本文主要是介绍模型训练篇 | yolov9来了!手把手教你如何用yolov9训练自己的数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

前言:Hello大家好,我是小哥谈。YOLOv9是一种目标检测算法,它是YOLO(You Only Look Once)系列算法的最新版本。本节课就带领大家如何基于YOLOv9来训练自己的目标检测模型,本次作者就以安全帽佩戴检测为案例进行说明,让大家可以轻松了解整个模型训练过程!~🌈
目录
🚀1.算法介绍
🚀2.数据标注
🚀3.模型训练
🚀4.源码修正

🚀1.算法介绍
继2023年1月YOLOv8正式发布一年多以后,YOLOv9终于来了!👋我们知道,YOLO是一种基于图像全局信息进行预测的目标检测算法。自2015年Joseph Redmon、Ali Farhadi等人提出初代模型以来,领域内的研究者们已经对YOLO进行了多次更新迭代,模型性能越来越强大。💪
此次,YOLOv9由中国台湾Academia Sinica、台北科技大学等机构联合开发,相关的论文已经放出。💞
如今的深度学习方法重点关注如何设计最合适的目标函数,从而使得模型的预测结果能够最接近真实情况。同时,必须设计一个适当的架构,可以帮助获取足够的信息进行预测。然而,现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。因此,YOLOv9深入研究了数据通过深度网络传输时数据丢失的重要问题,即信息瓶颈和可逆函数。
研究者提出了可编程梯度信息(programmable gradient information,PGI) 的概念来应对深度网络实现多个目标所需要的各种变化。PGI可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。
