本文主要是介绍二路归并排序的算法设计和复杂度分析and周记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据结构实验报告
实验目的:
通过本次实验,了解算法复杂度的分析方法,掌握递归算法时间复杂度的递推计算过程。
实验内容:
二路归并排序的算法设计和复杂度分析
实验过程:
1.算法设计
第一步,首先要将数组进行划分,假设等待排序的数组是A[SIZE],我们每次从数组的中间开始划分。
1).假设等待划分的数组是A{high …low} (是A中的一小段),划分点是它的中点,mid=(low+high)/2
2).如果数组段只剩下一个元素,比如A[5…5],划分出来也是(5+5)/2=5,A[5…5]也是它本身。
3).如果数组段是奇数项。比如A[3…5],(3+5)/2=4,划分为了A[3…4],A[5…5]
4).如果数组段是偶数段,比如A[2...5],(2+5)/2=3(因为是int),划分为了A[2,3],A[4…5],均分
第二步,划分必定是一递归的操作,因此设计一个类似于二叉树遍历的递归代码。
1).函数名是mergeSort(A[],int low, int high),每次对A[low,high]进行划分,划分为A[low…mid],A[mid+1,high],然后再对这两段数组进行递归的划分。
2).划分到单一元素的时候,进行合并操作
第三步,合并操作
2.程序清单
#include<stdio.h>
#include<malloc.h>
void disp(int a[],int n){int i;for(i=0;i<n;i++)printf("%d",a[i]);printf("\n");
}
void Merge(int a[],int low,int mid,int high){int * tmpa;int i=low,j=mid+1,k=0;tmpa=(int * )malloc((high-low+1)*sizeof(int));while (i<=mid&&j<=high)if(a[i]<=a[j]){tmpa[k]=a[i];i++;k++;}else{tmpa[k]=a[j];j++;k++;}while(i<=mid){tmpa[k]=a[i];i++;k++;}while(j<=high){tmpa[k]=a[j];j++;k++;}for(k=0,i=low;i<=high;k++,i++)a[i]=tmpa[k];free(tmpa);
}
void MergePass(int a[],int length,int n){int i;for(i=0;i+2*length-1<n;i=i+2*length)Merge(a,i,i+length-1,i+2*length-1);if(i+length-1<n)Merge(a,i,i+length-1,n-1);
}
void MergeSort(int a[],int low,int high){int mid;if(low<high){mid=(low+high)/2;MergeSort(a,low,mid);MergeSort(a,mid+1,high);Merge(a,low,mid,high);}
}
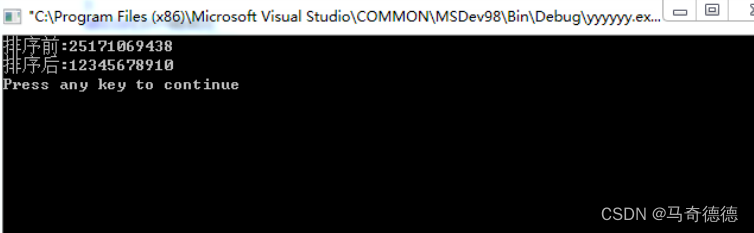
void main(){int n=10;int a[]={2,5,1,7,10,6,9,4,3,8};printf("排序前:");disp(a,n);MergeSort(a,0,9);printf("排序后:");disp(a,n);
}3.运行结果
4.算法复杂度分析
数组段是偶数段,对于上述二路归并排序算法,当有n个元素时需要[log2n]趟归并,每一趟归并,它的元素比较次数不超过n-1,元素移动次数都是n,因此二路归并排序的时间复杂度O(nlog2n)
假设MergeSort(a,0,n-1)算法的执行时间为T(n),显然,Merge(a,0,n/2,n-1)合并操作的执行时间为O(n),所以得到以下递推公式
T(n)=1 当n=1的时候
T(n)=2T(n/2)+O(n) 当n>1的时候
容易得出 T(n)=O(nlog2n)。
实验总结:
在这次实验中,我学到很多东西,加强了我的动手能力,并且培养了我的独立思考能力。特别是在做实验报告时,因为在做数据处理时出现很多问题,如果不解决的话,将会很难的继续下去。还有动手这次实验,使这门课的一些理论知识与实践相结合, 更加深刻了我对算法设计与分析这门课的认识。
生活
寒假留校上半年还好,这学期开学就奇怪了,从家里来了之后就一直发烧,吃完退烧药之后,消停了两天,又发烧,直到学校正式开学,才消停,反反复复了十来天。罢了,总归,又能活蹦乱跳了。
之前一直觉得自己性格特征不明显,网上的东西很多都是刻板印象,直到玩得熟的朋友说我线上活泼还好说话,但线下很欠打,tm是个杠精,我才意识到,欧,好吧,不过还是不喜欢给自己贴标签,因为毕竟,每个人都是独一无二的。(❁´◡`❁)
上次经历了一些事情,朋友说那么爱问原因的你,怎么这回,不问问他原因呢?因为,我认为,无论是什么原因,如果后悔了,如果选择的不是我,那就不属于我,要么全部,要么全不,我永远值得世界上最好的东西,是我的,谁也抢不走,不是我的,那我更不稀罕。或许,我的观念有一天会改变,会意识到自己的狭隘,但目前为止,我尊重当下的自己。
生活小满胜万全,现在 ,觉得,每天都无比绚丽多彩。24节气快惊蛰了,为什么喜欢春天和夏天呢?因为它灿烂,明媚,热烈。
上次跟同学聊天,偶然提到项目,他说

嘿嘿,谁得到夸夸和认可的时候不开心嘞 😎😎😎😎😎😎。
四级也过了,去年大英赛省二,今年的就不参加了,那就剩下,准备准备六级,还有蓝桥杯了......
本来是想拍这个表情包的,

但是手机怎么放都不对,于是,画风就变了,也很不错了嘞
两个突发奇想的小女孩儿( 3月1日傍晚 )
基本不追星,但是高中的时候就喜欢张新成饰演的黎语冰,现在看,还是很喜欢

嘿嘿,臭屁一下,世界上怎么会有我这么棒棒哒的人儿,天哪,又是喜欢自己的一天。

这篇关于二路归并排序的算法设计和复杂度分析and周记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






