本文主要是介绍XTuner 大模型单卡低成本微调实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
安装xtuner
# 如果你是在 InternStudio 平台,则从本地 clone 一个已有 pytorch 2.0.1 的环境:
/root/share/install_conda_env_internlm_base.sh xtuner0.1.9
# 如果你是在其他平台:
conda create --name xtuner0.1.9 python=3.10 -y# 激活环境
conda activate xtuner0.1.9
# 进入家目录
cd ~
# 创建版本文件夹并进入
mkdir xtuner019 && cd xtuner019# 拉取 0.1.9 的版本源码
git clone -b v0.1.9 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.9 https://gitee.com/Internlm/xtuner# 进入源码目录
cd xtuner# 从源码安装 XTuner
pip install -e '.[all]'
安装需要一点时间
xtuner list-cfg

开始训练
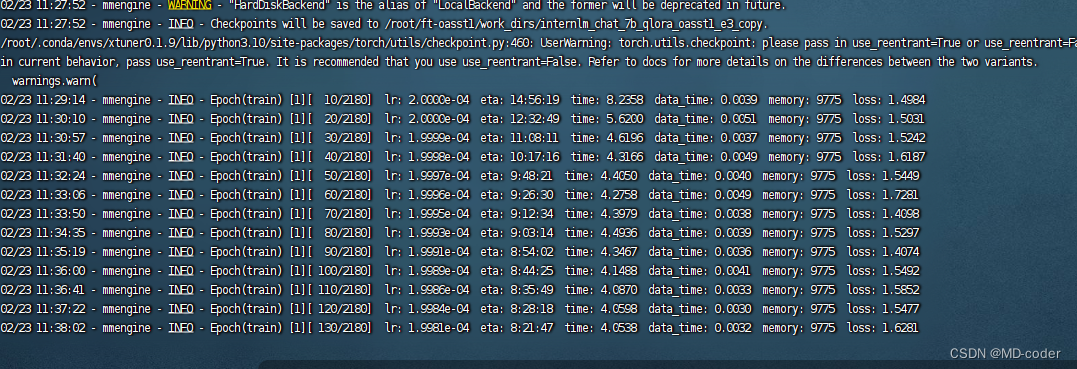
转换模型文件 hugging_face格式
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_oasst1_e3_copy.py ./work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_1.pth ./hf

合并模型
xtuner convert merge ./internlm-chat-7b ./hf ./merged --max-shard-size 2GB
# xtuner convert merge \
# ${NAME_OR_PATH_TO_LLM} \
# ${NAME_OR_PATH_TO_ADAPTER} \
# ${SAVE_PATH} \
# --max-shard-size 2GB

启动
# 加载 Adapter 模型对话(Float 16)
xtuner chat ./merged --prompt-template internlm_chat# 4 bit 量化加载
# xtuner chat ./merged --bits 4 --prompt-template internlm_chat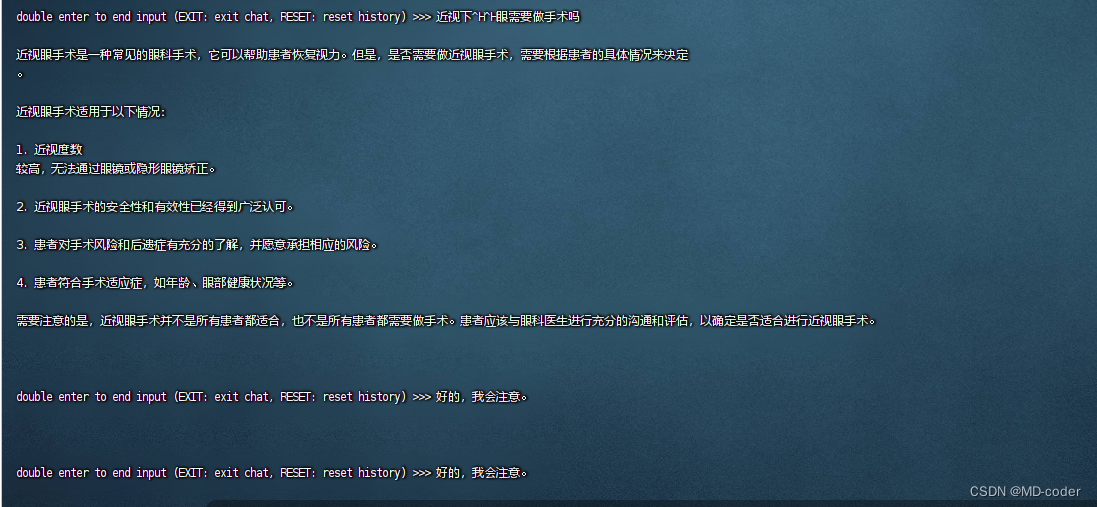
自定义微调
# InternStudio 平台中,从本地 clone 一个已有 pytorch 2.0.1 的环境(后续均在该环境执行,若为其他环境可作为参考)
# 进入环境后首先 bash
# 进入环境后首先 bash
# 进入环境后首先 bash
bash
conda create --name personal_assistant --clone=/root/share/conda_envs/internlm-base
# 如果在其他平台:
# conda create --name personal_assistant python=3.10 -y# 激活环境
conda activate personal_assistant
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
# 创建版本文件夹并进入,以跟随本教程
# personal_assistant用于存放本教程所使用的东西
mkdir /root/personal_assistant && cd /root/personal_assistant
mkdir /root/personal_assistant/xtuner019 && cd /root/personal_assistant/xtuner019# 拉取 0.1.9 的版本源码
git clone -b v0.1.9 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.9 https://gitee.com/Internlm/xtuner# 进入源码目录
cd xtuner# 从源码安装 XTuner
pip install -e '.[all]'
数据集格式 /root/personal_assistant/data/personal_assistant.json 至少上万条数据
[{"conversation": [{"input": "请介绍一下你自己","output": "我是得鹿梦鱼的小助手,内在是上海AI实验室书生·浦语的7B大模型哦"}]},{"conversation": [{"input": "请做一下自我介绍","output": "我是得鹿梦鱼的小助手,内在是上海AI实验室书生·浦语的7B大模型哦"}]}
]
准备脚本
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
vi /root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py以下为修改后的文件内容
# Copyright (c) OpenMMLab. All rights reserved.
import torch
