本文主要是介绍内存计算研究进展-通用的近数据计算架构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
通用的近数据计算架构方面代表性工作有: AMD Research的 TOP-PIM,Carnegie Mellon
Univeristy 的 TOM, University of Wisconsin-Madison 的 DRAMA 和 NDA,Seoul National
University 的 PEI ,IBM Research 的 AMC (active memory cube) 和基于多核 CPU 的近数据计算系统,Stanford University的 HRL ,Brown University为近数据计算设计的并发数据结构,
Georgia Institute of Technology 的 AxRAM 1321,以及 Chinese Academy of Sciences 的proPRAM,具体如下。
TOP-PIM提出了一种近数据计算的架构,如图 5 所示,存储单元不直接堆叠在中央处理器上,
而是堆叠在内存处理器上,与中央处理器进行交互. TOP-PIM 在选择内存处理器时,考虑了能耗和热量的限制,充分分析大量应用在性能和能耗方面的特征。TOP-PIM 认为面向吞吐量的GPU 核更适用于高带宽高数据并行的场景。

实验表明,在22nm的工艺下,TOP-PIM可以减少76%的能耗,且仅带来27%的性能损失。TOP-PIM 测试的不是某种特定类型的应用,无法对特定类型应用加速;另外,它将整个应用都放到内存计算中执行,而内存计算中的计算资源更适用于单指令多数据流的计算,难以支持复杂的多样的计算.因此,TOP-PIM 在性能上不如传统冯.诺依曼系统。
TOM 将代码分成多个块,通过编译器的静态分析,判断出适合放到内存计算中执行的块代码,
避免了把整个代码都放到内存计算模块中执行。TOM结构如图 6 所示,其大致结构与TOP-PIM相似,不同的是TOM支持各个NDC cube之间的通信。
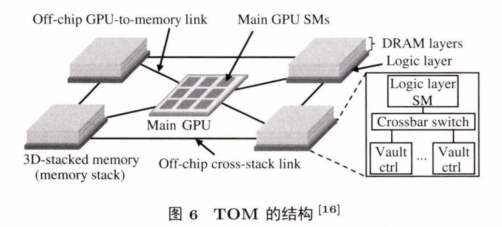
TOM的提出是为了解决大数据时代GPU与主存之间带宽小的问题,除了通过编译器静态分析代码块并选择合适的代码块放到内存计算中执行之外,TOM还分析预测了哪些数据会被放到内存计算中的代码块访问,并将这些数据放在相应代码块执行的NDC cube中,以此来减少各个NDC cube之间的通信. TOM中的代码分析和数据映射都对上层透明,程序员可非常方便地使用内存计算.实验显示,TOM平均能提高GPU的主流应用30%的性能。
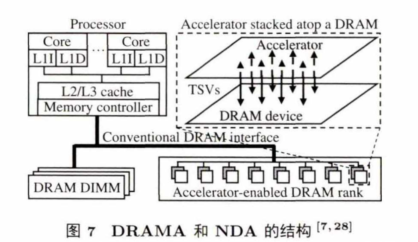
DRAMA和NDA与其他近数据计算架构不同,它们建立在商用的DRAM设备上,力求对现有商用3D 堆 叠 的 DRAM硬 件 (HMC和 HBM) 改动最小,并且对现在的存储系统架构改动最小。图7展示了 DRAMA和NDA 的结构,二者整体结构还是中央处理器通过总线和DRAM DIMM相连。不同的是,其中一部分 DRAM DIMM 使用了 堆叠在 DRAM 上面的 CGRA (coarse-grained reconfigurable army) 加速器,能够将数据密集型的操作放到此类近数据结构中进行处理.实验显示,这样的近数据处理结构能够带来3倍到60倍的性能提升,减少了 63%〜9 6 % 的系统能耗。
PEl提出了一套内存计算和现有系统结合的软硬件接口。

如图8 所示, PEI将内存计算指令计算单元(PCU) 放在每个主处理器核以及每个内存计算核上,使得指令可在主处理器端或内存计算端执行;同时还加入了内存计算管理单元(PMU),与 LLC (last level cache) 以及主存控制器相互合作。它的主旨是使用能够计算的存储指令和特殊指令实现简单的内存计算指令,供上层应用所用。在现有的顺序编程模型基础上,PEI加入硬件单元来监测数据的局部性,根据数据的局部性自动决定哪些操作在内存计算单元里执行.因此,内存计算系统能和现有的编程模型、缓存冲突处理机制,以及虚拟内存管理很好地协作。图9 和10分别给出了主处理器端和存储端内存计算指令的执行步骤,从中可以看出,PEI能和现有的系统结构很好地协作。


