本文主要是介绍畅聊Spark(五)内核解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
整体概念
Apache Spark是一个开源的通用集群计算系统,提供了High-Level编程API,支持Scala、Java、Python三种编程语言,Spark内核是使用Scala语言编写的,通过基于Scala的函数式编程特性,在不同计算层面进行抽象。
计算抽象
Application
用户编写Spark程序,完成一个计算任务的处理,由一个Driver程序和一组运行在Spark上的Executor组成。
Job
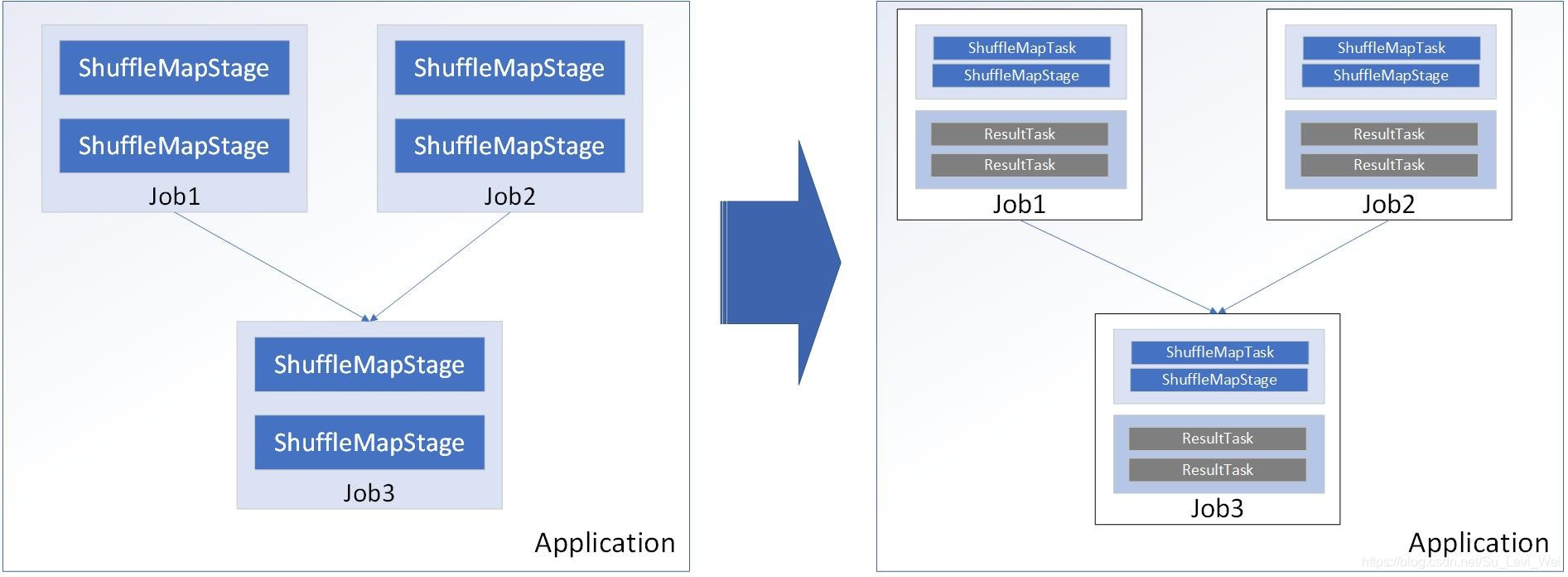
用户程序中,每次调用Action时,逻辑上都会生成一个Job,一个Job包含多个Stage
Stage
Stage包含两类,ShuffleMapStage和ResultStage,如果程序中调用了需要进行Shuffle计算的Operator,如groupByKey等,就会以Shuffle作为边界,分成ShuffleMapStage和ResultStage
TaskSet
基于Stage可以直接银蛇为TaskSet,一个TaskSet封装了一次需要运算的、具有相同处理逻辑的Task,这些Task可以并行运算,粗粒度的调度是以TaskSet为单位。
Task
Task是物理节点上运行的基本单位,Task包含两类,ShuffleMapTask和ResultTask,分别对应Stage中的ShuffleMapStage和ResultStage中的一个执行单元。
RPC通信架构
历史
1.Spark早期版本采用Akka作为内部通信部件
2.Spark 1.3引入Netty通信框架,为了解决Shuffle的大数据传输问题
3.Spark 1.6中Akka和Netty可以配置使用,Netty完全实现了Akka在Spark中的功能。
4.Spark 2.x中,抛弃了Akka,选择使用Netty
抛弃的Akka的原因
1.Akka不同版本之间无法通信,存在兼容性问题
2.用户使用Akka和Spark中的Akka存在冲突
3.Spark自身没有对Akka进行维护,需要新功能时,只能等待新版本,牵制了Spark的发展。
/*** A RpcEnv implementation must have a [[RpcEnvFactory]] implementation with an empty constructor* so that it can be created via Reflection.