
这里的 α 1 , α 2 \alpha_1,\alpha_2 α1,α2是参数,是结合具体的下游任务学出来的(不同任务参数还不一样)。
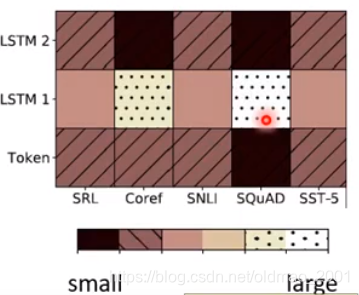
上面是ELMO的结果,可以看到Token是没有加上下文的表示,LSTM 1表示通过第一层得到向量表示,LSTM 2是表示通过第二层得到的向量表示,下面是不同下游任务。可以看到不同任务权重不太一样。
Bidirectional Encoder Representations from Transformers
BERT是芝麻街动画片的人物名

·BERT=Encoder of Transformer
Learned from a large amount of text without annotation(和ELMO一样)

中文的话,用字比用词效果要好。
Training of BERT
Approach 1:MaskedLM
把15%的词替换为特殊的token(挖洞),然后让BERT把坑填回来。Predicting the
masked word。
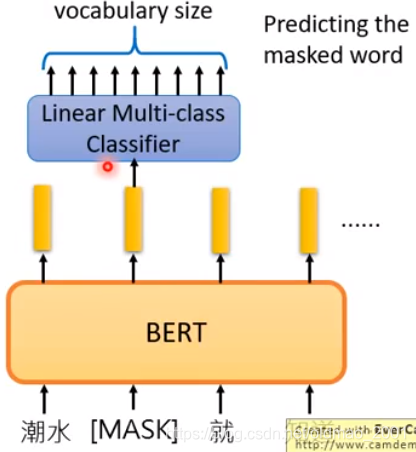
如果两个词填在同一个地方没有违和感那它就有类似的embedding
Approach 2:Next Sentence Prediction
[SEP]:the boundary of two sentences
[CLS]:the position that outputs classification results
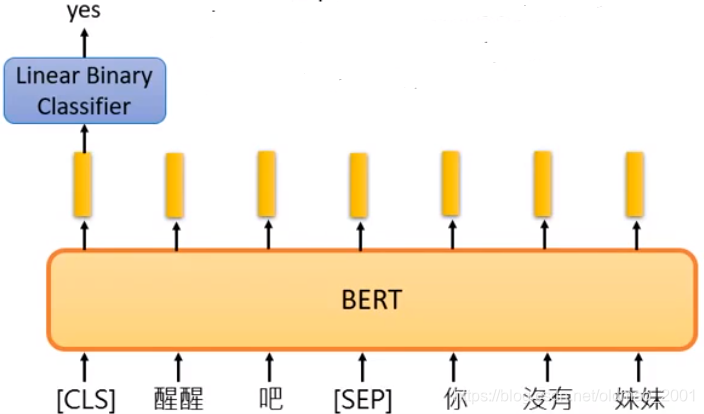
Approaches 1 and 2 are used at the same time.
How to use BERT
训练BERT后不但可以获得词向量表示,由于训练BERT一般和下游任务模型一起训练,所以还会获得别的信息,下面看四种使用BERT的方法。
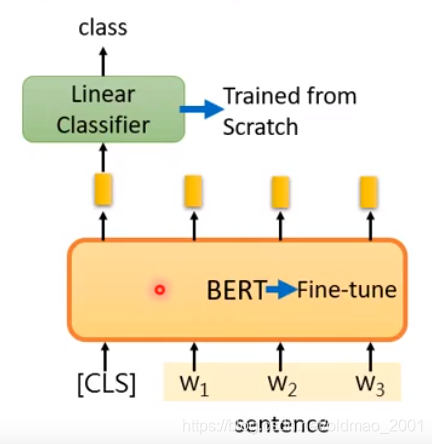
Case 1
Input:single sentence.
output:class
Example: Sentiment analysis, Document Classification
在这里,Linear Classifier的参数是重头学习,BERT是微调。
Case 2

