本文主要是介绍【机器学习】KNN算法实战项目一:婚恋对象分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
KNN算法实战项目一:婚恋对象分类
- 1 婚恋平台数据集KNN分析
- 1.1 模块导入与数据加载
- 1.2 数据EDA
- 1.3 数据预处理
- 1.4 模型创建与应用
- 1.5 绘制决策边界
手动反爬虫: 原博地址 https://blog.csdn.net/lys_828/article/details/122588889
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
KNN建模思想
已知样本集中每一数据与所属分类的对应关系,输入没有标签的新数据后,将新数据的每个特征与样本集中的数据对应的特征进行比较,提取样本集中特征最相似的数据(最近邻)的分类标签。 一般来说,我们只选择样本集中前k个最相似的数据,这就是k- 近邻算法中k的出处,通常k是不大于20的整数,最后,选择k个最相似的数据中出现次数最多的分类,作为新数据的分类。
KNN建模关键
(1)训练集、距离或相似性的度量、k的大小;
(2)被“多数投票”归为其邻居分类。
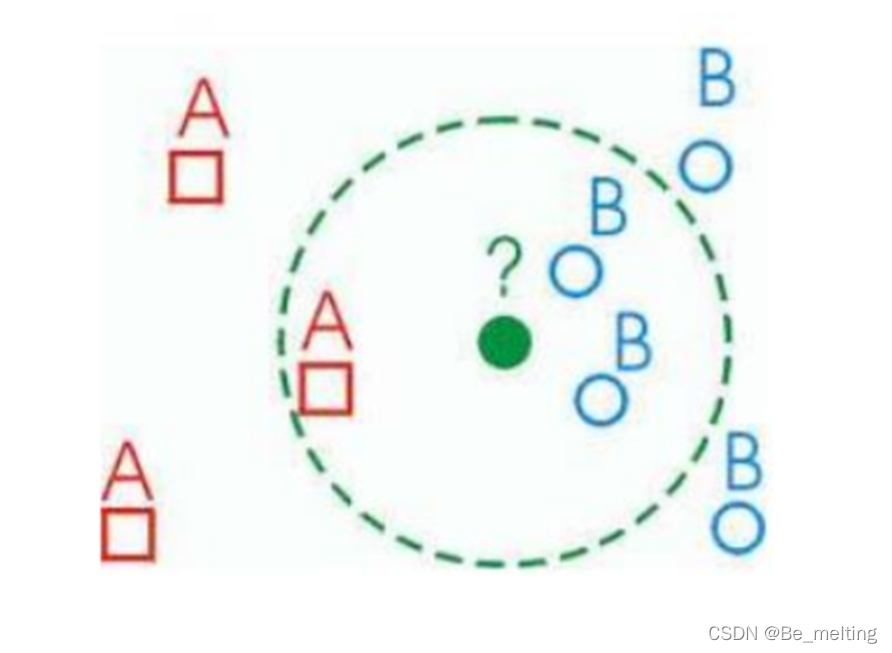
比如图中的绿点的分类,分别求解该点距离训练集中所有点的距离,然后根据给定的k值,圈出k个范围中最近的点,按照多数投票原则进行分类,这里就是两个蓝色一个红色,所以最终绿色点被划分为了蓝色。
