本文主要是介绍leetcode 105. 从前序与中序遍历序列构造二叉树【构造二叉树】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原题链接:105. 从前序与中序遍历序列构造二叉树
题目描述:
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
输入输出描述:
示例 1:
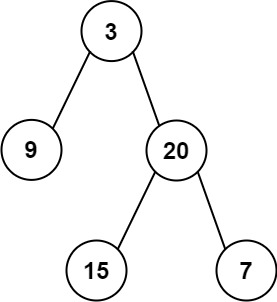
输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7] 输出: [3,9,20,null,null,15,7]
示例 2:
输入: preorder = [-1], inorder = [-1] 输出: [-1]
提示:
1 <= preorder.length <= 3000inorder.length == preorder.length-3000 <= preorder[i], inorder[i] <= 3000preorder和inorder均 无重复 元素inorder均出现在preorderpreorder保证 为二叉树的前序遍历序列inorder保证 为二叉树的中序遍历序列
解题思路:
题目要求我们根据前序遍历和中序遍历构造出这棵二叉树,下面画个图来分析一下:

每次在inorder中暴力找根结点的时间复杂度为O(n),我们可以先用一个哈希表记录inorder中所有数字的下标,就可以把这个找的过程优化到O(1),根据上述分析,直接递归构造即可,具体分析见代码处.
cpp代码如下:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {unordered_map<int, int> index;TreeNode* buildTree(vector<int>& preorder,vector<int>& inorder,int pre_left,int pre_right,int in_left,int int_right){if(pre_left>pre_right){ //空树,直接返回空return nullptr;}int v=preorder[pre_left]; //根结点是preorder第一个数TreeNode* root=new TreeNode(v); //建立根结点int pos=index[v]; //拿到根节点在inorder中的位置索引int leftLen=pos-in_left; //根据根结点在inorder中的位置索引计算当前子树的左子树的长度//构造当前子树的左子树root->left=buildTree(preorder,inorder,pre_left+1,pre_left+leftLen,in_left,pos-1);//构造当前子树的右子树root->right=buildTree(preorder,inorder,pre_left+leftLen+1,pre_right,pos+1,int_right);return root;}
public:TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {index.clear();int n=inorder.size();for(int i=0;i<n;i++){index[inorder[i]]=i; //用一个哈希表记录inorder中所有数字所在位置的索引}return buildTree(preorder,inorder,0,n-1,0,n-1); //直接递归构造}
};这篇关于leetcode 105. 从前序与中序遍历序列构造二叉树【构造二叉树】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







