本文主要是介绍存内计算技术大幅提升机器学习算法的性能—挑战与解决方案探讨,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一.存内计算技术大幅机器学习算法的性能
1.1背景
人工智能技术的迅速发展使人工智能芯片成为备受关注的关键组成部分。在人工智能的构建中,算力是三个支柱之一,包括数据、算法和算力。目前,人工智能芯片的发展主要集中在两个方向:一方面是采用传统计算架构的AI加速器/计算卡,以GPU、FPGA和ASIC为代表;另一方面则是采用颠覆性的冯诺依曼架构,以存算一体芯片为代表。
随着摩尔定律接近极限,传统的器件微缩技术在功耗和可靠性方面面临挑战。冯诺依曼架构已难以满足人工智能计算对算力和低功耗的需求,而存算一体芯片以其独特的架构在算力和能效比方面表现突出。
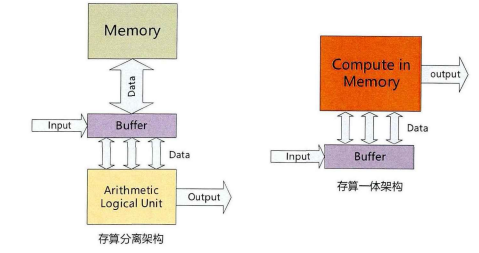
二.存内计算的优势
传统的计算架构在神经网络训练中存在着数据搬运的瓶颈问题,而存内计算通过在存储单元中嵌入计算单元,实现了计算和存储的无缝衔接。这种融合改变了数据处理的方式,为神经网络的性能提升提供了更为高效的途径。
存内计算的主要优势之一是减少了数据搬运的需求。在传统计算中,由于计算和存储分离,大量的数据需要在两者之间传输,导致了较高的延迟和能耗。而存内计算通过将计算操作直接嵌入存储单元,实现了本地计算,降低了数据搬运的成本,提高了计算效率。
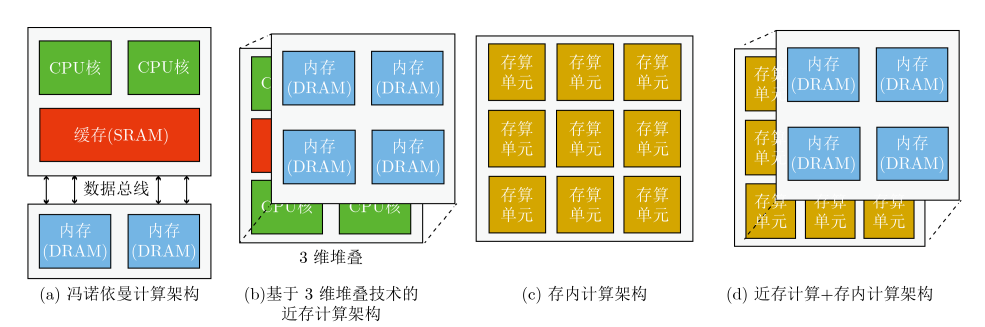
此外,存内计算还在存储设备中引入了更多的智能。通过在存储单元中集成计算单元,可以实现对数据的实时处理和分析,使存储设备更具智能化,更适应复杂的神经网络计算需求。
三. 存内计算与神经网络的结合
3.1 存内计算在神经网络训练中的应用
在神经网络的训练阶段,大量的参数需要不断地进行更新和优化。传统计算中,这些参数通常存储在外部内存中,导致了频繁的数据搬运。而存内计算通过在存储设备中嵌入计算单元,可以直接在存储单元中进行参数更新,减少了数据传输,提高了训练速度。
写一个用于演示神经网络和存内计算的基本概念。
import torch
import torch.nn as nn
import torch.optim as optim# 定义一个简单的神经网络模型
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc1 = nn.Linear(10, 5)self.fc2 = nn.Linear(5, 1)def forward(self, x):x = torch.relu(self.fc1(x))x = self.fc2(x)return x# 创建一个模型实例
model = SimpleModel()# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 构造一个简单的训练数据集
inputs = torch.randn((100, 10))
labels = torch.randn((100, 1))# 训练模型
for epoch in range(100):# 前向传播outputs = model(inputs)# 计算损失loss = criterion(outputs, labels)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if epoch % 10 == 0:print(f'Epoch {epoch}, Loss: {loss.item()}')# 模型训练完成后,可以使用该模型进行推理
new_data = torch.randn((5, 10))
predictions = model(new_data)
print("Predictions:", predictions)
对上面的代码做一个代码解析:
定义神经网络模型:
- 使用