Input:single sentence
output:class of each word
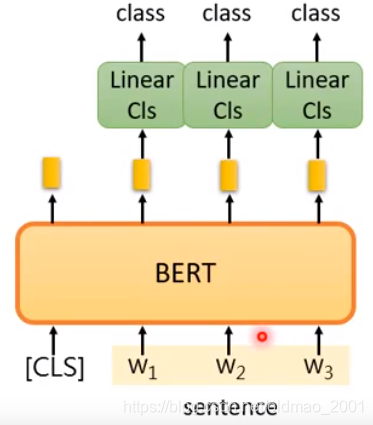
Case 3
Input:two sentences
output:class
Example:Natural Language Inference
Given a"premise", determining whether a"hypothesis"is T/F/unknown.
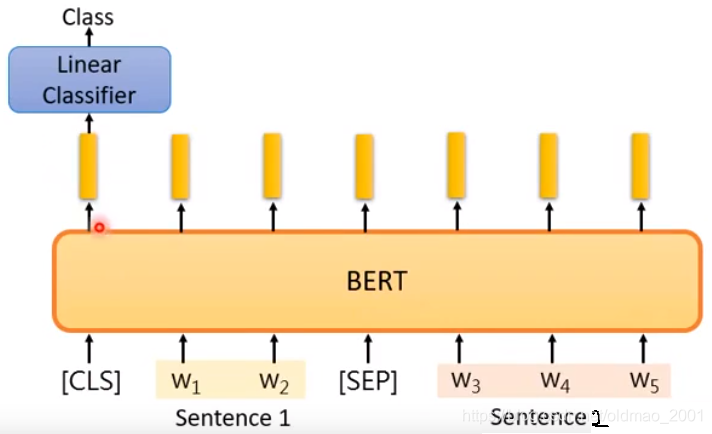
Case 4
阅读理解
Extraction-based Question Answering(QA)(E.g. SQuAD)
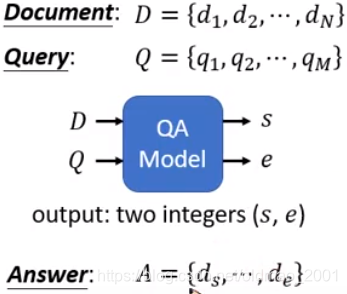
这里的Answer中的 d s , d e d_s,d_e ds,de代表回答的起始词和结束词。

模型具体如下图:
红色向量和蓝色向量分别代表起始词和结束词,两个向量的维度和下面BERT输出的词向量维度一样。
先确定起始词
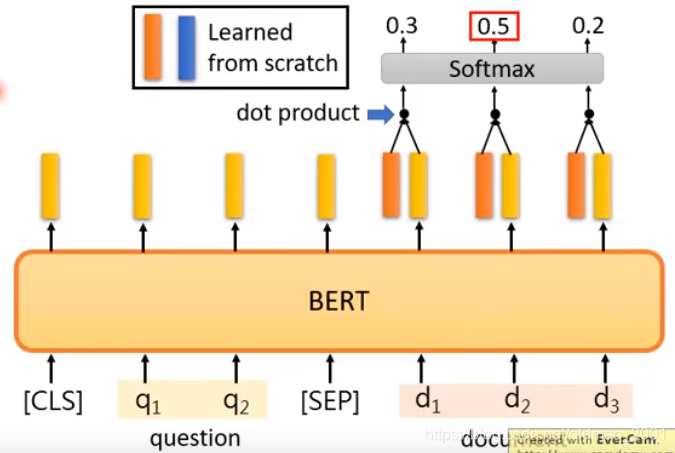
可以看到s=2
再确定结束词:
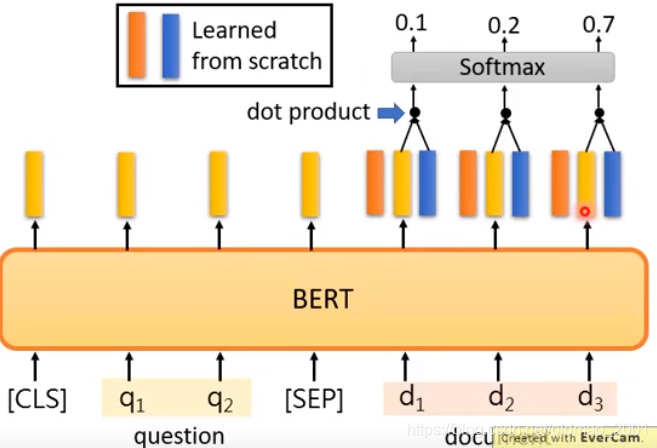
可以看到e=3,所以答案是: d 2 d 3 d_2d_3 d2d3
Enhanced Representation through Knowledge Integration(ERNIE)
ERNIE也来自芝麻街。。。而且还和BERT还是好朋友
整个模型专门用于中文。

