本文主要是介绍【大数据技术】记一次spark连接MySQL读数据失败的排查,显示“No suitable driver”,但实际是driver已经配置好了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【大数据技术】记一次spark连接MySQL读数据是失败的排查
背景
使用spark shell连接MySQL并读取数据时,总是失败,并报错,显示“No suitable driver”,但实际是driver已经配置好了,并且前几天一直能正常使用
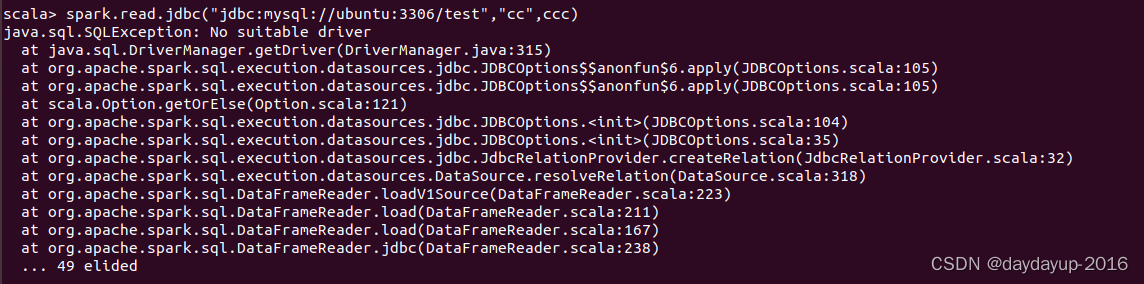
scala> spark.read.jdbc(“jdbc:mysql://ubuntu:3306/test”,“cc”,ccc)
java.sql.SQLException: No suitable driver
at java.sql.DriverManager.getDriver(DriverManager.java:315)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptionsKaTeX parse error: Can't use function '$' in math mode at position 8: anonfun$̲6.apply(JDBCOpt…anonfun$6.apply(JDBCOptions.scala:105)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.(JDBCOptions.scala:104)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.(JDBCOptions.scala:35)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:32)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:318)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:223)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:211)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:167)
at org.apache.spark.sql.DataFrameReader.jdbc(DataFrameReader.scala:238)
… 49 elided
经反复排查,原来是MySQL数据库的密码在配置里写错了,但是报错也没报密码错误啊,有点坑
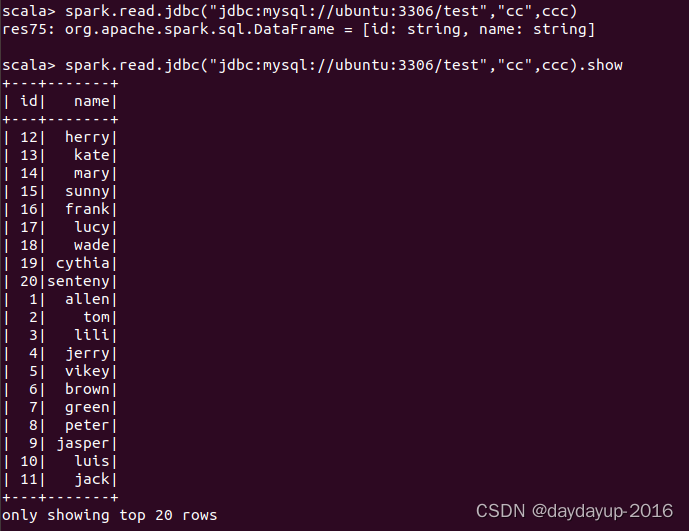
配置正确的密码后,可成功读取数据

后面就可以正确读取数据了
这篇关于【大数据技术】记一次spark连接MySQL读数据失败的排查,显示“No suitable driver”,但实际是driver已经配置好了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