*/private[spark] object RpcEnv { ……def create(name: String,bindAddress: String,advertiseAddress: String,port: Int,conf: SparkConf,securityManager: SecurityManager,clientMode: Boolean): RpcEnv = {val config = RpcEnvConfig(conf, name, bindAddress, advertiseAddress, port, securityManager,clientMode)new NettyRpcEnvFactory().create(config)}}
|
通信组件概览
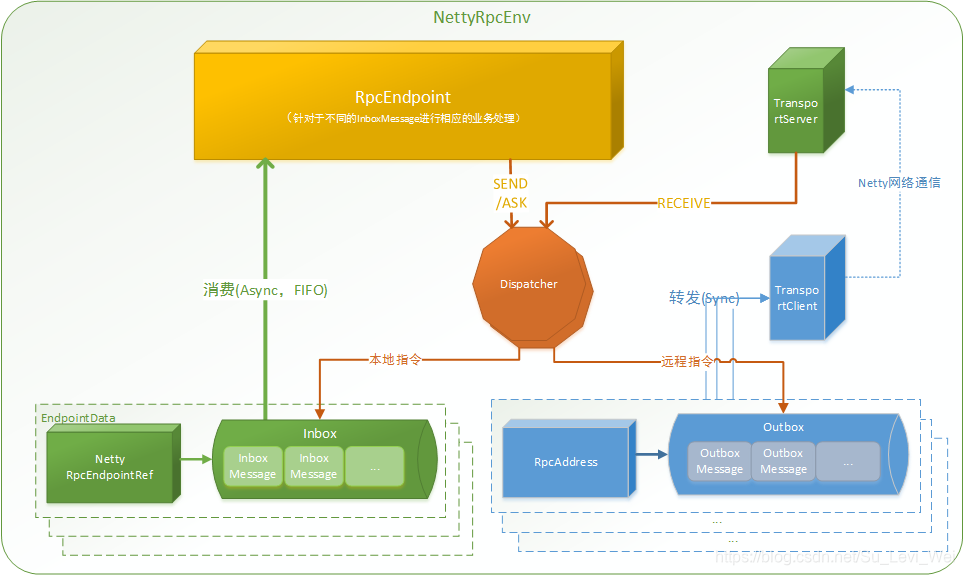
1.RPCEndpoint:RPC端点,Spark针对每一个节点(Client/Master/Worker)都称为一个PRC端点,而且都实现了RpcEndpoint接口,内部根据不同端点的需求,设计不同的消息和不同的业务处理,如果需要发送(询问)则调用Dispatcher。
2.RpcEnv:RPC上下文环境,每个Rpc端点运行时依赖的上下文环境,称为RPCEnv。
3.Dispatcher:消息分发器,针对RPC端点需要发送消息或者从远程RPC接收到的消息,分发至对应的指令收件箱/发件箱,如果指令接收方是自己存入收件箱,如果接收方非自身端点,则放入发件箱。
4.Inbox:指令消息收件箱,一个本地端点对应一个收件箱,Dispatcher在每次Inbox存入消息时,都会将对应EndpointData加入内部,待Receiver Queue中,另外Dispatcher创建时,会启动一个单独线程进行轮询Receiver Queue,进行收件箱消费。
5.OutBox:指令消息发件箱,一个远程端点对应一个发件箱,当消息放入Outbox后,接着将消息通过TransportClient发送出去,消息放入发件箱以及发送过程是在同一个线程中进行,这样做的主要原因是远程消息为RpcOutboxMessage,OneWayOutboxMessage两种消息,而针对需要应答的消息,直接发送且需要得到结果进行处理。
6.TransportClient:Netty通信客户端,根据OutBox消息的receiver信息,请求对应远程TransportServer。
7.TransportServer:Netty通信服务端,一个RPC端点一个TransportServer,接收远程消息后,调用Dispatcher分发消息至对应收件箱。
注:TransportClient和TransportServer通信虚线,表示两个RPCEnv之间通信。
一个Outbox一个TransportClient
一个RPCEnv中存在两个RPCEndpoint,一个代表本身启动的PRC端点,另外一个为RPCEndpointVerifier。