此外,研究者基于梯度路径规划设计了一种新的轻量级网络架构,即通用高效层聚合网络(Generalized Efficient Layer Aggregation Network,GELAN)。该架构证实了PGI可以在轻量级模型上取得优异的结果。
研究者在基于MS COCO数据集的目标检测任务上验证所提出的GELAN和PGI。结果表明,与基于深度卷积开发的SOTA方法相比,GELAN仅使用传统卷积算子即可实现更好的参数利用率。
对于PGI而言,它的适用性很强,可用于从轻型到大型的各种模型。我们可以用它来获取完整的信息,从而使从头开始训练的模型能够比使用大型数据集预训练的SOTA模型获得更好的结果。下图展示了一些比较结果。👇
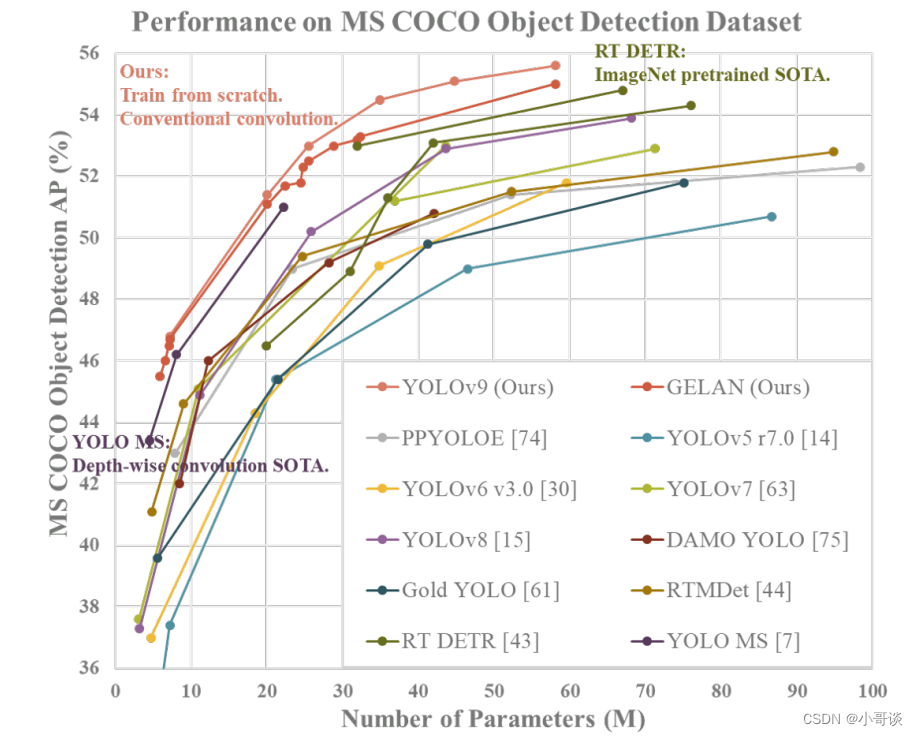
对于新发布的YOLOv9,曾参与开发YOLOv7、YOLOv4、Scaled-YOLOv4 和DPT的Alexey Bochkovskiy给予了高度评价,表示YOLOv9优于任何基于卷积或transformer的目标检测器。
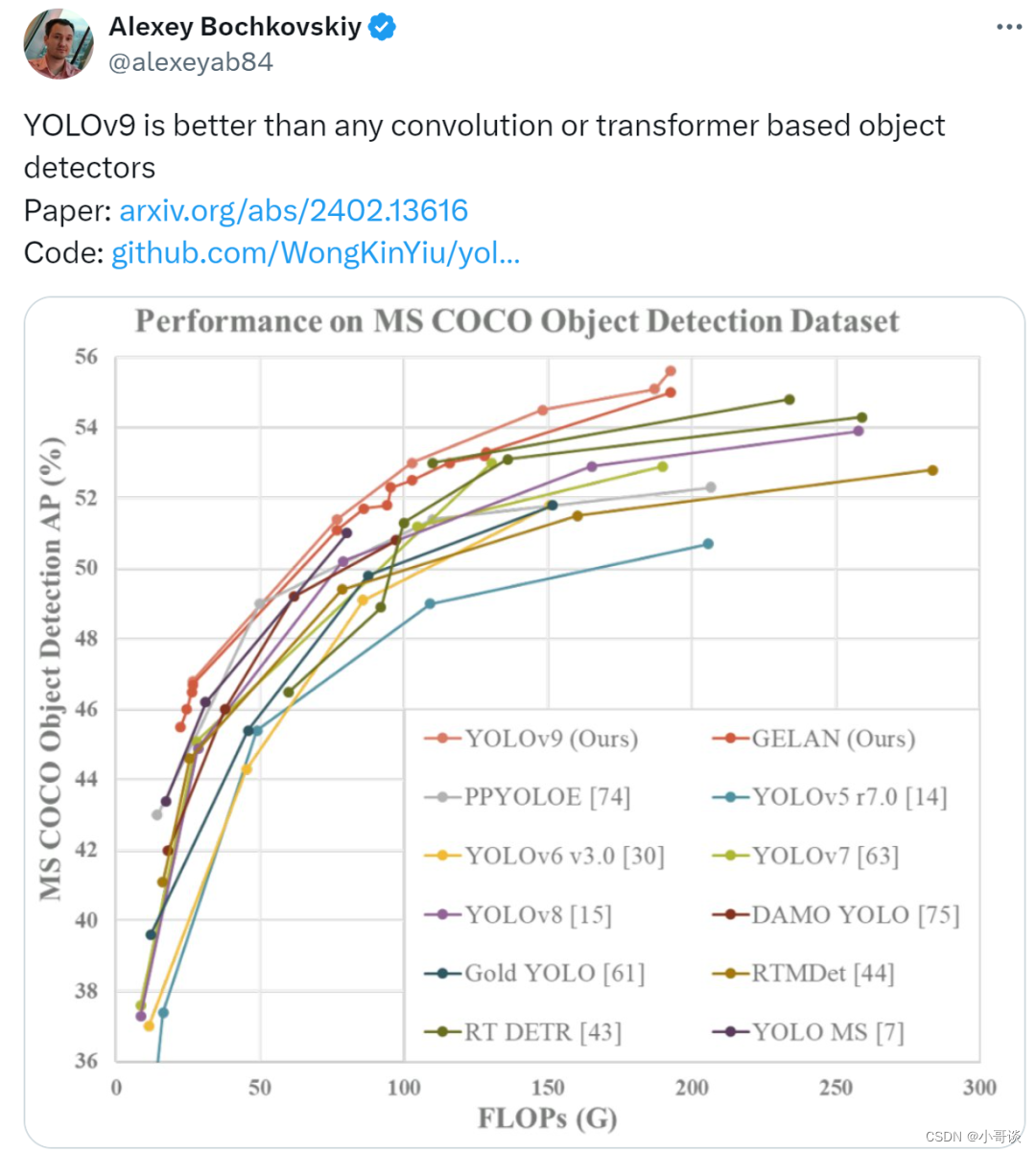
YOLOv9看起来就是新的SOTA实时目标检测器,他自己的自定义训练教程也在路上了。✅
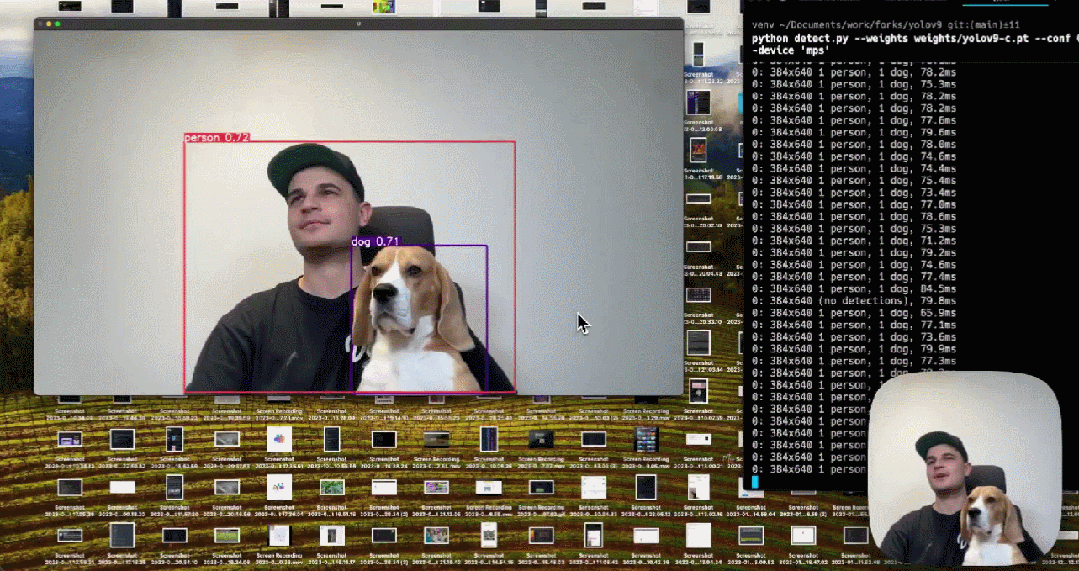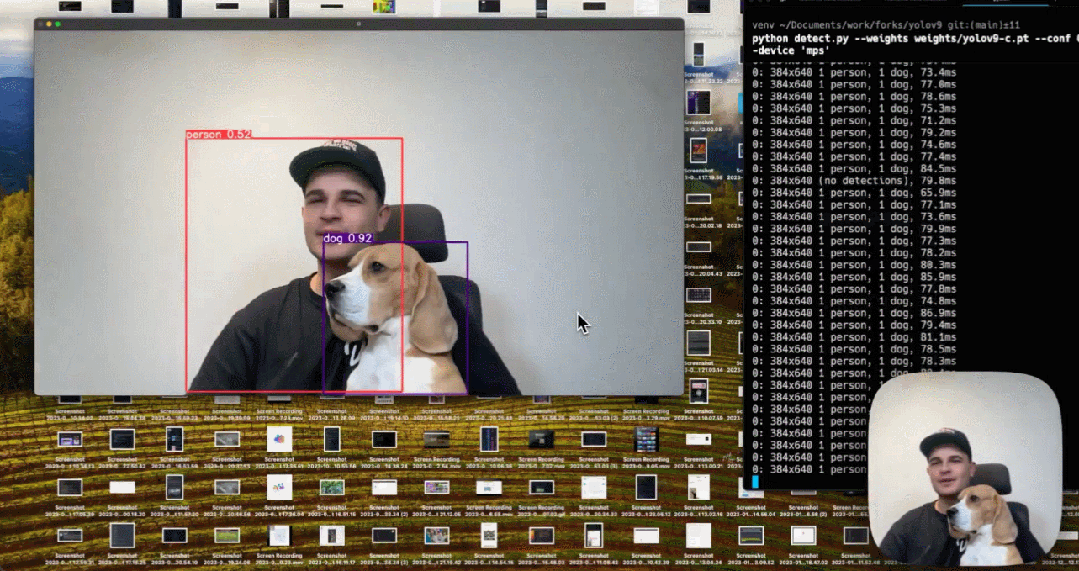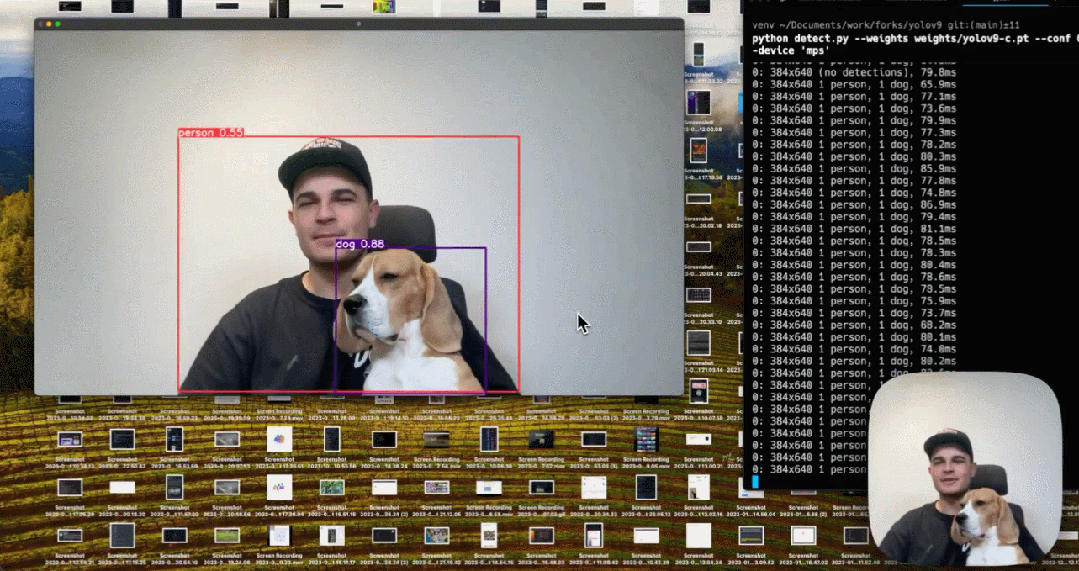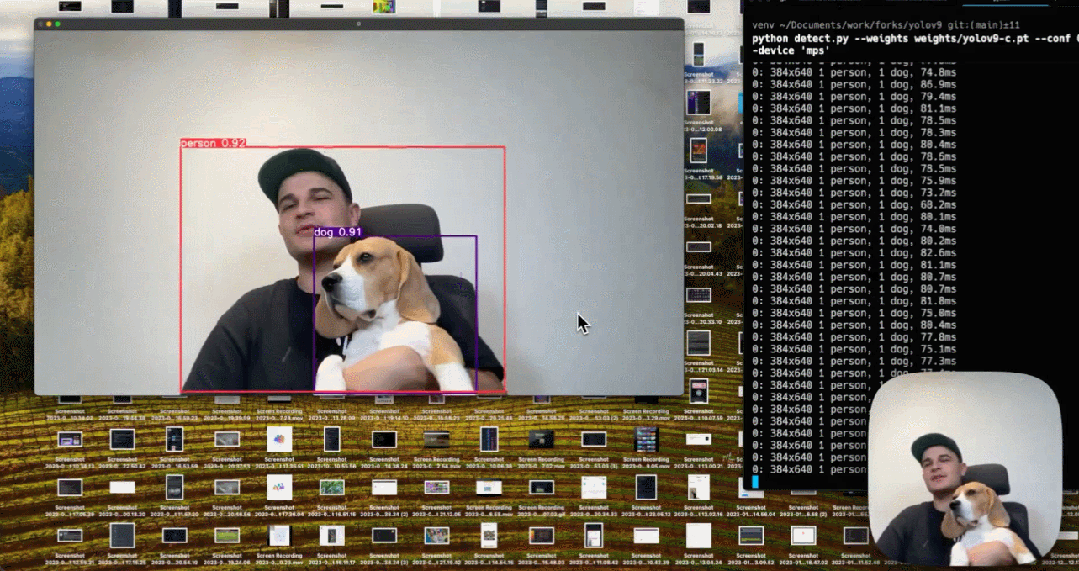