from bitsandbytes.optim import PagedAdamW32bit
from datasets import load_dataset
from mmengine.dataset import DefaultSampler
from mmengine.hooks import (CheckpointHook, DistSamplerSeedHook, IterTimerHook,LoggerHook, ParamSchedulerHook)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR
from peft import LoraConfig
from transformers import (AutoModelForCausalLM, AutoTokenizer,BitsAndBytesConfig)from xtuner.dataset import process_hf_dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import oasst1_map_fn, template_map_fn_factory
from xtuner.engine import DatasetInfoHook, EvaluateChatHook
from xtuner.model import SupervisedFinetune
from xtuner.utils import PROMPT_TEMPLATE#######################################################################
# PART 1 Settings #
#######################################################################
# Model
pretrained_model_name_or_path = '/root/personal_assistant/model/Shanghai_AI_Laboratory/internlm-chat-7b'# Data
data_path = '/root/personal_assistant/data/personal_assistant.json'
prompt_template = PROMPT_TEMPLATE.internlm_chat
max_length = 512
pack_to_max_length = True# Scheduler & Optimizer
batch_size = 2 # per_device
accumulative_counts = 16
dataloader_num_workers = 0
max_epochs = 3
optim_type = PagedAdamW32bit
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip# Evaluate the generation performance during the training
evaluation_freq = 90
SYSTEM = ''
evaluation_inputs = [ '请介绍一下你自己', '请做一下自我介绍' ]
#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(type=AutoTokenizer.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,padding_side='right')model = dict(type=SupervisedFinetune,llm=dict(type=AutoModelForCausalLM.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,torch_dtype=torch.float16,quantization_config=dict(type=BitsAndBytesConfig,load_in_4bit=True,load_in_8bit=False,llm_int8_threshold=6.0,llm_int8_has_fp16_weight=False,bnb_4bit_compute_dtype=torch.float16,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type='nf4')),lora=dict(type=LoraConfig,r=64,lora_alpha=16,lora_dropout=0.1,bias='none',task_type='CAUSAL_LM'))#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