KNN算法实现的四部曲
(1)决定K的数值 一般从1-20之间取值;
(2)在所有数据中计算与所需查询数据的距离;
(3) 把所有距离结果进行排序,找出最近的K个数据;
(4) 统计最近的K个数据的分类结果,按照投票统计结果,票数多的分类获胜。
K值的选择
(1)K取的比较大容易获得相对平稳的分界线;
(2)当k和数据量一样大时,KNN会把每组数据做成一个边界。
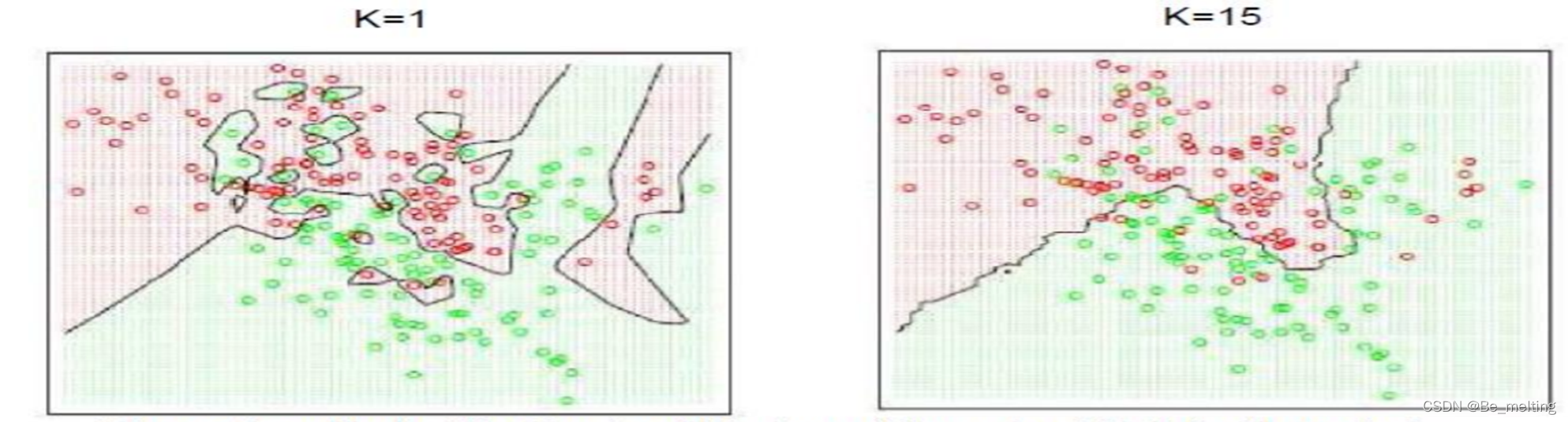
K值的选择如上图,如果较小,会分类很详细,就出现了过度拟合的现象,如果是给定的K值较大,会形成一个相对比较清晰的边界。
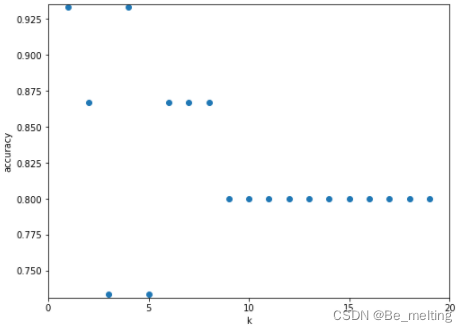
具体进行K值的选取,程序可以通过循环对比模型的得分,得分最高者即为K值最优,如下取K=1或者K=4得分最优,为了避免过拟合这时相对就会取到K=4。
1 婚恋平台数据集KNN分析
1.1 模块导入与数据加载
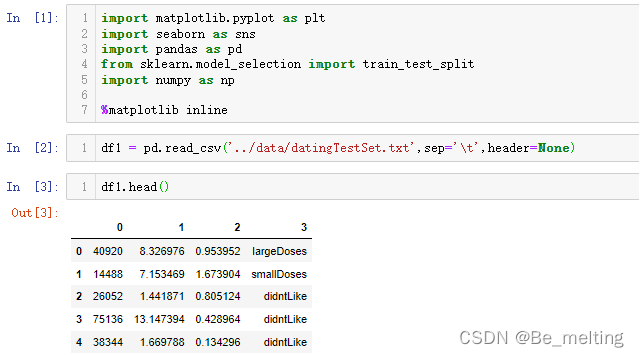
加载常用模块
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.model_selection import train_test_split
import numpy as np%matplotlib inline