来源:https://twitter.com/skalskip92/status/1760717291593834648

论文题目:《YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information》
论文地址: https://arxiv.org/abs/2402.13616
代码实现: GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
YOLOv9官方发布的代码存在一些问题,作者已经进行了修正并测试成功,需要完整代码的可在我的“资源”中下载。
🚀2.数据标注
利用labelimg或者make sense软件来标注数据,关于如何使用labelimg或者make sense软件来为自己的数据集打上标签,请参考作者专栏文章:👇

说明:♨️♨️♨️
数据标注工具的使用教程:
YOLOv5入门实践(1)— 手把手教你使用labelimg标注数据集(附安装包+使用教程)
YOLOv5入门实践(2)— 手把手教你使用make sense标注数据集(附工具地址+使用教程)
🚀3.模型训练
第1步:准备数据集
将数据集放在datasets文件夹中。datasets属于放置数据集的地方,位于PycharmProjects中,C:\Users\Lenovo\PycharmProjects中(这是我的电脑位置,跟你的不一定一样,反正位于PycharmProjects中,如果没有,可自行创建),属于项目的同级文件夹。具体如下图所示:
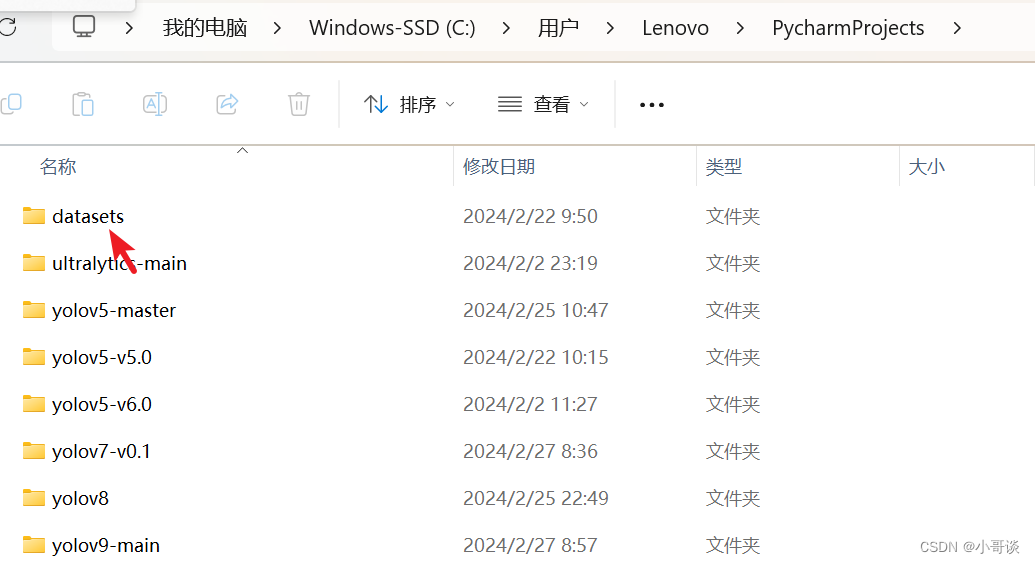