nn.Module基类创建了一个名为SimpleModel的神经网络模型。 - 模型有两层全连接层(Linear层),分别是
self.fc1和self.fc2。 - 输入维度为10,第一层输出维度为5,第二层输出维度为1。
- 激活函数采用ReLU。
创建模型实例:
- 实例化了
SimpleModel类,得到名为model的模型实例。
定义损失函数和优化器:
- 使用均方误差损失(
nn.MSELoss)作为损失函数。 - 使用随机梯度下降优化器(
optim.SGD)来更新模型参数,学习率为0.01。
构造训练数据集:
- 生成一个大小为(100, 10)的随机输入数据集
inputs。 - 生成一个大小为(100, 1)的随机标签数据集
labels。
训练模型:
- 使用一个简单的循环进行训练,循环迭代100次。
- 在每个迭代中,通过前向传播计算模型的输出。
- 使用均方误差损失计算输出与标签之间的损失。
- 使用反向传播更新模型参数,采用随机梯度下降优化器。
- 每隔10个迭代,打印当前迭代次数和损失值。
模型推理:
- 创建一个大小为(5, 10)的新数据集
new_data。 - 使用训练好的模型对新数据进行推理,得到预测结果
predictions。
3.2 存内计算在神经网络推理中的应用
在神经网络的推理阶段,存内计算同样展现了其优越性。神经网络模型经过训练后,参数已经固定,此时可以将计算单元直接嵌入存储单元中,实现在存储设备内完成推理过程。这种本地化的计算方式不仅提高了推理的速度,还降低了功耗,使得神经网络在边缘设备上的应用更为高效。
为了更具体地展示存内计算的应用,介绍一个基于PyTorch的简单神经网络加速案例。使用存内计算的概念来优化神经网络的训练过程。
首先,确保已经安装了PyTorch和相关的库:
pip install torch
pip install torchvision接下来,我们将通过修改之前的简单模型代码,引入存内计算的思想:
import torch
import torch.nn as nn
import torch.optim as optim# 定义一个使用存内计算的神经网络模型
class AcceleratedModel(nn.Module):
def __init__(self):
super(AcceleratedModel, self).__init__()
# 在存储单元中引入计算操作
self.fc1 = nn.Linear(10, 5, bias=False)
self.fc2 = nn.Linear(5, 1, bias=False)def forward(self, x):
# 在存储单元中进行计算
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x# 创建一个使用存内计算的模型实例
accelerated_model = AcceleratedModel()# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(accelerated_model.parameters(), lr=0.01)# 训练模型
for epoch in range(100):
# 前向传播
outputs = accelerated_model(inputs)# 计算损失
loss = criterion(outputs, labels)# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()if epoch % 10 == 0:
print(f'Epoch {epoch}, Loss: {loss.item()}')在这个例子中,我修改了模型代码,将线性层的偏置(bias)设置为False,这样就在存储单元中引入了计算操作,实现了一种简化的存内计算。
这段代码与之前的代码相似,但有一些关键区别:
使用存内计算:
- 在这个代码中,
AcceleratedModel引入了存内计算(in-place computation)。 - 对于线性层