加载数据,注意原数据集中没有字段名称,而且数据之间分隔的形式并不是逗号,所以要指定sep参数,代码如下。
df1 = pd.read_csv('../data/datingTestSet.txt',sep='\t',header=None)
df1.head()
输出结果如下。
指定字段名称,分别为飞行里程、游戏时间比例、冷饮量 单位升、标签。其中标签字段中一共有三个分类:largeDoses对应’非常喜欢’、smallDoses对应’有点感觉’、didntLike对应’不喜欢’。
col1 = ['飞行里程','游戏时间比例','冷饮量 单位升','标签']
df1.columns=col1
df1.head()
输出结果如下。
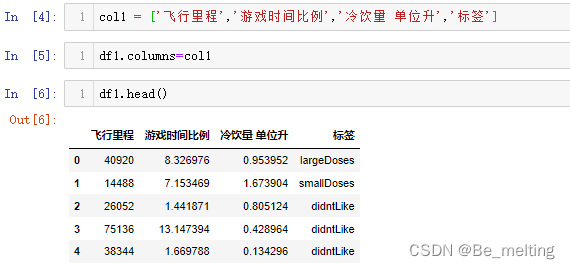
可以将标签中的英文替换成为对应的中文信息,常用的操作就是利用字典方式,代码如下。
dict1={'largeDoses':'非常喜欢','smallDoses':'有点感觉','didntLike':'不喜欢'
}
df2=df1.copy()
df2['标签']=df2['标签'].map(dict1)
df1.head()
df1.head()
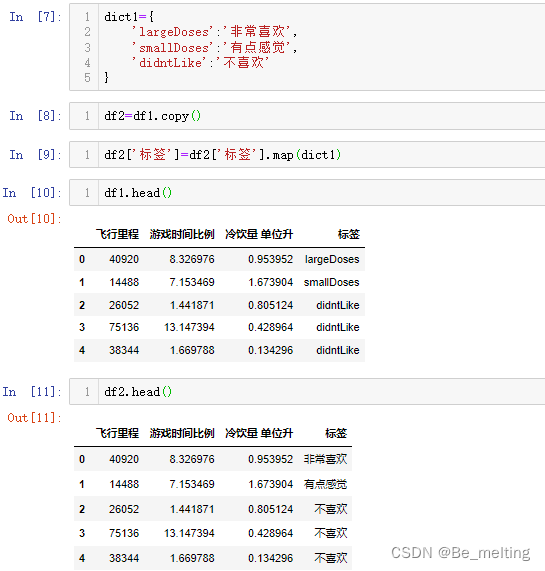
为了防止后续操作造成读入的原始数据损坏,建议操作在副本上进行,输出前后的对比结果如下。
1.2 数据EDA
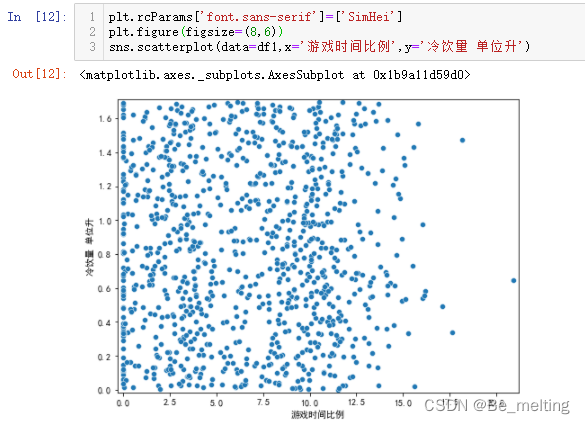