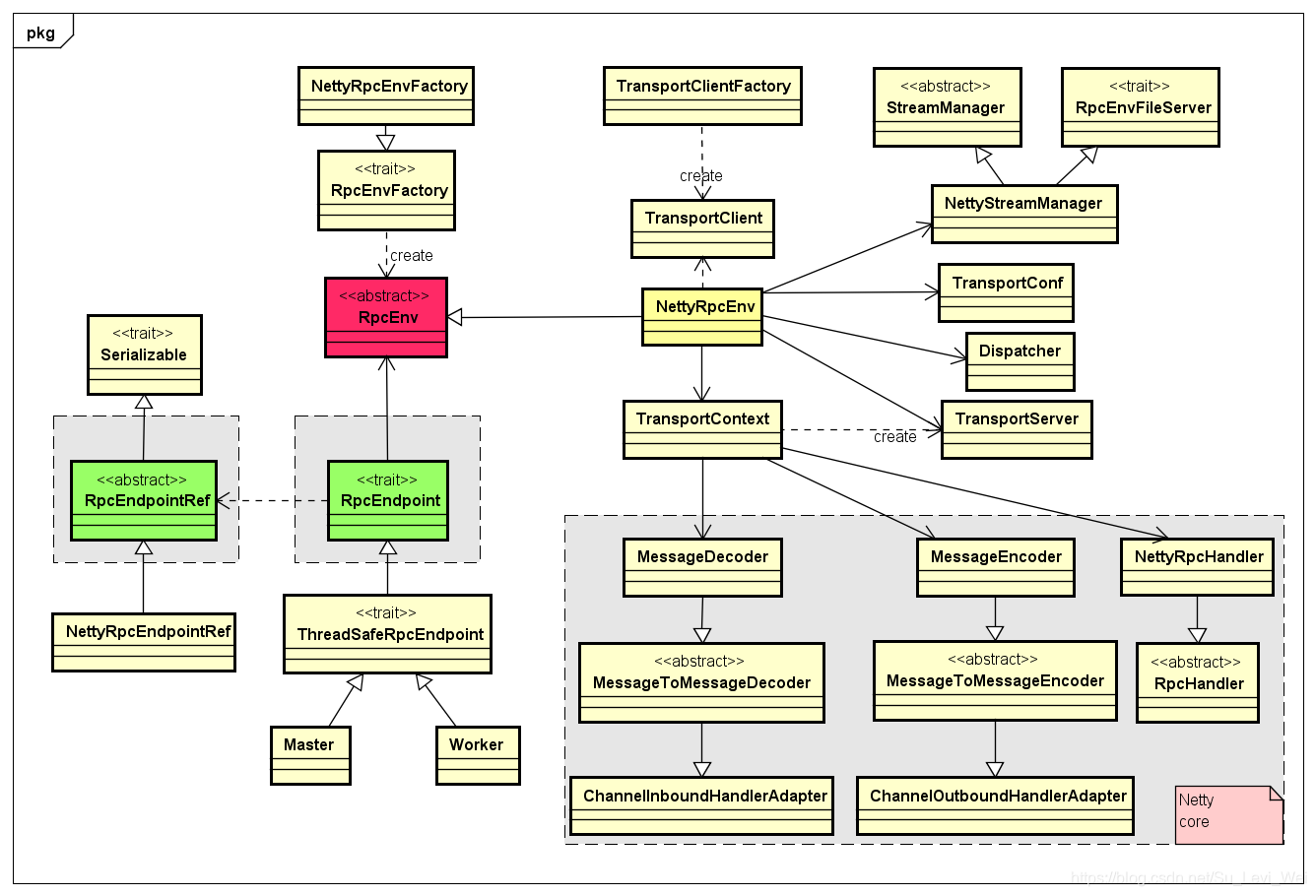
内部实现
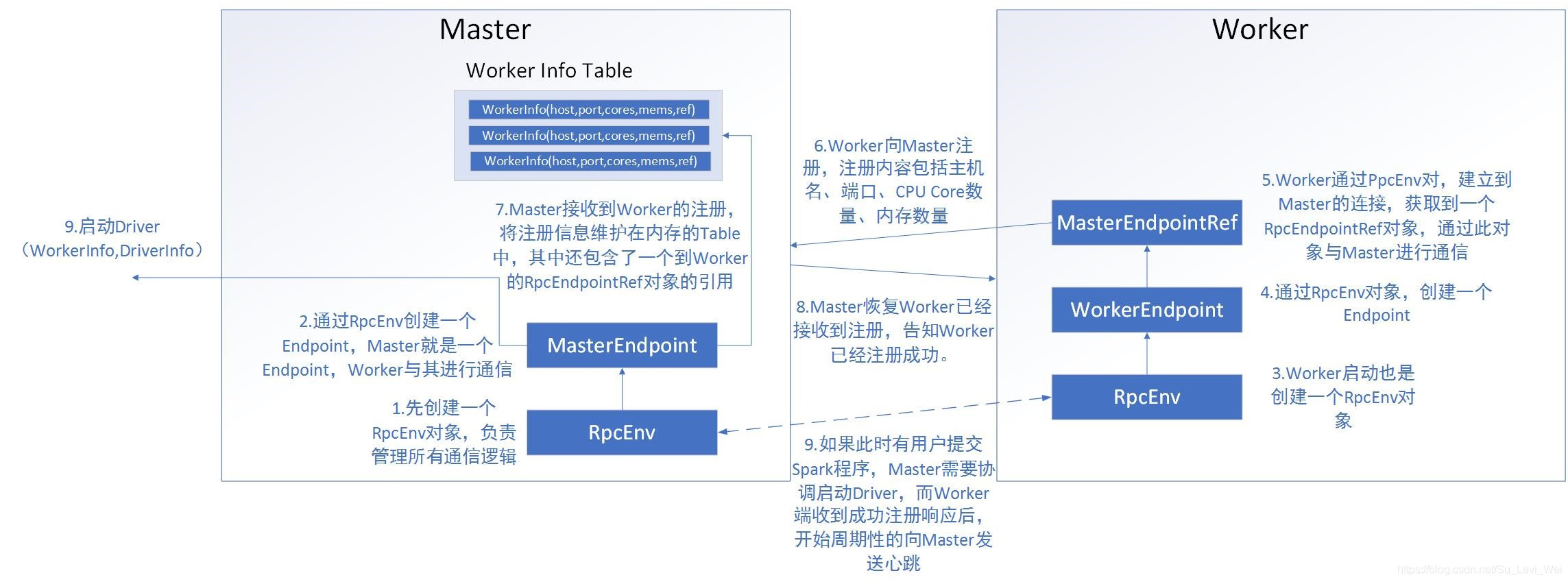
Master和Worker的通信(Standalone)
核心组件
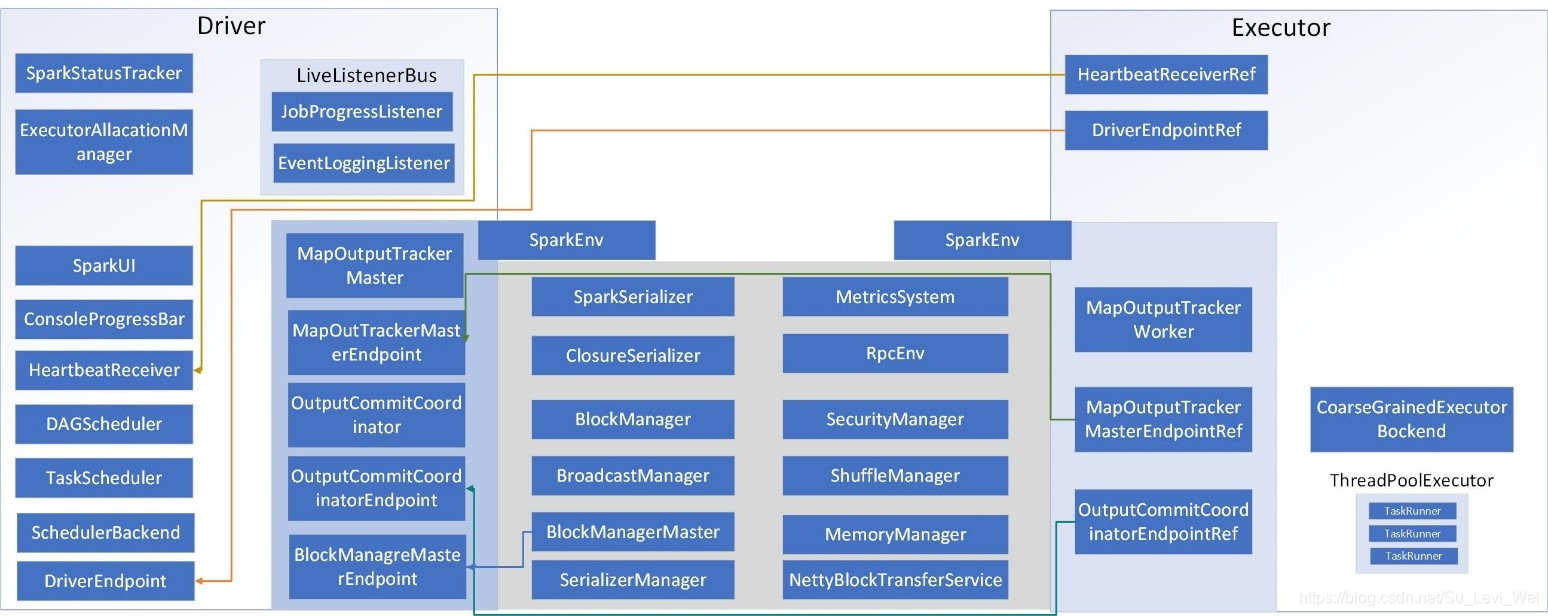
核心交互流程
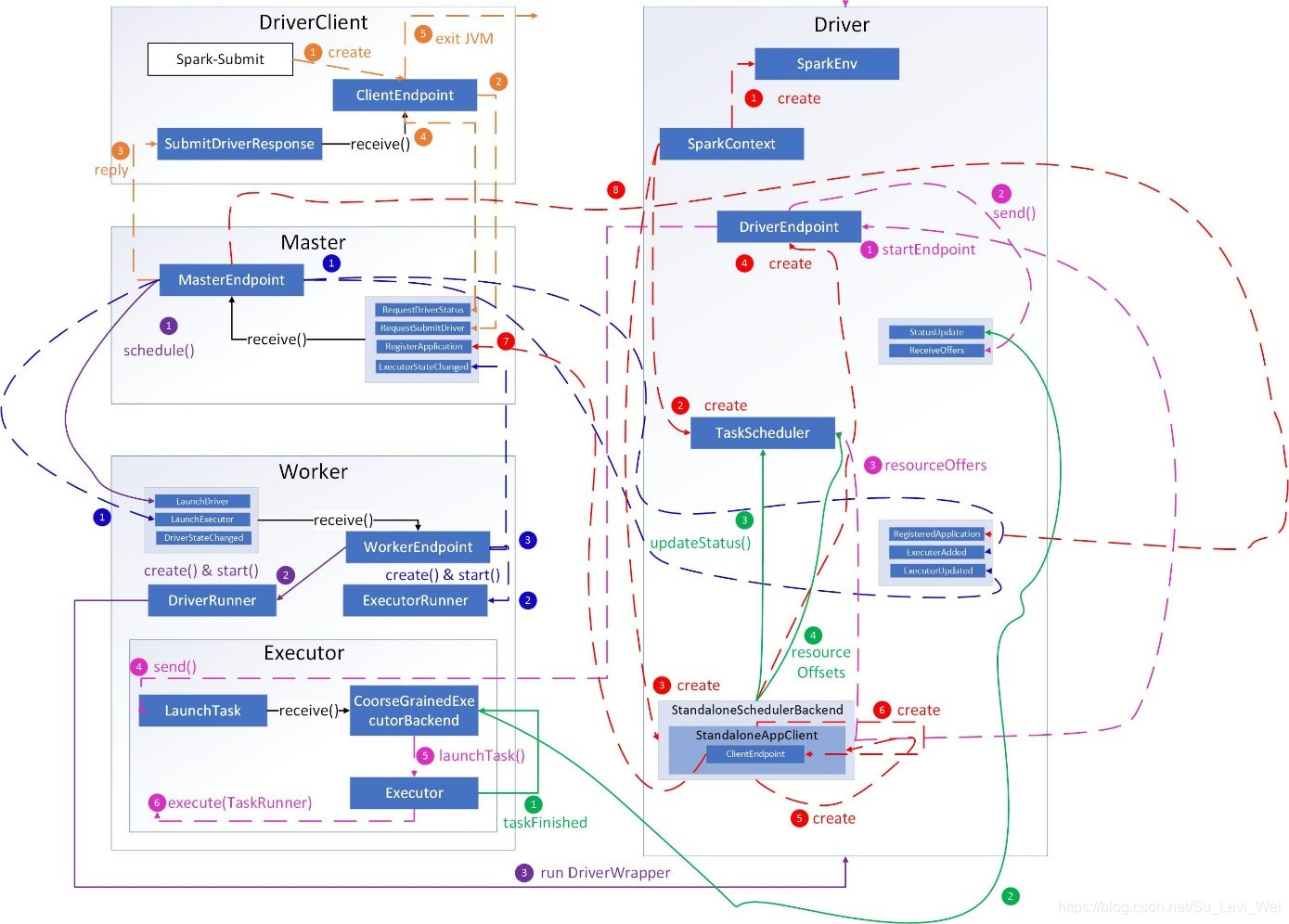
橙色:提交用户Spark程序
1.spark-submit脚本提交一个Spark程序,会创建一个ClientEndpoint对象,该对象负责和Master通信交互。
2.ClientEndpoint向Master发送一个RequestSubmitDriver消息,表示提交用户程序。
3.Master收到RequestSubmitDriver消息,向ClientEndpoint回复SubmitDriverResponse,表示用户程序已注册。
4.ClientEndpoint向Master发送RequestDriverStatus消息,请求Driver状态。
5.如果当前用户程序对应的Driver已经启动,则ClientEndpoint直接退出,完成提交用户程序。
紫色:启动Driver进程
1.Master内存维护者用户提交计算的任务Application,每次内存结构变更都会触发调度,向Worker发送LaunchDriver请求。
2.Worker收到LaunchDriver消息,会启动一个DriverRunner线程去执行LaunchDriver的任务。
3.DriverRunner线程在Worker上启动一个新的JVM实例,该JVM实例内运行一个Driver进程,该Driver会创建SparkContext对象。
红色:注册Application
1.创建SparkEnv对象,创建并管理一些基本组件。
2.创建TaskScheduler,负责Task调度
3.创建StandaloneSchedulerBackend,负责与ClusterManager进行资源协调。
4.创建DirverEndpoint,其他组件可以与Driver进行通信。
5.在StandaloneSchedulerBackend内部创建一个StandaloneAppClient,负责处理和Master的通信交互。
6.StandaloneAppClient创建一个ClientEndpoint,实际负责与Master通信。
7.ClientEndpoint向Master发送RegisterApplication消息,注册Application。
