本文主要是介绍内存计算研究进展-针对机器学习的近数据计算架构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
针对机器学习的近数据计算架构代表性工作有: Georgia Institute of Technology的BSSync (bounded staled sync) 和 Neurocube,Advanced Micro Devices 的 CoML,具体如下。
1 BSSync
BSSync指出,在并行实现的机器学习应用中,原子操作用来保障无锁状态下算法的收敛,但带来很大的同步开销,且同步产生的通信延迟不与占比大的计算延迟重叠。BSSync发现,在机器学习应用迭代收敛过程中,可以用未更新的中间数据进行计算,从而提出利用基于近数据计算的有边界一致性模型减少原子操作带来的延迟开销。图17是 BSSync系统结构,CPU 核里面增加了原子请求队列、控制寄存器以及区域表来实现边界一致性模型.实验显示,BSSync比机器学习应用在传统冯.诺依曼系统中的异步并行的实现快1.33倍。

2 Neurocube
Neurocube是一个针对神经网络计算设计的可编程、可扩展,且节能的近数据计算系统架构。图18 是 Neurocube架构,左边是普遍使用的NDC cube结构,右边是逻辑层设计。逻辑层采用了细粒度可编程的设计模型,以灵活支持祌经网络计算.其中,每 个 P E 有 多 个 M AC单元支持神经网络中最常用的乘加操作,同时还有存储权值的寄存器和缓存以及相应的计数器。

图19 是 Neurocube的执行流程.它首先将神经网络存储到NDC cube的存储单元中,包括每层数据、神经元状态、连接权值.当一个层处理好之后,与中央处理器交互一次,然后执行下一层。Neurocube通过对逻辑层硬件、数据映射方式、片上互联,以及编程方式的精心设计,使得祌经网络计算在NDC cube中能够高效执行。

实验显示,相比于GPU系统,Neurocube有 4 倍的每瓦计算效率提升,与 ASIC系统相比,灵活性更好、扩展能力更强。
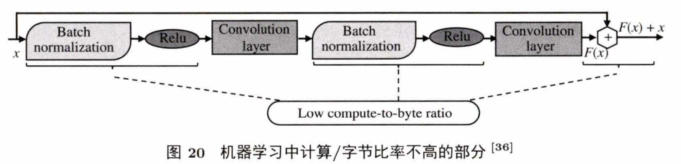
不同于针对机器学习设计的注重优化乘加(MAC) 操作的近数据计算系统,C oM L lM 提出,虽然包含MAC操作的卷积层等计算占整个机器学习过程的比例大,但这些计算是计算密集型的,数据复用性好,计算/字节比率高(即一个字节从内存中读出来之后用来计算的次数多);事实上,机器学习过程中,约32%的时间用于数据密集型计算,这些计算的计算/字节比率低。图 2 0 展示了神经网络中低计算/字节比率的计算部分。CoM L 将这些低计算/字节比率的计算部分放在近数据计算端,把MAC等操作放在主处理器上做。
实验显示,C oM L 在机器学习的数据密集型计算上的加速达到了 2 0 倍,总体有14%的性能提升。
参考文献
毛海宇,舒继武,李飞,等. 内存计算研究进展. 中国科学:信息科学,2021, 51: 173-206, doi: 10.1360/SSI-2020-0037 M ao H Y, Shu J W , Li F , et al. D evelopm ent of processing-in-m em ory (in C hinese). Sci Sin Inform , 2021, 51: 173-206, doi: 10.1360/SSI-2020-0037
这篇关于内存计算研究进展-针对机器学习的近数据计算架构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




