本文主要是介绍KNN算法对鸢尾花进行分类:添加网格搜索和交叉验证,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
优化——添加网格搜索和交叉验证
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
#KNN算法对鸢尾花进行分类:添加网格搜索和交叉验证#1、获取数据
iris = load_iris()
#2、数据集划分
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,random_state = 22)
#3、特征工程——标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
#4、KNN算法预估器
estimator = KNeighborsClassifier()#加入网格搜索和交叉验证
#参数准备
param_dict = {"n_neighbors":[1,3,5,7,9,11]}
estimator = GridSearchCV(estimator,param_grid = param_dict,cv=10)estimator.fit(x_train,y_train)
#5、模型评估
#方法一:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
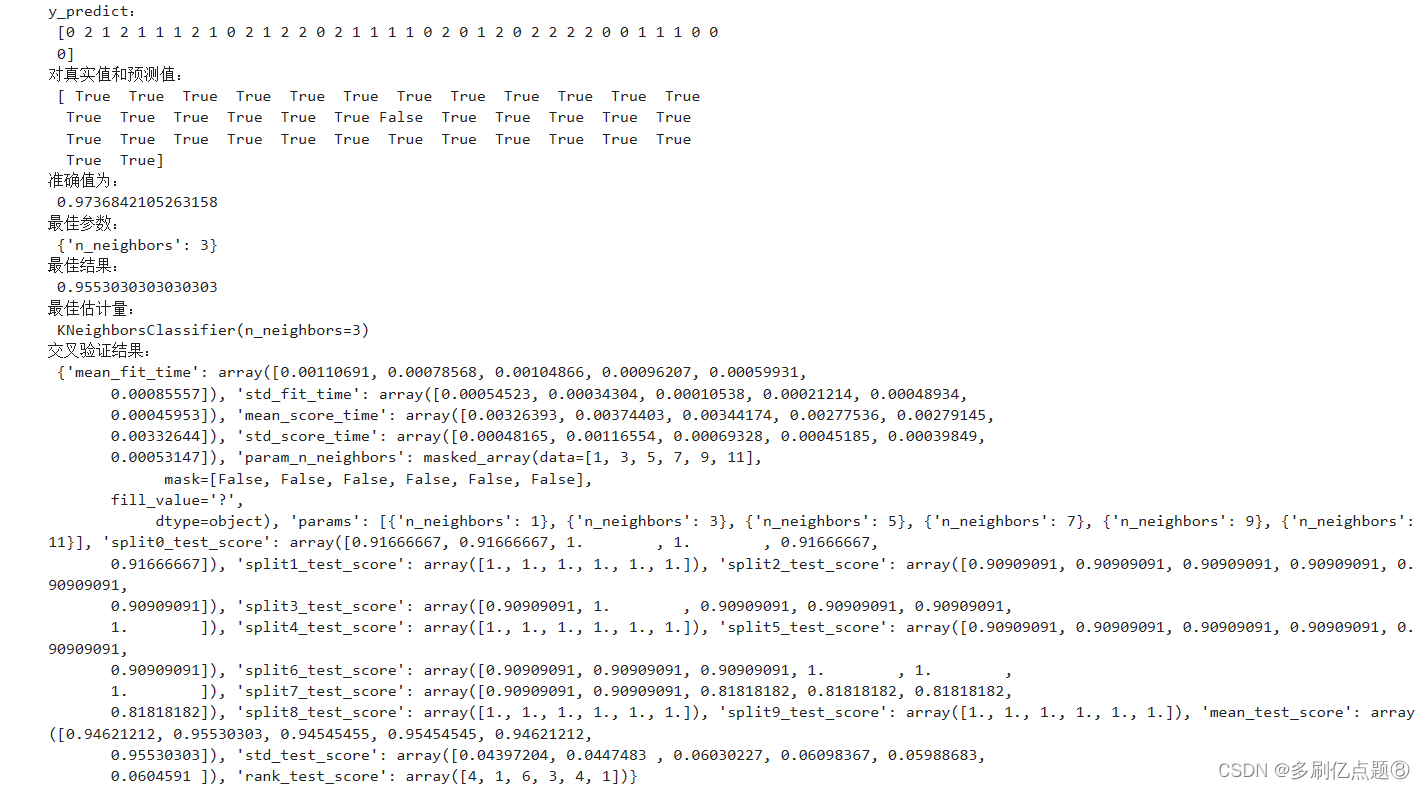
print("y_predict:\n",y_predict)
print("对真实值和预测值:\n",y_test == y_predict)
#方法二:计算准确率
score = estimator.score(x_test,y_test)
print("准确值为:\n",score)#最佳参数best_params_
print("最佳参数:\n",estimator.best_params_)
#最佳结果best_score_
print("最佳结果:\n",estimator.best_score_)
#最佳估计量best_estimator_
print("最佳估计量:\n",estimator.best_estimator_)
#交叉验证结果
print("交叉验证结果:\n",estimator.cv_results_)
这篇关于KNN算法对鸢尾花进行分类:添加网格搜索和交叉验证的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