因为用BERT来做的时候,只猜单个字太简单,于是有了ERNIE来猜整个词的。

BERT 结果分析
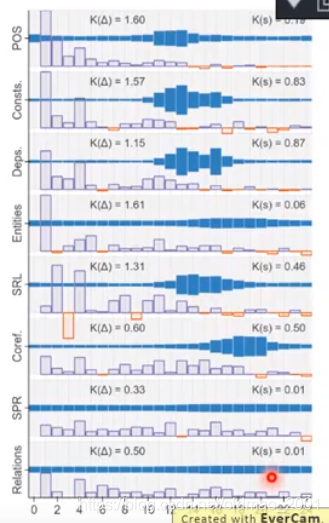
这里竖向是一个个NLP任务,然后横着的是通过BERT和对应任务进行联动训练以后,把BERT的24层每个单独抽取出来,进行加权相加(和ELMO一样的操作)得到的结果,可以看到各个NLP任务对应的BERT层有哪些最敏感,例如最上面的POS(词性分析)第11到13层的向量贡献最大。
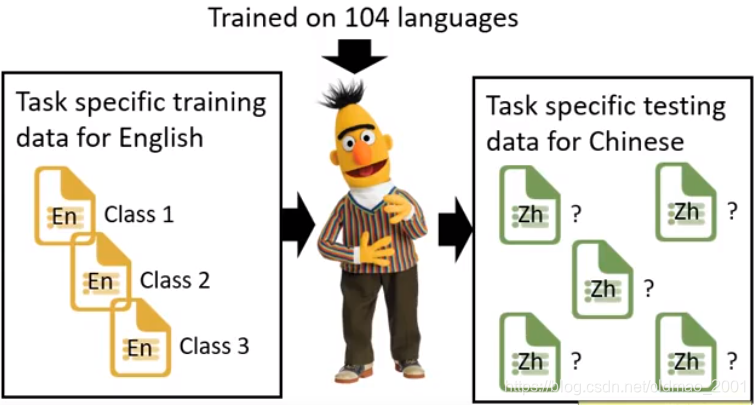
BERT还有一个很牛的地方,在英文上训练,可以在中文上做应用。(Multilingual BERT)
Generative Pre-Training(GPT)
GPT是一个非常非常非常大的一个语言模型,看下参数量体会:

GPT是一个独角兽。
BERT是transformer的encoder,GPT是transformer的decoder部分。
下面看大概的运行过程。里面涉及到self-attention操作。

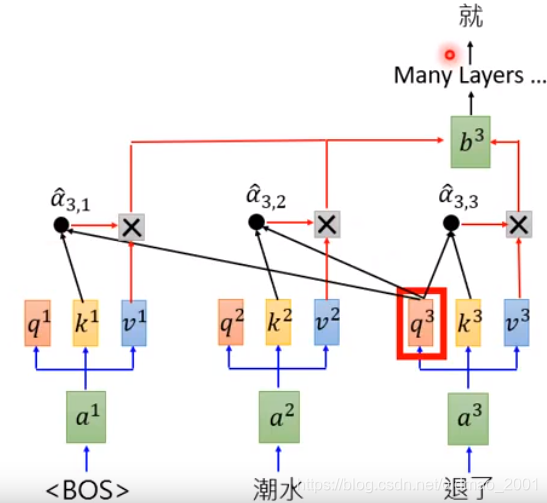
不断往下循环。
GPT很大,很神奇:
Zero-shot Learning:在没有训练的情况下GPT就可以做Reading Comprehension,Summarization,Translation
从可视化上面看,GPT貌似默认就会attention到第一个词。
这篇关于李宏毅学习笔记14.ELMO、BERT、GPT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