打开datasets文件夹,可以看到本次安全帽训练所使用的数据集。
安全帽佩戴检测数据集是我手动标注好的,可以在我的博客“资源”中下载。
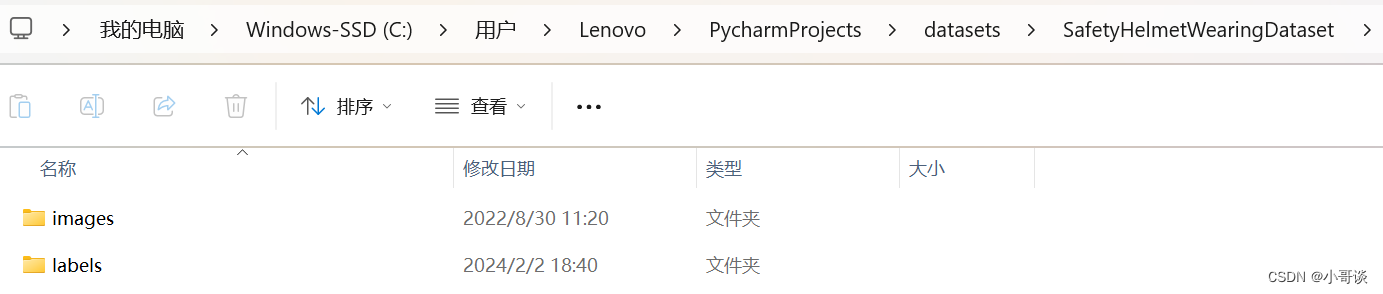
打开数据集文件,我们会看到数据集文件包括images和labels两个文件夹,其中,images放的是数据集图片,包括train和val两个文件夹,labels放的是经过labelimg标注所生成的标签,也包括train和val两个文件夹。💑
关于此处数据集的逻辑关系,用一张图总结就是:⬇️⬇️⬇️

第2步:创建yaml文件
打开pycharm,选择yolov9-main项目源码文件,在data文件下新建一个helmet.yaml,如下图所示:👇
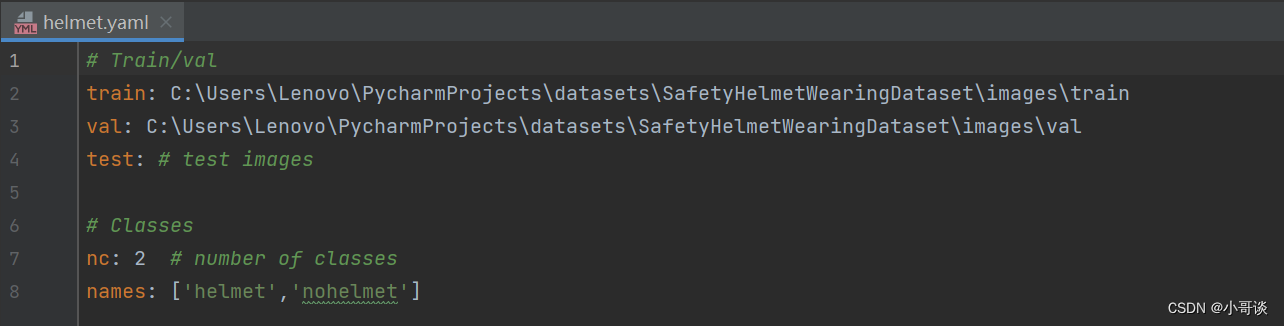
打开helmet.yaml,按照如下图所示的进行配置:
说明:♨️♨️♨️
1.train和val为绝对路径地址,可根据自己数据集的路径地址自行设置。
2.nc指的是分类,即模型训练结果分类,此处为在用labelimg或者make sense为数据集标注时候确定。
3.由于本次进行的是安全帽佩戴检测模型训练,所以分两类,分别是:helmet(佩戴安全帽)和nohelmet(不佩戴安全帽)
打开coco.yaml文件,可以看到里面写的是相对路径,和我们的写法不同,但是都可以使用,据我所知还有很多种数据集读取方式:
path: ../datasets/coco # dataset root dir
train: train2017.txt # train images (relative to 'path') 118287 images