AMC是一个面向百亿兆级超级计算机(•秒 钟 执 行 l 〇i8 运算)设计的内存计算系统,图11是其系统结构以及详细参数配置。
AMC在设计NDC cube的逻辑层时,全方面考虑了常用科学应用的计算需求和百亿兆级计算机系统的低功耗需求,力求最大化有限面积的利用率和能效比。同时, AMC通过软硬件接口将硬件微结构暴露给上层软件,允许软件针对性能需求调整应用参数,支持软件根据操作系统特点配置和调度AM C中的资源。AMC使 用 OpenMP4.0作为内存计算中节点粒度的编程接口,相应编译器编译好程序供AMC执行。
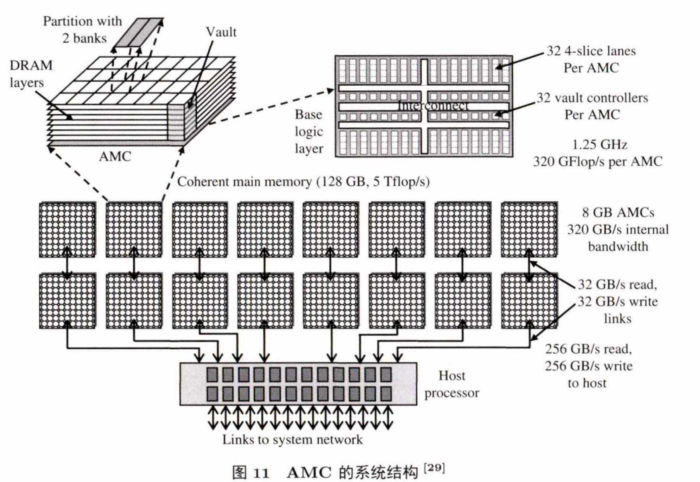
实验显示,AMC的内部带宽比传统中央处理器到主存的带宽大一个数量级;此外,AMC比传统处理器计算效率高一个数量级,能以很高并行度执行负载的重要部分,其能耗比传统系统一半还少. AMC验证了内存计算比将存储移动到中央处理器端的模式效率更高。
Vermij等提出了一个基于多核CPU的近数据计算系统,以支持近数据计算和现有系统的结合,
其结构如图12所示。

他们重新考虑了内存计算中的关键问题,如数据冲突、数据排布、通信、地址映射和编程模型等,并实现了一个基于软件和硬件的模拟器.实验表明,他们所提出的系统在GraPh500测试中与CPU系统相比,有1.5倍的性能提升。
HRL针对NDC cube逻辑层设计时,片上功耗和面积限制与高带宽和充足计算量的矛盾,提
出了可重构的逻辑阵列,能够灵活适用于大量的数据密集型应用。HRL发现,ASIC的设计性能好但缺少灵活性,无法支持大量应用。FPGA 和 CGRA通过可编程性提供了充足的灵活度。但是FPGA是以比特为粒度的计算单元和互联单元可编程的硬件,片上面积开销大;CGRA 能支持复杂数据流的强大互联,能 耗 比 FPG A 更高,在特殊计算和不规则数据上灵活度低,性能不佳。因此,HRL提出了混合可重构的逻辑阵列,用作NDC cube的逻辑层,包含了 FPGA 块 和 CGRA块 . 图 13 呈现了 HRL阵列结构,其中, FU (function unit) 是 用 类 CGRA块实现的,保证面积和能效比,能够支持数学运算和逻辑操作,包括加法、减法、乘法,和比较操作; CLB (configurable logic block) 是 用 类 FPG A 块实现的,用来实现一些不规则的控制逻辑和特殊函数(比如神经网络中的激活函数); OMB (output multiplexerblock) 是由多个多工器组成的,放置在靠近输出的位置,用来支持计算分支,例如树形、瀑布型,和并行型计算,是一种能同时节省片上面积和能耗开销的分支实现方式。另外,HRL没有配置类似FPGA的 BRAM 缓存,因为内存计算应用通常数据局部性差,大缓存是额外负担,不能提高系统的效率.如上所述,HRL 综合了 FPGA 能耗低和CGRA面积利用率高的优点,比基于FPGA的NDC系统性能高 2.2倍,比基于CGRA 的NDC系统性能髙1.7倍。