数据准备好后,可以进行简单的数据EDA处理。由于除了标签字段外剩下的三个字段都是连续型数值数据,所以可以任意选择两个字段进行散点图的绘制,查看数据的分布,比如游戏时间比例与冷饮量 单位升之间的数据情况,代码如下。
plt.rcParams['font.sans-serif']=['SimHei']
plt.figure(figsize=(8,6))
sns.scatterplot(data=df1,x='游戏时间比例',y='冷饮量 单位升')
输出结果如下。
进一步可以通过控制标签字段的类别,来进行不同颜色的显示,只需要指定hue参数即可,代码及输出结果如下。

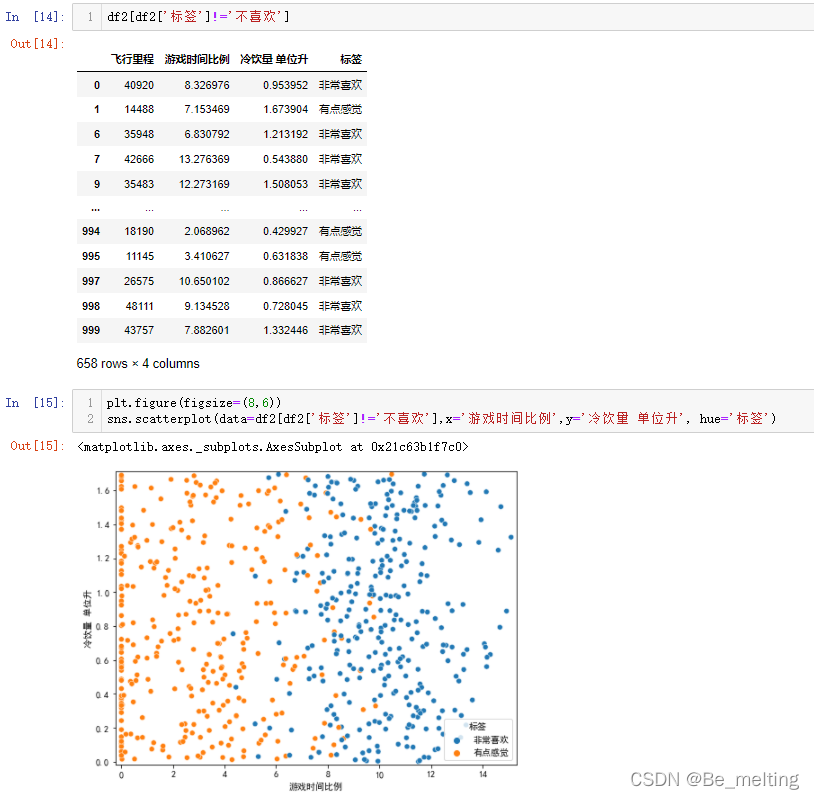
初步观察,发现对于不喜欢的类别,游戏时间比例是遍布了0-20的区间范围,但是有点喜欢和非常喜欢的类别中游戏时间比例有一个较为明显的分界线,可以尝试剔除一个分类后再看剩下的分类情况。
df2[df2['标签']!='不喜欢']
plt.figure(figsize=(8,6))
sns.scatterplot(data=df2[df2['标签']!='不喜欢'],x='游戏时间比例',y='冷饮量 单位升', hue='标签')
输出结果如下。去掉一个分类后,可以通过图形明显的发现游戏时间比例是有点感觉和非常喜欢之间的影响因素。
如果不喜欢这种x轴对比的方式,也可以调换xy轴的数据,只需要在指定x和y的参数时候调换字段名称即可,代码及输出结果如下。