val: val2017.txt # val images (relative to 'path') 5000 images
test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794# Classes
names:0: person1: bicycle2: car3: motorcycle4: airplane5: bus6: train7: truck8: boat9: traffic light10: fire hydrant11: stop sign12: parking meter13: bench14: bird15: cat16: dog17: horse18: sheep19: cow20: elephant21: bear22: zebra23: giraffe24: backpack25: umbrella26: handbag27: tie28: suitcase29: frisbee30: skis31: snowboard32: sports ball33: kite34: baseball bat35: baseball glove36: skateboard37: surfboard38: tennis racket39: bottle40: wine glass41: cup42: fork43: knife44: spoon45: bowl46: banana47: apple48: sandwich49: orange50: broccoli51: carrot52: hot dog53: pizza54: donut55: cake56: chair57: couch58: potted plant59: bed60: dining table61: toilet62: tv63: laptop64: mouse65: remote66: keyboard67: cell phone68: microwave69: oven70: toaster71: sink72: refrigerator73: book74: clock75: vase76: scissors77: teddy bear78: hair drier79: toothbrush# Download script/URL (optional)
download: |from utils.general import download, Path# Download labels#segments = True # segment or box labels#dir = Path(yaml['path']) # dataset root dir#url = 'https://github.com/WongKinYiu/yolov7/releases/download/v0.1/'#urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels#download(urls, dir=dir.parent)# Download data#urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images# 'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images# 'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)#download(urls, dir=dir / 'images', threads=3)第3步:下载预训练权重