8.Master收到RegisterApplication请求后,恢复ClientEndpoint一个RegisterApplication,表示已经注册成功。
蓝色:启动Executor进程
1.Master向Worker发送LaunchExecutor消息,请求启动Executor,同时Master会向Driver发送ExecutorAdded消息,表示Master新增了一个Executor(还未启动)。
2.Worker收到LaunchExecutor消息,会启动一个ExecutorRunner线程去执行LaunchExecutor的任务。
3.Worke向Master发送ExecutorStageChanged消息,通知Executor状态已发生变化。
4.Master向Driver发送ExecutorUpdated消息,此时Executor已经启动。
粉色:启动Executor进程
1.StandaloneSchedulerBackend启动一个DriverEndpoint
2.DriverEndpoint启动后,会周期性检查Driver维护的Executor的状态,如果有空闲的Executor则会调度任务执行。
3.DriverEndpoint向TaskScheduler发送Resource Offer请求。
4.如果有可用资源启动Task,则DriverEndpoint向Executor发送LaunchTask请求。
5.Executor进程内部的CoarseGrainedExecutorBackend调用内部的Executor线程的LaunchTask方法启动Task。
6.Executor线程内部维护一个线程池,创建一个TaskRunner线程并提交到线程池执行。
绿色:Task运行完成
1.Executor进程内部的Executor线程通知CoarseGrainedExecutorBackend,Task运行完成了。
2. CoarseGrainedExecutorBackend向DriverEndpoint发送StatusUpdated消息,通知Driver运行的Task状态变更。
3.StandaloneSchedulerBackend调用TaskScheduler的updateStatus方法更新Task状态。
4.随后StandaloneSchedulerBackend调用TaskScheduler的resourceOffers方法,调度其他任务运行。
整体应用
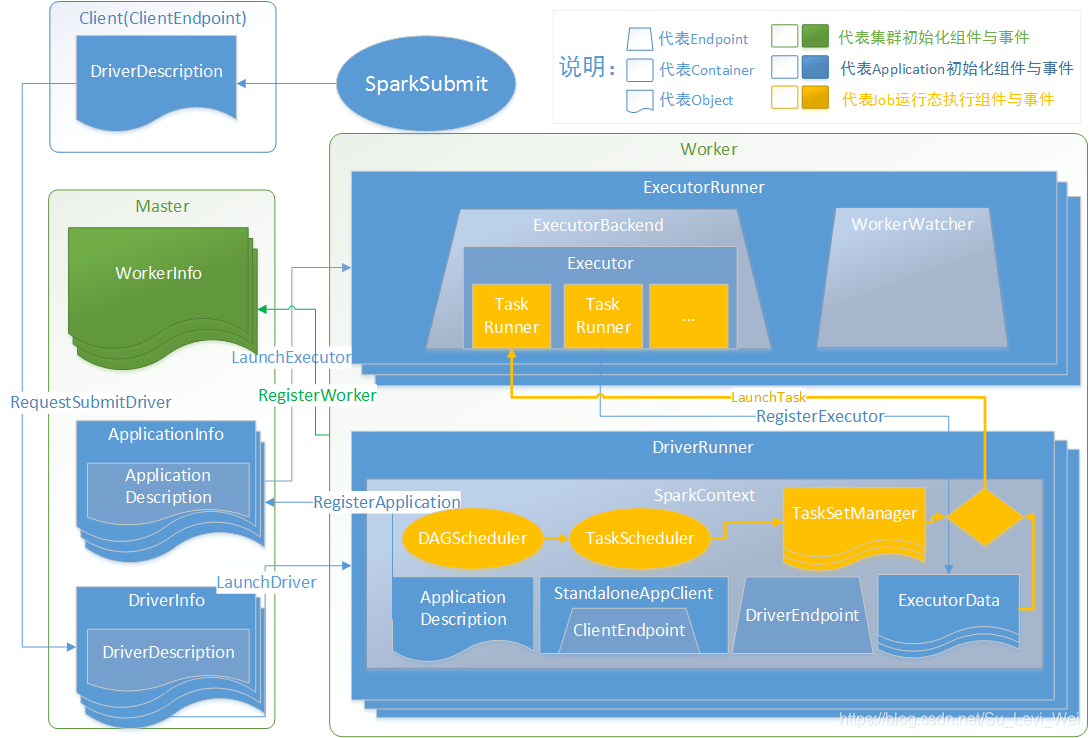
1.Client运行时向Master发送启动驱动申请(发送RequestSubmitDriver指令)
2.Master调度可用的Worker资源进行驱动安装(发送LaunchDriver指令)
