本文主要是介绍【附源码+Pybind + Cython Python性能提升方案】该拿什么拯救你,Slow Python,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
Cython介绍
性能比对
纯C++
Pybind11
Python
Cython
总结
循环机制
算数操作
内存分配
更多情况
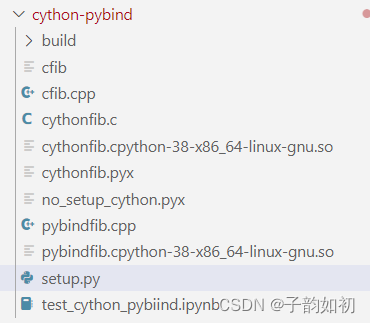
在做深度学习部署以及加速过程中,性能计算是非常重要的,这也是Python的一大痛点,本文主要介绍各种Python加速的方法并且也抛砖引玉,阐述了Why python so slow。整体测试代码目录如下
Cython介绍
简单来说Cython适合以下场景
1. 因为某些需求导致不得不编写一些多重嵌套的循环,而这些循环如果用 C 语言来实现会快几百倍,但是不熟悉 C 或者不知道 Python 如何与 C 进行交互
2. 项目组规定只能使用 Python 语言,解释器只能 CPython
3. Python 是一门动态语言,但希望至少在数字计算方面,能够加入可选的静态类型,这样可以极大的加速运算效果。因为单纯的数字相加不太需要所谓的动态性,尤其是当你的程序中出现了大量的计算逻辑时
4. 对于一些计算密集型的部分,写出一些超越 Numpy、Scipy、Pandas 的算法
5. 项目中有一些已经用 C、C++ 实现的库,需要直接在 Python 内部更好地调用它们,并且不使用 ctypes、cffi 等模块
6. 可以将 Python 代码中性能关键的部分使用 C 进行重写,来达到提升性能的效果。但是这需要对 Python 解释器有很深的了解,熟悉底层的 Python/C API,而这是一件非常痛苦的事情。
Cython将 Python 语言丰富的表达能力、动态机制和 C 语言的高性能汇聚在了一起,并且代码写起来仍然像写 Python 一样。
性能比对
纯C++
#include <time.h>#include <iostream>
// g++ cfib.cpp -Ofast -o cfib && ./cfib
double cppfib(int n) {int i;double a = 0.0, b = 1.0, tmp;for (i = 0; i < n; ++i) {tmp = a;a = a + b;b = tmp;}return a;
}
int main() {clock_t st, ed;st = clock();double r = cppfib(10000000);ed = clock();std::cout << (double)(ed - st) / CLOCKS_PER_SEC << std::endl;std::cout << r << std::endl;return 1;
}编译
g++ cfib.cpp -o cfib && ./cfib22.23ms
编译打开-Ofast优化参数
g++ cfib.cpp -Ofast -o cfib && ./cfib15.217ms
Pybind11
#include <pybind11/pybind11.h>
// c++ -shared -rdynamic -fPIC -undefined -fvisibility=hidden -std=c++14
// $(python3 -m pybind11 --includes) pybindfib.cpp -o pybindfib$(python3-config
// --extension-suffix)
namespace py = pybind11;