打开YOLOv9官方仓库地址,可以根据需要下载相应的预训练权重。
预训练权重下载地址:GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
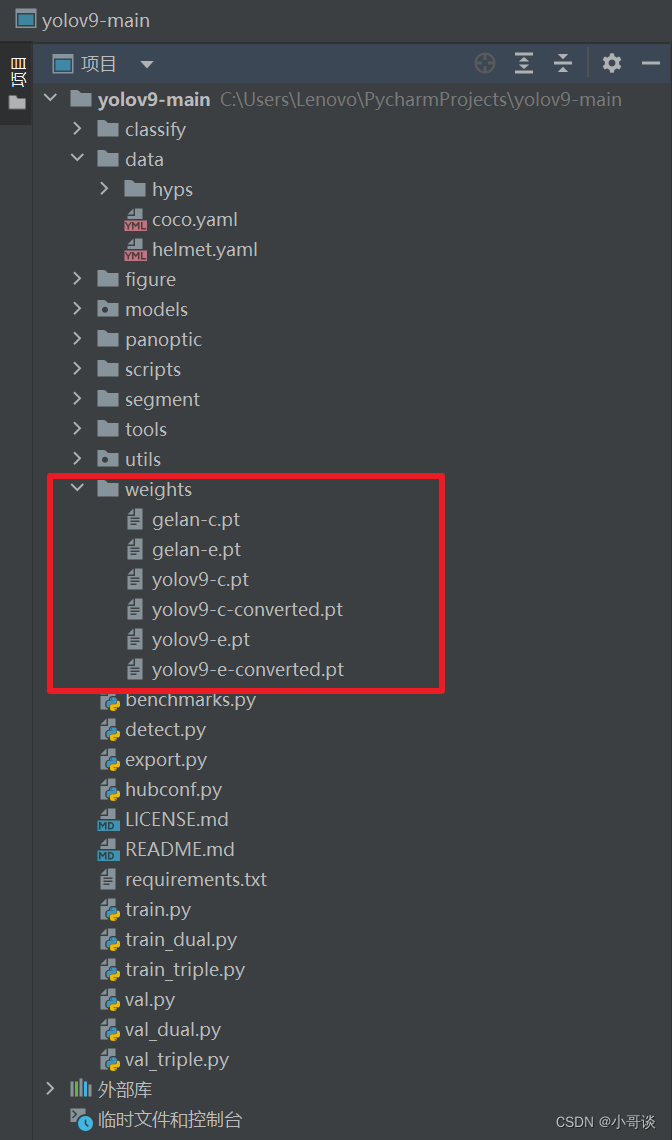
下载完毕后,在主目录下新建weights文件夹,然后将下载的权重文件放在weights文件夹下。具体如下图所示:👇
第4步:配置路径
在项目里找到train.py文件,在'--weights'参数的default处设置为'weights/yolov9-c.pt',在'--cfg'参数的default处设置为'models/detect/yolov9-c.yaml',在'--data'参数的efault处设置为前面所创建的安全帽检测的helmet.yaml文件的路径。关于此处的设置具体如下图所示:👇
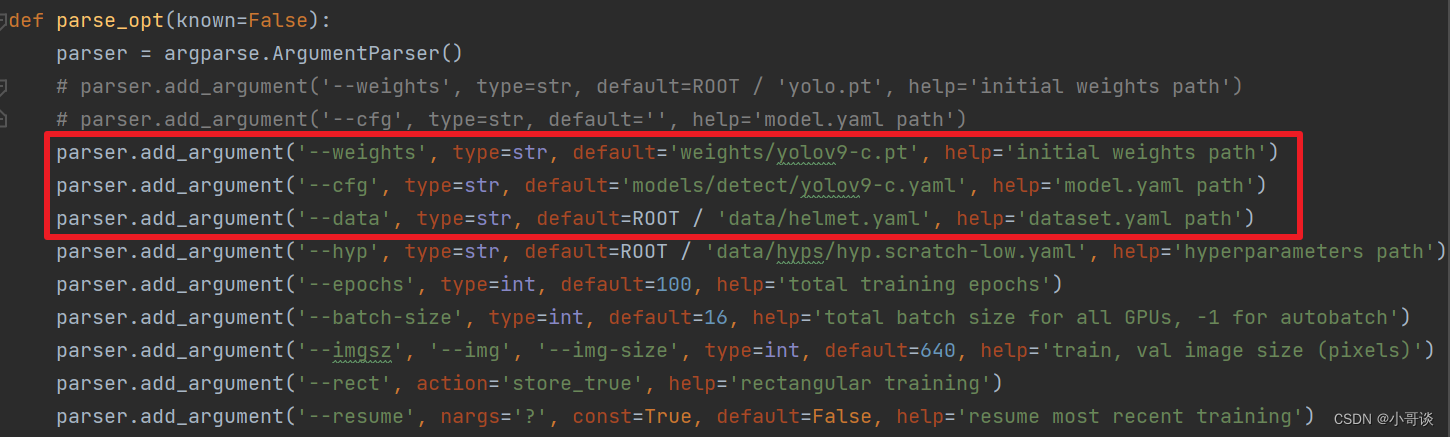
备注:此处根据具体情况进行设置。
第5步:调节参数
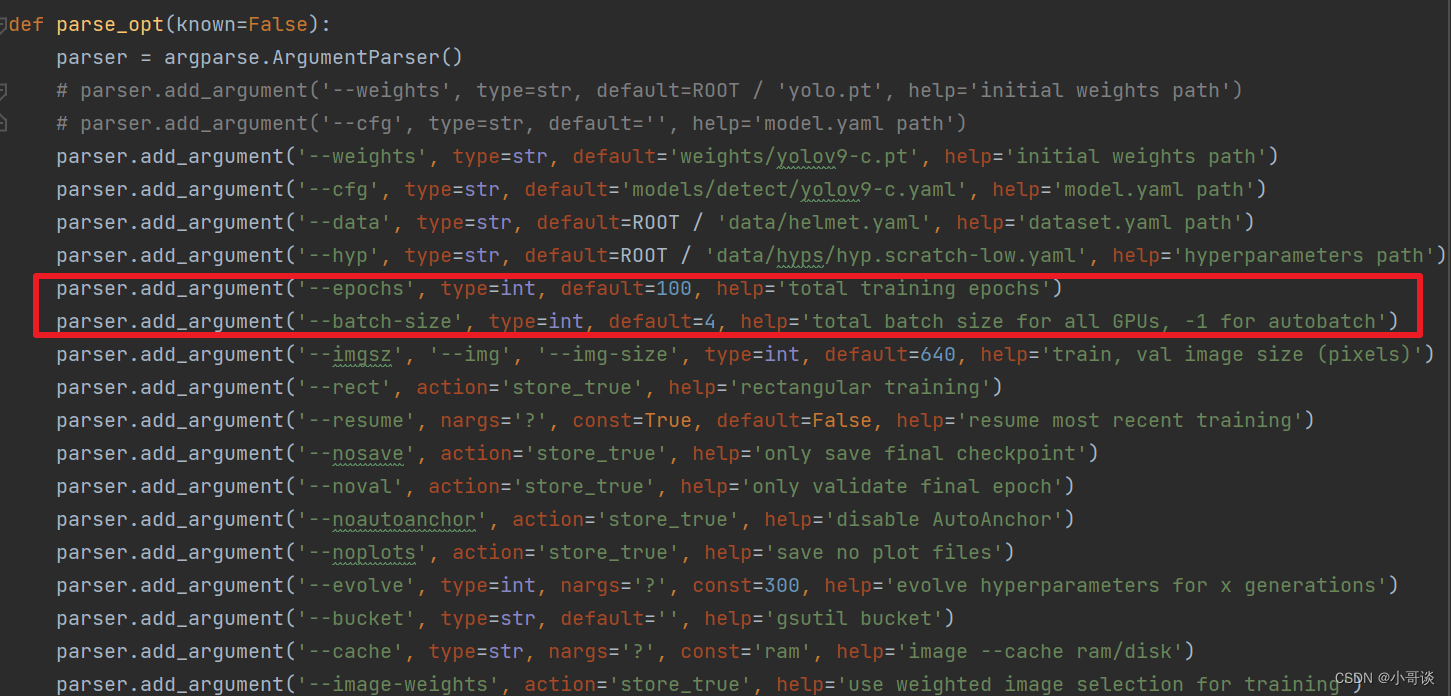
- 将epochs中的参数设置为100,表示需经过100轮训练。
- batch-size表示一次训练所抓取的数据样本数量,其大小影响训练速度和模型优化,此处将其参数设置为4。
备注:此处根据具体情况进行设置。
第6步:开始训练
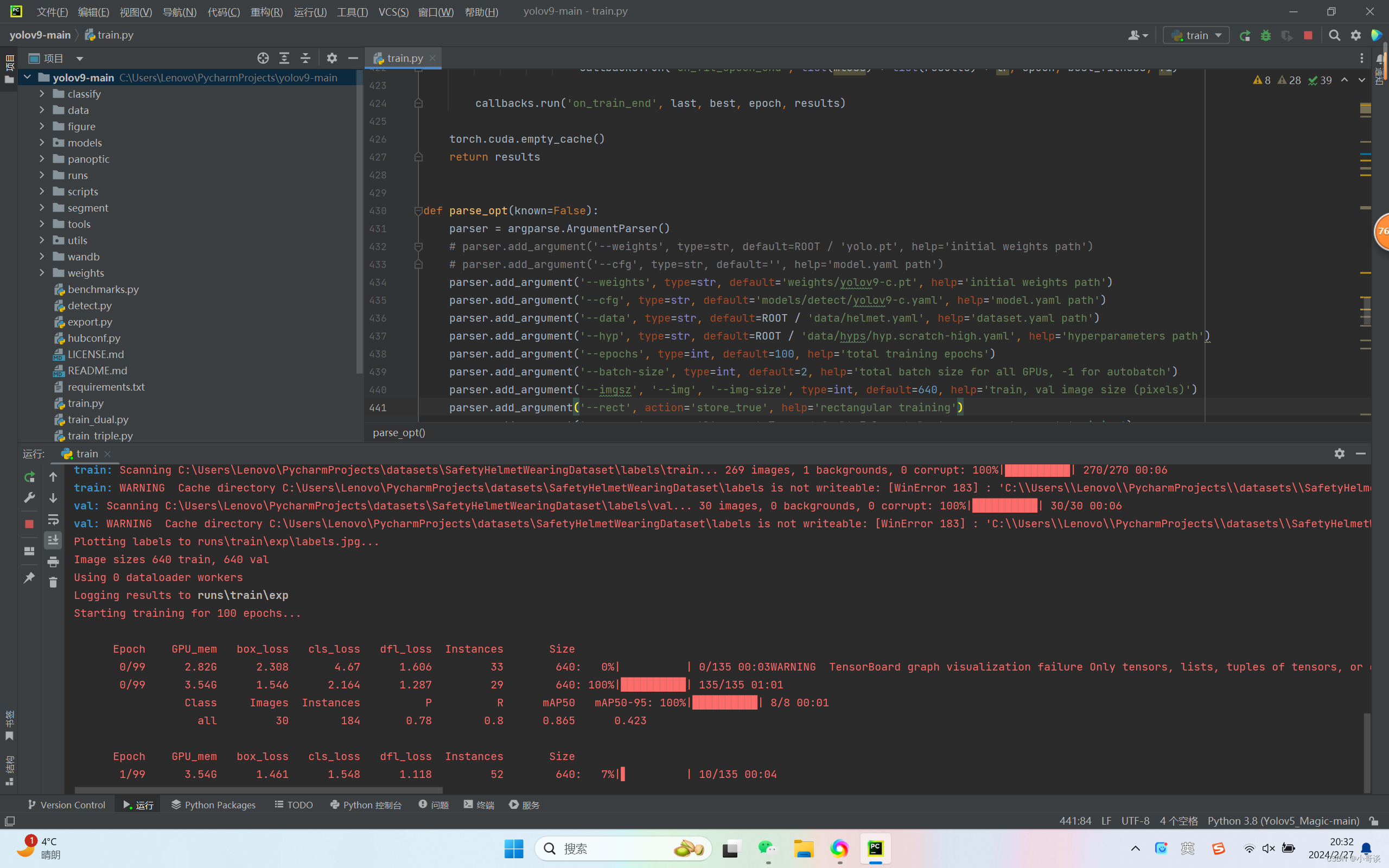