3.Worker运行DriverRunner进行驱动加载,并向Master发送应用注册请求(发送RegisterApplication指令)
4.Master调度可用Worker资源进行应用的Executor安装(发送LaunchExecutor指令)
5.Executor安装完毕后,向Driver注册驱动可用Executor资源(发送RegisterExecutor指令)
6.最后是运行用户代码时,通过DAGScheduler,TaskScheduler封装为可以执行的TaskSetManager对象
7.TaskSetManager对象与Driver中的Executor资源进行匹配,在队形的Executor中发布任务(发送LaunchTask指令)
8.TaskRunner执行完毕后,调用DriverRunner提交给DAGScehduler,循环7直到任务完成。
SparkContext
SparkContext是用户通往Spark集群中的唯一出口,任何需要使用Spark的地方都需要先创建SparkContext。
SparkContext是在Driver程序里面启动的,可以看做Driver成和Spark集群的一个连接,SparkContext在初始化时,创建了很多对象。
下图:列出了SparkContext在初始化创建时的一些主要组件的构建。
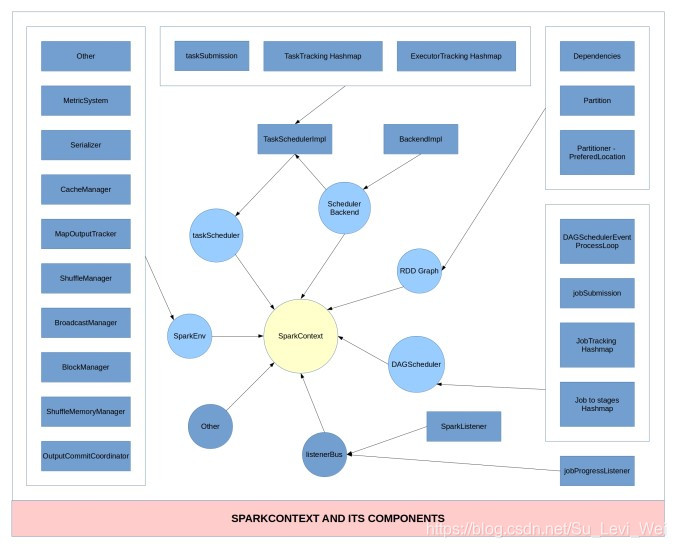
SparkContext结构和交互关系
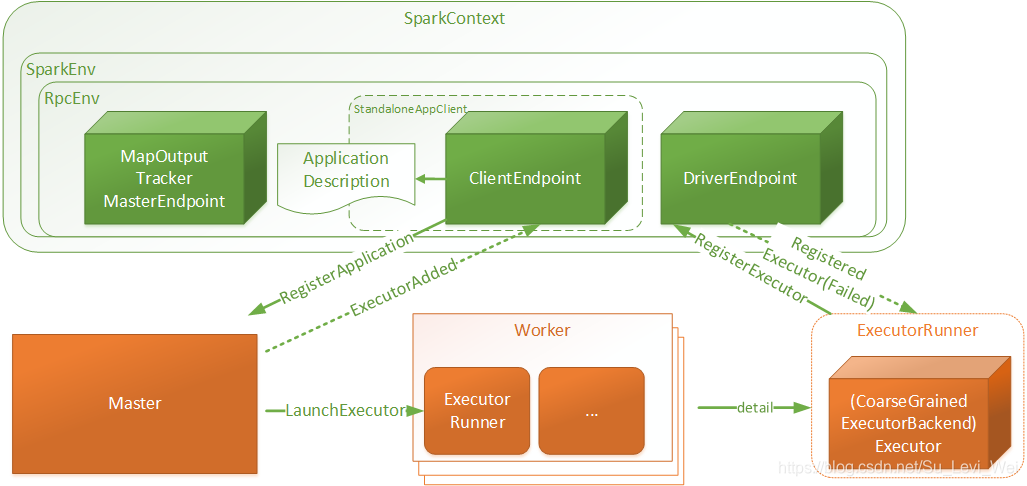
1.SparkContext是用户Spark执行任务上下文,用户程序内部使用Spark提供的Api直接或间接创建一个SparkContext。
2.SparkEnv:用户执行的环境信息,包括通信相关的端点。
3.RpcEnv:SparkContext中远程通信环境
4.ApplicationDescription:应用程序描述信息,主要包含appName、maxCoes、memoryPerExecutorMB、coresPerExecutor、Command(CoarseGrainedExecutorBackend)、AppUiUrl等……
5.ClientEndpoint:客户端端点,启动后向Master发起注册RegisterApplication请求。
6.Master:接受RegisterApplication请求后,进行Worker资源分配,并向分配的资源发起LaunchExecutor指令。
7.Worker:接受LaunchExecutor指令后,运行ExecutorRunner
8.ExecutorRunner:运行applicationDescription的Command命令,最终Executor,同时向DriverEndpoint注册Executor信息。