double cppfib(int n) {int i;double a = 0.0, b = 1.0, tmp;for (i = 0; i < n; ++i) {tmp = a;a = a + b;b = tmp;}return a;
}
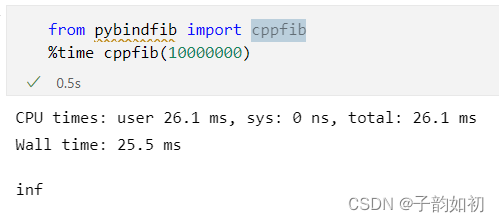
PYBIND11_MODULE(pybindfib, m) { m.def("cppfib", &cppfib); }编译,因为没有太多的循环体,打开-O编译运行加速效果不大
c++ -shared -rdynamic -fPIC -undefined -fvisibility=hidden -std=c++14运行结果以及使用Ipython,Jupyter中的%time方法,非常实用
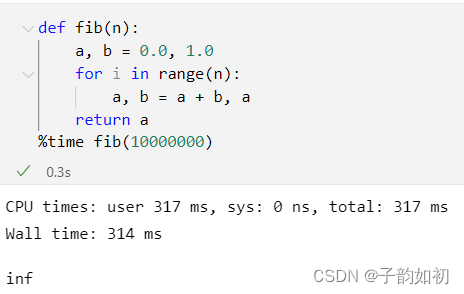
Python
Cython
no_setup_cython.pyx
def fib(int n):cdef int icdef double a = 0.0, b = 1.0for i in range(n):a, b = a + b, areturn acdef extern from "cfib.h":double cfib(int n)如上面代码可以看到和纯 Python 的斐波那契相比,Cython已经规定好了变量 i、a、b 的类型。因为 Python 中所有的变量都是一个 PyObject *,在底层中就是 C 的一个指针。PyObject(C 的一个结构体)内部有两个成员,分别是 ob_refcnt:保存对象的引用计数、ob_type *:保存对象类型的指针。不管是整型、字符串、元组、字典,所有指向它们的变量都是一个 PyObject*,当进行操作的时候,首先要通过 -> ob_type 来获取对应的类型的指针,再进行转化。
这也是Python中经典的万物皆对象,都是分配在堆上的,且由于是动态语言因此Python 解释器每一次相加都要进行检测,判断到底是什么类型并进行转化,然后执行加法的时候,再去找内部的 __add__ 方法,将两个对象相加,创建一个新的对象,执行结束后再将这个新对象的指针转成 PyObject *,然后返回。并且 Python 中的对象都是在堆上分配空间,再加上 a 和 b 不可变,所以每一次循环都会创建新的对象,并将之前的对象给回收掉。想想都很费时。
setup.py
from setuptools import setup
from Cython.Build import cythonizesetup(ext_modules = cythonize("cythonfib.pyx")
)
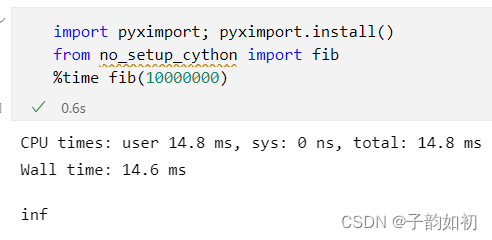
# python setup.py build_ext --inplace可以通过python setup.py build_ext --inplace 生成pyd二进制文件,也可以直接使用pyximport
总结
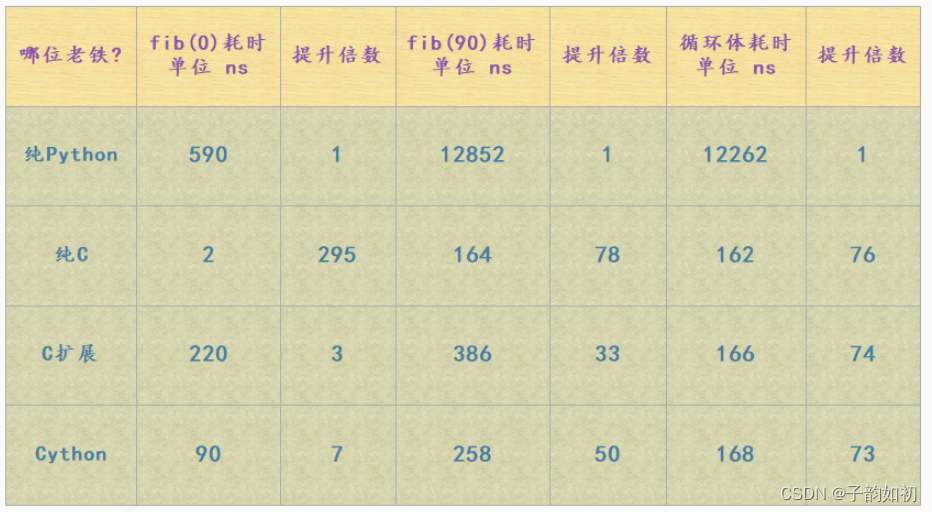
通过循环体耗时我们看到,Python 的 for 循环真的是非常之慢了,主要有以下几方面原因
循环机制
Python 在遍历一个可迭代对象的时候,会先调用这个可迭代对象内部的__iter__ 方法返回其对应的迭代器,然后再不断地调用这个迭代器的 __next__ 方法,将值一个一个的迭代出来,直到迭代器抛出 StopIteration 异常,for循环捕捉,终止循环。而迭代器是有状态的,Python 解释器需要时刻记录迭代器的迭代状态
算数操作