在train.py中点击“运行”。具体运行结果如下图所示:👇
训练完毕,训练结果如下图所示:
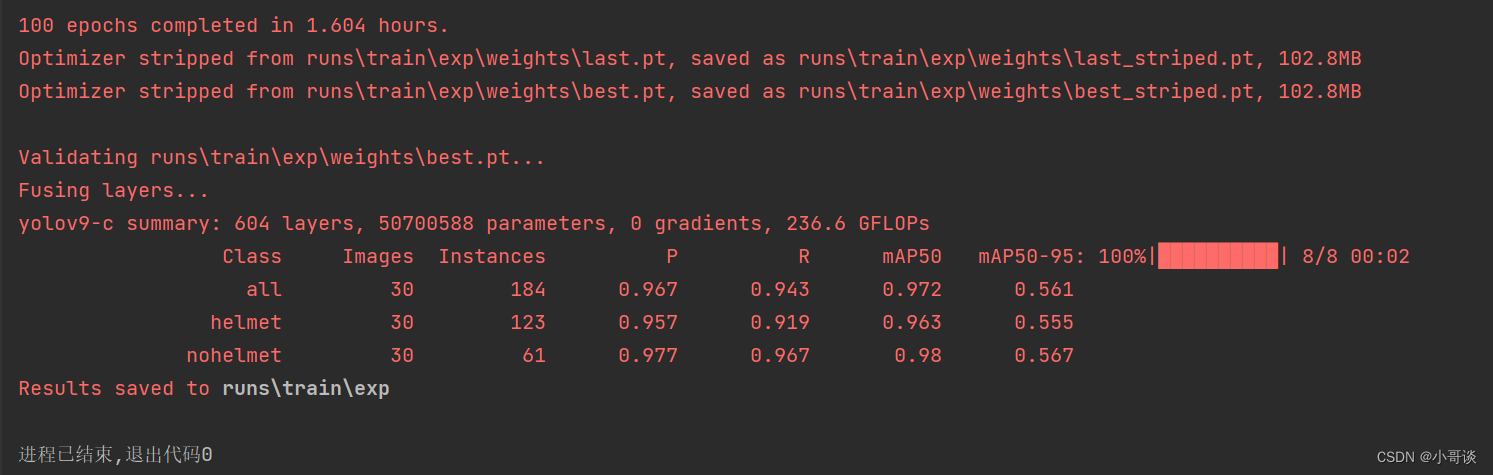

由结果可知,训练结果还是很不错的。👏👏👏
🚀4.源码修正
我在进行模型训练的过程中,发现作者所上传的源码存在部分错误,现修正如下:👇
修正1:
2024.2.22日官网发布的代码存在bug,将utils文件下loss_tal.py脚本中的第167行中的p改为p[0]或p[1],改完能运行。(bug产生的原因是列表导致后面方法错误,具体原因正在读源码!)
原代码:
feats = p[1] if isinstance(p, tuple) else p修改为:
feats = p[1] if isinstance(p, tuple) else p[0]或者
feats = p[1] if isinstance(p, tuple) else p[1]修正2:
将train.py文件参数第4行的'--hyp'参数修改,即:
原代码:
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')修改为
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-high.yaml', help='hyperparameters path')说明:关于更多YOLOv9内容, 欢迎关注后续系列精彩文章!~🍉 🍓 🍑 🍈 🍌 🍐

这篇关于模型训练篇 | yolov9来了!手把手教你如何用yolov9训练自己的数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