MapReduce和Spark过程对比
| 对比项 | MapReduce | Spark |
| collect | 在内存中构造了一块数据结构用于map输出的缓冲 | 没有在内存中构造一块数据结构用于map输出的缓冲,而是直接把输出写到磁盘文件 |
| sort | Map输出的数据是有序的 | Map输出的数据是无序 |
| merge | 对磁盘上的多个spill文件最后进行合并成一个输出文件 | 在map端没有merge过程,在输出时,直接是对应一个reduce的数据写到一个文件中,这些文件同时存在并发写,最后不需要合并成一个 |
| copy | 框架jetty | Netty或socket流 |
| 本地文件 | 依然是网络框架拉取数据 | 不通过网络框架,对于本节点的map输出文件,采用本地读取的方式 |
| copy | 过来的数据存放位置,先放内存,内存放不下时写磁盘 | 一种方式全部放内存,另一种是放在内存,放不下时写磁盘 |
| merge sort | 最后会对磁盘文件和内存中的数据进行合并排序 | 对于采用另一种方式时也会有合并排序的过程 |
存储子系统
Storage模块主要分为两层:
1.通信层:Storage模块采用的是master-slave结构来实现通信层,master和slave之间传输控制信息、状态信息,这些都是通过通信层来实现的。
2.存储层:storage模块需要把数据存储到disk或memory上面,有可能还需要replicate到远端,这些都是由存储层来实现和提供相应接口的。
而其他模块若是和Storage模块进行交互,Storage模块提供了一些统一的操作类BlockManager,外部类和storage模块打交道都需要通过调用BlockManager相应接口来实现。
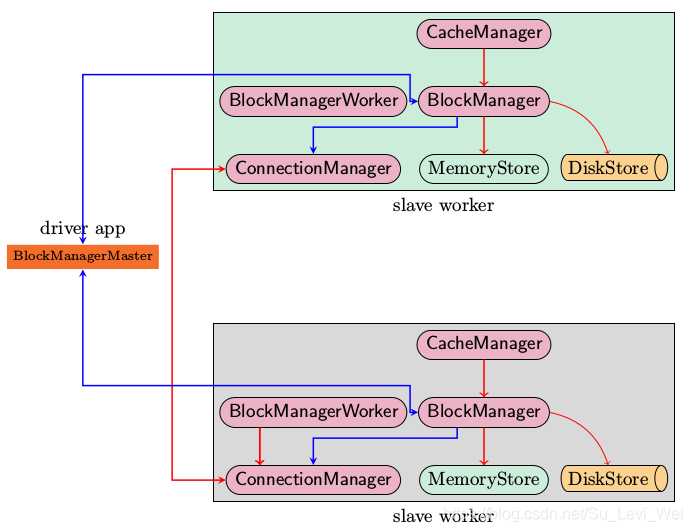
上图是Spark存储子系统中几个主要模块的关系图:
1.CacheManager:RDD在进行计算的时候,通过CacheManager来获取数据,并通过CacheManager来存储计算结果。
2.BlockManger:CacheManager在进行数据读取和存取的时候,主要是依赖BlockManager接口来操作,BlockManager决定数据是从内存(MemoryStore)还是从磁盘(DiskStore)获取。
3.MemoryStore:负责将数据保存在内存或读取
4.DiskStore:负责将数据写入磁盘或读取
5.BlockManagerWorker:数据写入本地的MemoryStore或DiskStore是一个同步操作,为了容错还需要将数据负责到别的计算节点,以防止数据丢失时,还能恢复,数据复制的操作是异步完成,由BlockManagerWorker来处理这一部分事情。