Liu等提出了适应于近数据计算的并发数据结构。他们发现,现在的服务器集群中通常有几百个核,并发数据结构在吞吐和扩展性方面优于传统的顺序数据结构.因此,近数据计算系统如何支持并发数据结构,以及并发数据结构如何利用近数据计算的优势,成为研究重点。Liu 等发现,并发数据结构性能优于普通的近数据计算的数据结构;另外,利用如数据融合、数据分块、流水线等技术面向近数据计算设计的并发数据结构,性能优于传统CPU 中的并发数据结构。
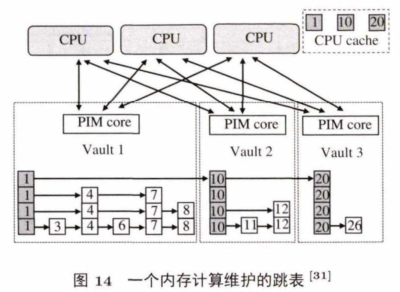
图14展示了他们设计的跳表结构实例,以及该结构在近数据计算系统中的映射. 在这个例子中,跳表被分成3部分存储到3个拱中,每个部分都以哨兵点开头,且哨兵点在CPU端有一份拷贝.除此之外,他们还实现了针对近数据计算设计的链表,先进先出队列和管道,在性能上优于现有的面向传统CPU系统的相关数据结构。
Yazdanbakhsh等人为将加速器集成到NDC cube中极具挑战,需要加速器低能耗,占用面积小,还要支撑多样化的应用。他们提出AxRAM,利 用 G PU 应用的可近似性,将不同区域代码中的计算转化成乘加(multiply-accumulate operation,MAC) 等近似算子。AxRAM用单一的算子近似应用中的操作,从 而 使 NDC cu b e中逻辑层设计简单、能耗低、占面积小。图15展示了AxRAM的执行流程。
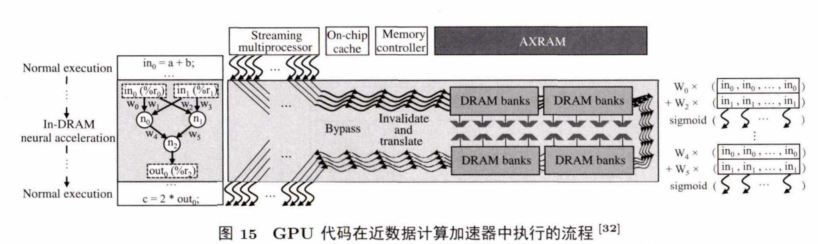
为了保持GPU的单指令多数据流的执行特性,近数据计算端用多个M AC近似单元绕GPU翻译并执行命令,这样做不需要改变DRAM的内部结构且不产生额外的内存开销.实验结果显示,与传统 GPU 系统相比,AxRAM平均取得了 2.6倍的性能提升以及13.3倍的能耗节约,而只带来了 2.1%的面积开销。
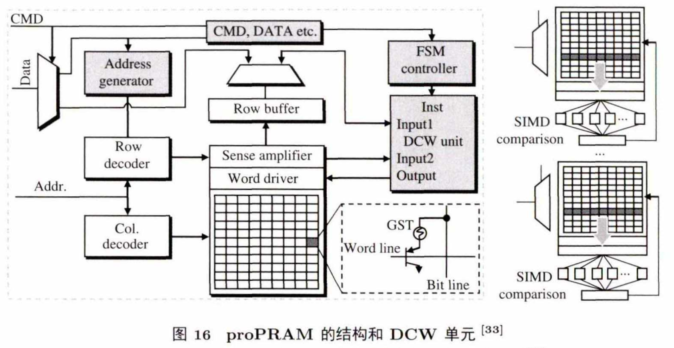
proPRAM是少数 不 基 于 3D 堆叠结构的近数据计算架构. 它充分利用了 N V M 中的基础逻
辑单元实现近数据计算,例如数据比较写(data-comparison write,DCW) 单兀,翻 转 写 (Flip-n-Write) 单元等对SET/RESET操作非常关键的单元(如图16所示,左边是 proPRAM 中的硬件结构,右边是DCW单元).proPRAM 对硬件结构改动微小,且改动对上层应用不可见,能很好地支持数据密集型操作,与 C P U 系统相比,在数据密集型应用上能取得1 5 倍的能耗节约。
这篇关于内存计算研究进展-通用的近数据计算架构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