nn.Linear,通过设置bias=False,禁用了偏置项的引入。 - 这样做是为了在存储单元中进行计算,减少内存使用和提高计算效率。
存内计算的好处:
- 存内计算指的是在原始内存位置上执行操作,而不是创建新的内存来存储结果。
- 这可以节省内存,并且有时可以提高计算速度。
- 在这里,通过禁用偏置项,可以减少额外的内存使用,适用于特定的计算场景。
训练过程:
- 训练过程的结构与之前的代码相似,仍然使用均方误差损失和随机梯度下降优化器。
- 通过前向传播、损失计算、反向传播和优化的循环进行模型训练。
打印训练过程中的损失值:
- 在每隔10个迭代时,打印当前迭代次数和损失值。
总体来说,这段代码在神经网络模型中引入了存内计算的特性,通过禁用偏置项来实现,从而可能在一些场景下提高计算效率。
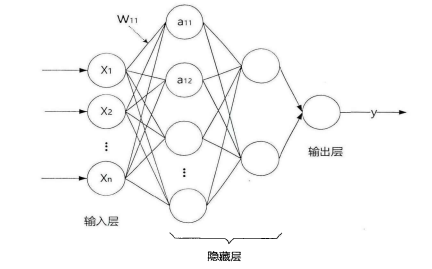
四. 未来发展方向
随着硬件技术和人工智能领域的不断发展,存内计算在神经网络中的应用有望迎来更多创新。未来的发展方向可能包括:
-
硬件优化: 设计更为高效的存内计算硬件,以满足不同神经网络模型和任务的需求。
-
自适应存内计算: 研究如何在不同计算场景下自适应地使用存内计算,以实现更灵活的神经网络加速。
-
跨领域合作: 推动存内计算技术与其他领域的融合,如物联网、医疗、自动驾驶等,拓展存内计算的应用场景。
五. 存内计算的挑战与解决方案
虽然存内计算在提高神经网络性能方面表现出色,但也面临一些挑战。其中之一是硬件设计上的复杂性,特别是在实现存储单元和计算单元的紧密集成方面。此外,存内计算的适用范围和性能优势可能取决于特定的神经网络架构和任务。
为了应对这些挑战,研究人员和工程师正在进行深入的研究和创新。硬件优化方面的工作包括设计更高效的存内计算芯片,以提高性能并降低功耗。此外,制定通用的存内计算标准和接口,以促进不同硬件和软件之间的互操作性,也是解决挑战的重要一步。
六. 存内计算在实际应用中的案例
存内计算技术已经在一些实际应用中取得了显著的成果。在医疗影像分析中,采用存内计算的神经网络可以在设备端实现快速的诊断,减少数据传输和保护患者隐私。在自动驾驶领域,存内计算有望提高车辆对环境的感知速度,从而增强驾驶安全性。
这些案例突显了存内计算在实际应用中的潜力,同时也为未来更广泛的领域提供了启示。随着技术的进一步成熟和应用场景的不断拓展,存内计算将成为推动人工智能技术发展的重要引擎之一。
此外,存内计算在边缘设备上的广泛应用可能引发关于算法的公平性和透明度的讨论。确保存内计算系统的决策过程公正、可解释,以及对不同群体的平等对待,将有助于建立社会对这一技术的信任。

七. 总结
存内计算技术作为人工智能领域的一项创新,为神经网络的发展提供了全新的可能性。通过将计算操作嵌入存储单元,存内计算有效地解决了传统计算架构中数据搬运的瓶颈问题,提高了计算效率,降低了功耗。
随着未来的不断探索和发展,存内计算有望在人工智能领域发挥更大的作用。然而,我们也需谨慎应对相关的挑战和伦理考量,确保这一技术的应用能够符合社会的期望和法规,推动人工智能技术的可持续发展。在这个不断演进的领域,存内计算将继续为人工智能的未来发展带来新的可能性。
参考文献
- Vincent B .3D DRAM时代即将到来,泛林集团这样构想3D DRAM的未来架构[J].世界电子元器件,2023,(08):13-18.
- 3D DRAM Is Coming. Here’s a Possible Way to Build It.Benjamin Vincent.Jul 14, 2023
- 邱鲤跳.3D堆叠DRAM Cache的建模以及功耗优化关键技术研究[D].国防科学技术大学,2016.
- 存内计算概述
- 中国科学技术大学
这篇关于存内计算技术大幅提升机器学习算法的性能—挑战与解决方案探讨的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