6.ConnectionManager:负责和其他计算节点建立连接,并负责数据的发送和接受。
7.BlockManagerMaster:该模块只运行在Dirver Application所在的Executor,功能是负责记录下所有的BlockIds存储在哪个SlaveWorker上,比如RDD Task运行在机器A,所需要的是BlockId为3,但在机器A上没有BlockId为3的数值,这个时候Slave Worker需要通过BlockManager向BlockManagerMaster询问数据存储的位置,然后再通过ConnectionManager去获取。
Spark内存管理
作为一个JVM进程,Executor的内存管理建立在JVM的内存管理之上,Spark对JVM的堆内(On-heap)空间,进行了更为详细的分配,以充分利用内存,同时Spark引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,进一步优化了内存的使用。
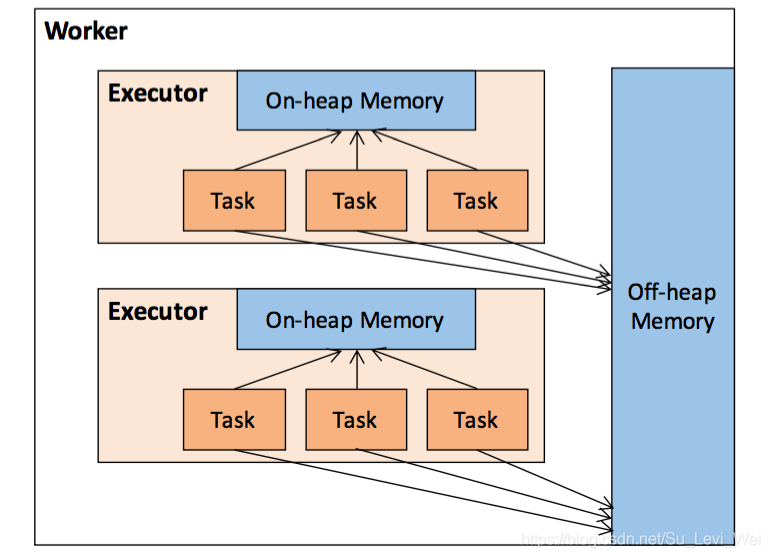
堆内内存
堆内存储的大小,由Spark应用成启动时的-executor-memory或spark.executor.memory参数配置。
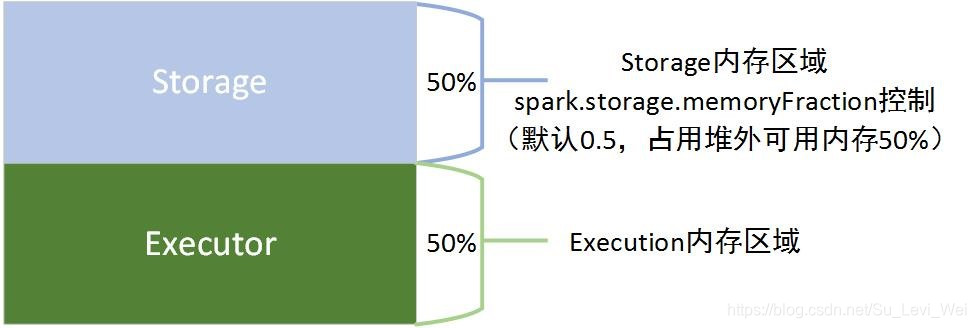
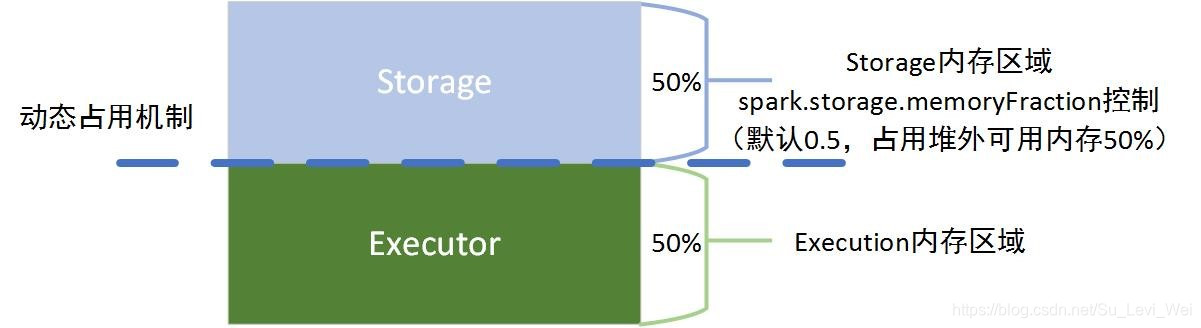
Executor内运行的并发任务共享JVM堆内内存,这些任务在缓存RDD数据和在广播(Broadcast)数据时,占用的内存被规划为存储(Storage)内存,而任务在执行Shuffle时,占用的内存被规划为执行(Executor)内存,剩余的部分,不做特殊规划,那些Spark内部的对象实例,或者用户定义的Spark应用程序中的对象实例,均占用剩余的空间,不同的管理模式下,占用的空间也不尽相同。
堆外内存
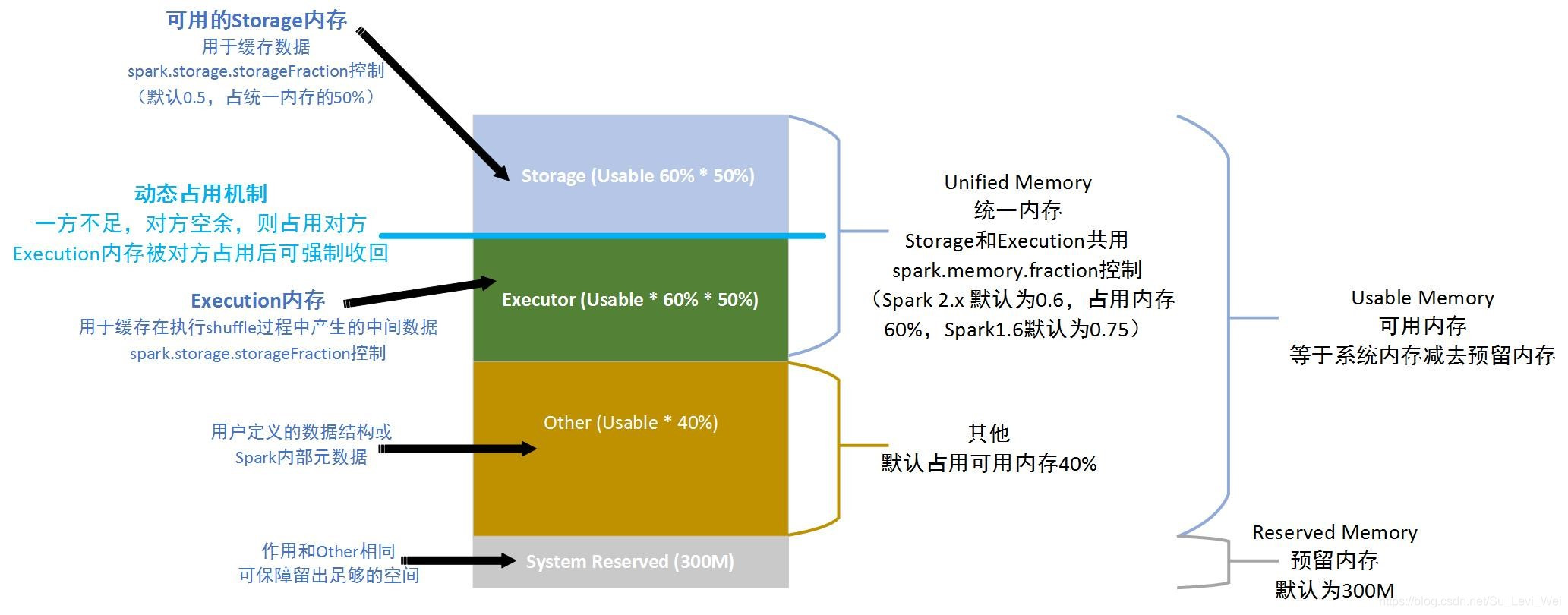
为了进一步优化内存的使用,及提高Shuffle时排序的效率,Spark引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据,利用JDK Unsafe Api(从Spakr2.0开始,在管理堆外的存储内存时,不再基于Tachyon,而是和堆外的执行内存一样,基于JDK Unsafe API 实现),Spakr可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的GC扫描和回收,提升了处理性能。
堆外内存可以被精确的申请和释放,而且序列化的数据占用的的空间,可以被精确计算,所以相比堆内内存来说,降低了管理的难度,也降低了误差。
