本文主要是介绍基于InceptionV2/InceptionV3/Xception不同参数量级模型开发构建中草药图像识别分析系统,实验量化对比不同模型性能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近正好项目中在做一些识别相关的内容,我也陆陆续续写了一些实验性质的博文用于对自己使用过的模型进行真实数据的评测对比分析,感兴趣的话可以自行移步阅读即可:
《移动端轻量级模型开发谁更胜一筹,efficientnet、mobilenetv2、mobilenetv3、ghostnet、mnasnet、shufflenetv2驾驶危险行为识别模型对比开发测试》
《图像识别模型哪家强?19款经典CNN模型实践出真知【以眼疾识别数据为基准,对比MobileNet系列/EfficientNet系列/VGG系列/ResNet系列/i、xception系列】》
《基于轻量级卷积神经网络模型实践Fruits360果蔬识别——自主构建CNN模型、轻量化改造设计lenet、alexnet、vgg16、vgg19和mobilenet共六种CNN模型实验对比分析》
《基于轻量级模型GHoshNet开发构建眼球眼疾识别分析系统,构建全方位多层次参数对比分析实验》
本文紧接前面三篇测评分析博文:
《基于EfficientNet(B0-B7)全系列不同参数量级模型开发构建中草药图像识别分析系统,实验量化对比不同模型性能》
《基于MobileNet(v1-v3)全系列不同参数量级模型开发构建中草药图像识别分析系统,实验量化对比不同模型性能》
《基于VGG(vgg13/vgg16)/ResNet(resnet34/resnet50)不同参数量级模型开发构建中草药图像识别分析系统,实验量化对比不同模型性能》
前面两篇测评分析的博文主要是使用EfficientNet全系列网络模型和MobileNet全系列模型来开发构建的对比实验,相较之下都偏向于轻量级的网络模型,第三篇博文则选择的是在“重量级”领域里面比较经典的VGG和ResNet模型,本文选择的Inception和Xception系列的模型则是介于轻量级网络模型和重量级网络模型之间的体量,实验同样是以基准数据集【中草药图像数据集】为例,开发构建不同参数量级的模型,之后在同样的测试数据集上进行评测对比分析。
数据集中共包含23种类别数据,清单如下:
aiye
baibiandou
baibu
baidoukou
baihe
cangzhu
cansha
dangshen
ezhu
foshou
gancao
gouqi
honghua
hongteng
huaihua
jiangcan
jingjie
jinyinhua
mudanpi
niubangzi
zhuling
zhuru
zhuye
zicao简单看下部分数据实例:


Inception模型是一种深度卷积神经网络,其核心思想是通过增加网络深度与宽度并减少参数的方法解决问题,并提高模型精度。以下是Inception模型的构建原理:
Inception v1:Inception v1模型的核心结构是将多个并行卷积层(包括1x1、3x3和5x5)和池化层堆叠在一起。这种设计可以增加网络的宽度和深度,同时减少参数的数量。此外,Inception v1在3x3、5x5的卷积核与最大池化层后分别添加了1x1的卷积核,降低维度,这有助于减少特征图的厚度,并增加非线性变化。
Inception v2:Inception v2模型在保持Inception v1的基本结构的同时,通过使用两个连续的3x3卷积层代替5x5的卷积层,减少了计算量。此外,Inception v2还引入了Batch Normalization层,这有助于提高模型的泛化能力。
Inception v3:Inception v3模型进一步改进了Inception v2的设计。在网络的内部,Inception v3使用了Inception模块,该模块可以在不同尺度上进行卷积操作,从而增强了网络对不同尺度特征的感知能力。此外,Inception v3还将卷积核进行分解,将NxN分解为1xN与Nx1,进一步降低参数数量与计算量。
Inception模型通过引入并行卷积层、使用较小的卷积核、引入Batch Normalization层以及分解卷积核等方法,提高了模型的精度和效率。不同的Inception变体(如Inception v1、Inception v2和Inception v3)具有不同的改进和特点,适用于不同的应用场景。
由于时间原因本文仅选取了Inception v2和Inception v3两款更新的模型进行对比分析实验,感兴趣的话可以自行对Inception v1进行评测分析。