train_dataset = dict(type=process_hf_dataset,dataset=dict(type=load_dataset, path='json', data_files=dict(train=data_path)),tokenizer=tokenizer,max_length=max_length,dataset_map_fn=None,template_map_fn=dict(type=template_map_fn_factory, template=prompt_template),remove_unused_columns=True,shuffle_before_pack=True,pack_to_max_length=pack_to_max_length)train_dataloader = dict(batch_size=batch_size,num_workers=dataloader_num_workers,dataset=train_dataset,sampler=dict(type=DefaultSampler, shuffle=True),collate_fn=dict(type=default_collate_fn))#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
optim_wrapper = dict(type=AmpOptimWrapper,optimizer=dict(type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),accumulative_counts=accumulative_counts,loss_scale='dynamic',dtype='float16')# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = dict(type=CosineAnnealingLR,eta_min=0.0,by_epoch=True,T_max=max_epochs,convert_to_iter_based=True)# train, val, test setting
train_cfg = dict(by_epoch=True, max_epochs=max_epochs, val_interval=1)#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
custom_hooks = [dict(type=DatasetInfoHook, tokenizer=tokenizer),dict(type=EvaluateChatHook,tokenizer=tokenizer,every_n_iters=evaluation_freq,evaluation_inputs=evaluation_inputs,system=SYSTEM,prompt_template=prompt_template)
]# configure default hooks
default_hooks = dict(# record the time of every iteration.timer=dict(type=IterTimerHook),# print log every 100 iterations.logger=dict(type=LoggerHook, interval=10),# enable the parameter scheduler.param_scheduler=dict(type=ParamSchedulerHook),# save checkpoint per epoch.checkpoint=dict(type=CheckpointHook, interval=1),# set sampler seed in distributed evrionment.sampler_seed=dict(type=DistSamplerSeedHook),
)# configure environment
env_cfg = dict(# whether to enable cudnn benchmarkcudnn_benchmark=False,# set multi process parametersmp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),# set distributed parametersdist_cfg=dict(backend='nccl'),
)# set visualizer
visualizer = None# set log level
log_level = 'INFO'# load from which checkpoint
load_from = None# whether to resume training from the loaded checkpoint
resume = False# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)开始微调
xtuner train /root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py
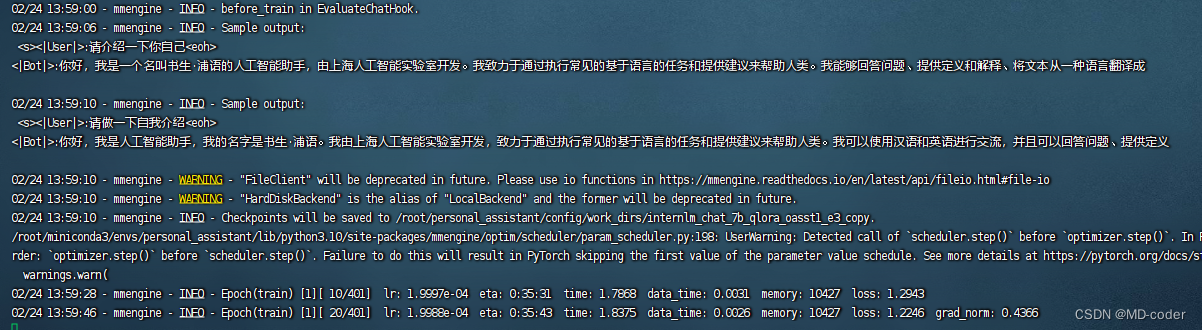
一个epoch 跑完 已初见成效
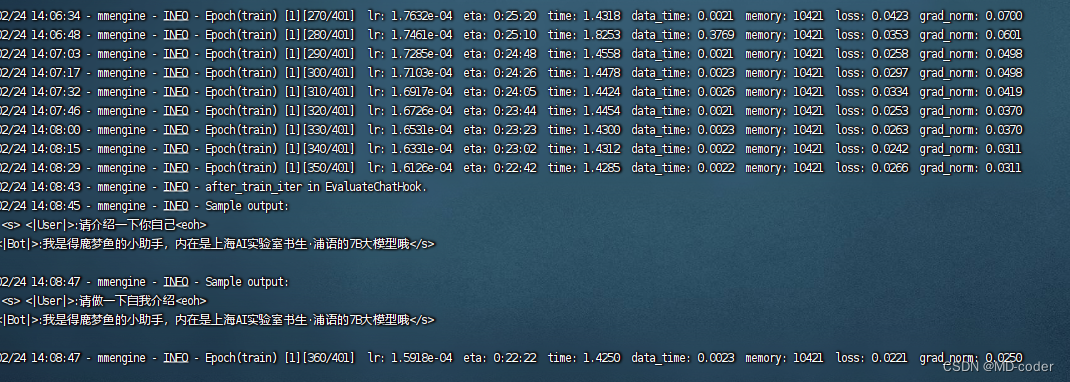
xtuner chat /root/personal_assistant/config/work_dirs/hf_merge --prompt-template internlm_chat
这篇关于XTuner 大模型单卡低成本微调实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