默认情况下堆外内存是不启动的,可以通过配置spark.memory.offHeap.enabled参数启用,并由spark.memory.offHeap.size参数来设置堆外空间的消息。
堆外内存和堆内内存的划分方式相同,所有运行中的并发任务共享存储内存和执行内存。
内存空间的分配
静态内存管理 – 堆内
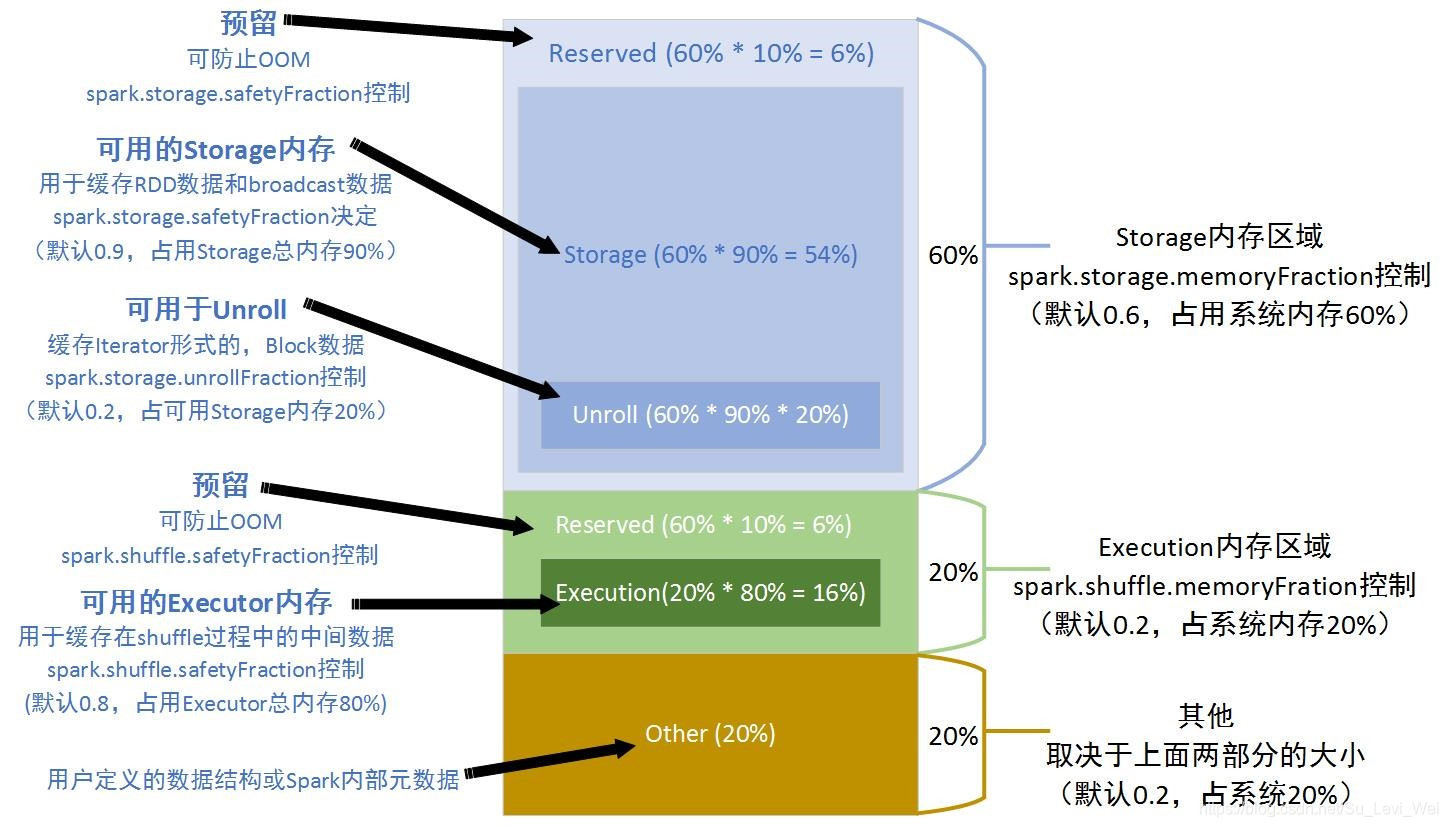
静态内存管理 – 堆外
统一内存 – 堆内
统一内存 – 堆外
异常场景分析
Worker异常退出了
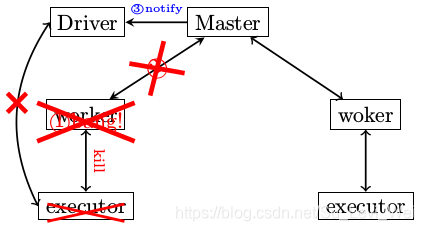
1.Worker异常退出,比如说有意识的通过kill指令将Worker杀死。
2.Worker在退出之前,会将自己管控的所有Executor给干掉。
3.Worker需要定期向Master发送心跳消息,Worker进程挂了,心跳消息自然也没了,所以Master会在超时处理中得知。
4.Master会把情况汇报给Driver
5.Driver通过两方面却分配给自己的Executor挂了,一是Master发送来的消息,二是Driver没有在规定的时间内收到Executor的StatuUpdate,于是Driver会将注册的Executor移除。
后果分析:
1.Worker异常退出,提交的Task无法正常的结束,会被再一次提交运行
2.如果所有的Worker都异常退出,则整个集群就不可用了。
3.需要有相应的程序来重启Worker进程,比如使用superisord或runit。
Executor异常退出了
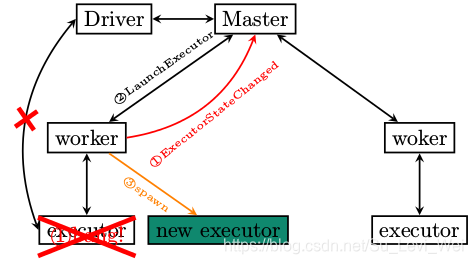
Executor作为Standalone集群部署方式下的,最底层单位。
Executor异常退出,ExecutorRunner注意到异常,将情况通过ExecutorStateChanged汇报给Master。
Master收到通知后,会要求Worker再次启动Executor。
Worker收到LaunchExecutor指令,再次启动Executor。
Master异常退出了
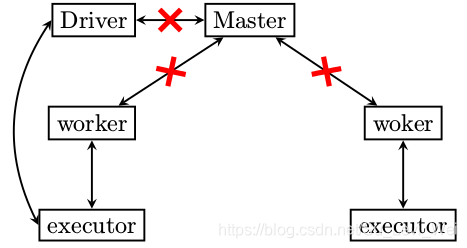
1.Worker没有汇报的对象了,也就是如果Executor再次跑飞了,Worker是不会将Executor启动起来的,因为没有Master的指令。
2.无法向集群提交新任务。
3.老的任务即便结束了,占用的资源也无法清除,因为资源清除的指令是由Master发出。
这篇关于畅聊Spark(五)内核解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