Xception模型是基于Inception模型的改进,通过引入深度分离卷积(depthwise separable convolution)操作来提高计算效率和准确性。以下是Xception模型的构建原理:
输入层:接收输入数据。
初始卷积层:使用标准的卷积操作来提取初始特征。
Xception模块:Xception模型的核心部分,由若干个Xception模块组成。每个Xception模块包含多个深度分离卷积操作。每个深度分离卷积操作由两个部分组成:深度卷积和逐点卷积。深度卷积只关注输入数据的通道维度,而逐点卷积则负责将通道维度的特征映射转换为空间维度的特征映射。这种分解操作能够减少计算量和参数数量,同时提高模型的准确性。
全局平均池化层:对特征图进行平均池化,将其转换为固定大小的特征向量。
全连接层:将特征向量映射到类别概率。
输出层:输出最终的预测结果。
Xception模型通过引入深度分离卷积操作,减少了计算量和参数数量,提高了模型的准确性和效率。这种设计使得Xception模型在许多计算机视觉任务中表现出优异的性能,特别是在大规模数据集上。
训练集占比75%,测试集占比25%,所有模型按照相同的数据集配比进行实验对比分析,计算准确率、精确率、召回率和F1值四种指标。结果详情如下所示:
{"InceptionV2": {"accuracy": 0.9440745672436751,"precision": 0.9435216621921879,"recall": 0.9468699233421537,"f1": 0.9439142835792981},"InceptionV3": {"accuracy": 0.8841544607190413,"precision": 0.8825698119466523,"recall": 0.8870460205081474,"f1": 0.8823524188634222},"Xception": {"accuracy": 0.9214380825565912,"precision": 0.9187727980921828,"recall": 0.9226904977653273,"f1": 0.919376200605818}
}简单介绍下上述使用的四种指标:
准确率(Accuracy):即分类器正确分类的样本数占总样本数的比例,通常用于评估分类模型的整体预测能力。计算公式为:准确率 = (TP + TN) / (TP + TN + FP + FN),其中 TP 表示真正例(分类器将正例正确分类的样本数)、TN 表示真负例(分类器将负例正确分类的样本数)、FP 表示假正例(分类器将负例错误分类为正例的样本数)、FN 表示假负例(分类器将正例错误分类为负例的样本数)。
精确率(Precision):即分类器预测为正例中实际为正例的样本数占预测为正例的样本数的比例。精确率评估分类器在预测为正例时的准确程度,可以避免过多地预测假正例。计算公式为:精确率 = TP / (TP + FP)。
召回率(Recall):即分类器正确预测为正例的样本数占实际为正例的样本数的比例。召回率评估分类器在实际为正例时的识别能力,可以避免漏掉过多的真正例。计算公式为:召回率 = TP / (TP + FN)。
F1 值(F1-score):综合考虑精确率和召回率,是精确率和召回率的调和平均数。F1 值在评估分类器综合表现时很有用,因为它同时关注了分类器的预测准确性和识别能力。计算公式为:F1 值 = 2 * (精确率 * 召回率) / (精确率 + 召回率)。 F1 值的取值范围在 0 到 1 之间,值越大表示分类器的综合表现越好。
为了能够直观清晰地对比不同模型的评测结果,这里对其进行可视化分析,如下所示:
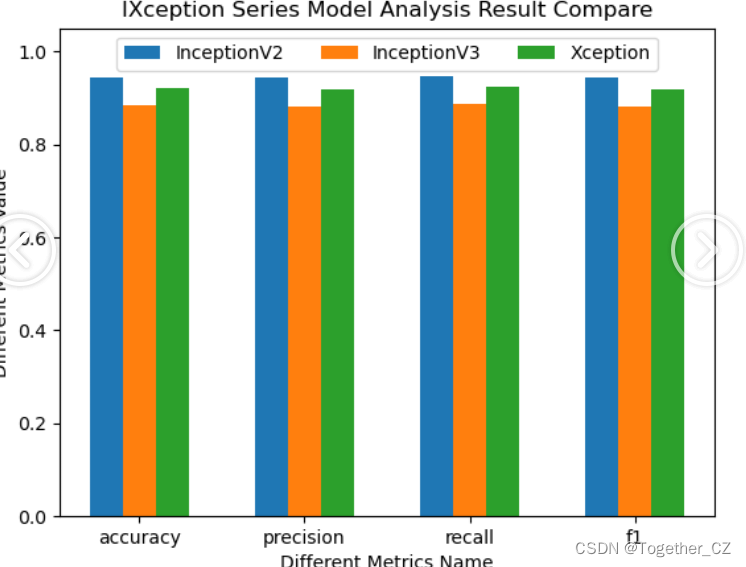
从实验对比分析结果来看:Inceptionv2取得了最优的效果,Xception模型的效果次之,而Inceptionv3的效果最差,不过相较于前面其他系列的模型,这三款模型的效果都是表现很不错的了。
这个分析评测结果仅供参考,大家在实际项目开发中可以参考这组实验,不过也可以基于自己的数据集开发全系列的模型来综合对比选取最优的模型作为生产环境的模型。
这篇关于基于InceptionV2/InceptionV3/Xception不同参数量级模型开发构建中草药图像识别分析系统,实验量化对比不同模型性能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