Python 由于其动态特性,使得其无法做任何基于类型的优化。比如:循环体中的 a + b,这个 a、b 指向的可以是整数、浮点数、字符串、元组、列表,甚至是我们实现了魔法方法 __add__ 的类的实例对象。尽管人为是知道是浮点数,但是 Python 不会做这种假设,所以每一次执行 a + b 的时候,都会检测其类型到底是什么。然后判断内部是否有 __add__ 方法,以及两者能不能相加,然后条件满足的话再调用对应的 __add__ 方法,将 a 和 b 作为参数,将 a 和 b 指向的对象进行相加。计算出结果之后,再返回其指针转成 PyObject * 返回
而对于 C 和 Cython 来说,在创建变量的时候就实现规定了类型。就是这个类型,不是其它的,因此编译之后的 a + b 只是一条简单的机器指令
内存分配
Python 中的对象是分配在堆上面的,因为 Python 中的对象本质上就是 C 中的 malloc 函数为结构体在堆区申请的一块内存。在堆区进行内存的分配和释放是需要付出很大的代价的,而栈则要小很多,并且它是由操作系统维护的,会自动回收,效率极高。尽管 Python 引入了内存池机制使得其在一定程度上避免了和操作系统的频繁交互,并且还引入了小整数对象池以及针对字符串的intern机制。但事实上,当涉及到对象(任意对象、包括标量)的创建和销毁时,都会增加动态分配内存、以及 Python 内存子系统的开销。而 float 对象又是不可变的,因此每循环一次都会创建和销毁一次,所以效率依旧是不高的
而 Cython 分配的变量,a 和 b,它们就不是指针了( Python 中的变量本质上都是一个指针),而是分配在栈上的双精度浮点数。而栈上分配的效率远远高于堆,因此非常适合 for 循环,所以效率要比 Python 高很多
更多情况
上面分析中只是在代码中添加了几个 cdef 就能获得如此大的性能改进。但是,并非所有的 Python 代码在使用 Cython 时,都能获得巨大的性能改进。因为斐波那契数列的数据是绑定在 CPU 上的,运行时都花费在处理 CPU 寄存器的一些变量上,而不需要进行数据的移动
如果此函数是内存密集(例如,给两个大数组添加元素)、I/O 密集(例如,从磁盘读取大文件)或网络密集(例如,从 FTP 服务器下载文件),则 Python,C,Cython 之间的差异可能会显著减少(对于存储密集操作)或完全消失(对于 I/O 密集或网络密集操作)
且Python 的整数不受长度的限制,但是 C 中 int 和 long 是受到限制的,因此不能正确地表示无限精度的整数。
编译Cython warning,这是因为定义了一个“cdef”函数。“cdef”函数是 C函数,它们在 Python 模块级别不可见,因此就会出现定义了但是没被使用的情况。如果需要定义Python 可调用函数,可以使用def或者cpdef。
_temp/test.c:1047:18: warning: ‘__pyx_f_4test_gen’ defined but not used [-Wunused-function]static PyObject *__pyx_f_4test_gen(int __pyx_v_x) {
t3.c:556:12: warning: ‘__pyx_f_2t3_fun’ defined but not used [-Wunused-function]static int __pyx_f_2t3_fun(char *__pyx_v_s) {这篇关于【附源码+Pybind + Cython Python性能提升方案】该拿什么拯救你,Slow Python的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