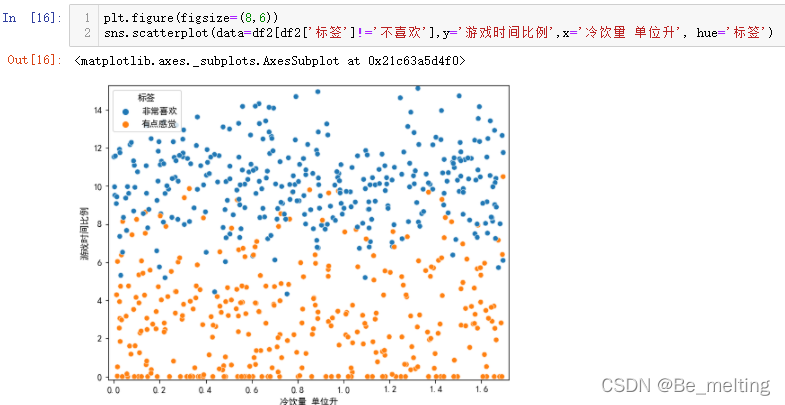
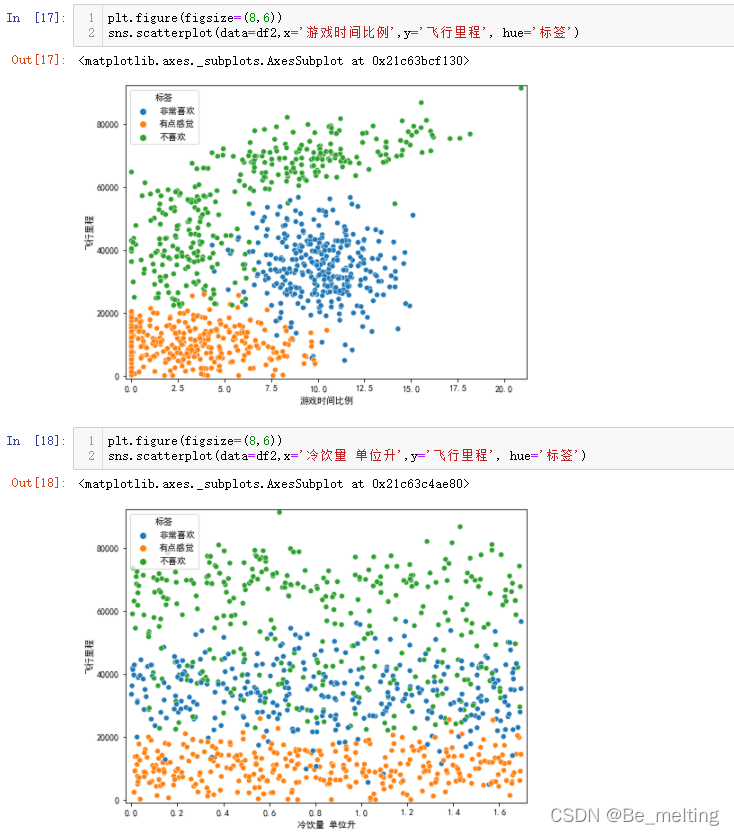
除了探究上面两个字段外,还可以尝试游戏时间比例与飞行里程、冷饮量 单位升与飞行里程之间的关联,代码如下。
plt.figure(figsize=(8,6))
sns.scatterplot(data=df2,x='游戏时间比例',y='飞行里程', hue='标签')
plt.figure(figsize=(8,6))
sns.scatterplot(data=df2,x='冷饮量 单位升',y='飞行里程', hue='标签')
输出结果如下。
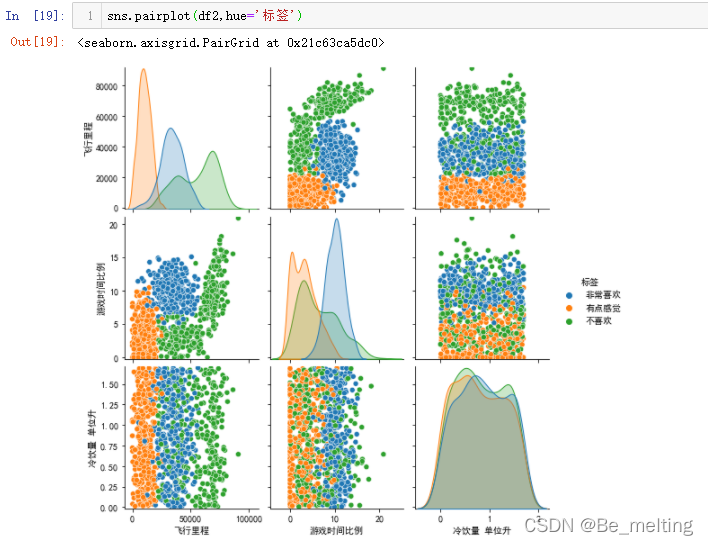
总共三个特征字段,两个关系分析一共有三个图,利用之前介绍过的pairplot也可以直接将关联图进行绘制,代码及输出结果如下。但是需要注意绘制图形时候字段数量不宜过多,不然各个子图形的显示会很小,不方便查看。
1.3 数据预处理
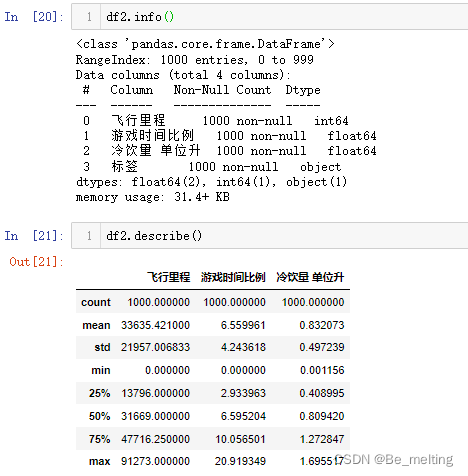
首先看一下数据的基本情况(这一步一般是在数据EDA第一步),通过info和describe方法进行查看,代码及输出结果如下。数据很干净,没有缺失值,不需要进行额外的处理。
预处理将数据进行划分,取出特征字段和标签字段,代码如下。
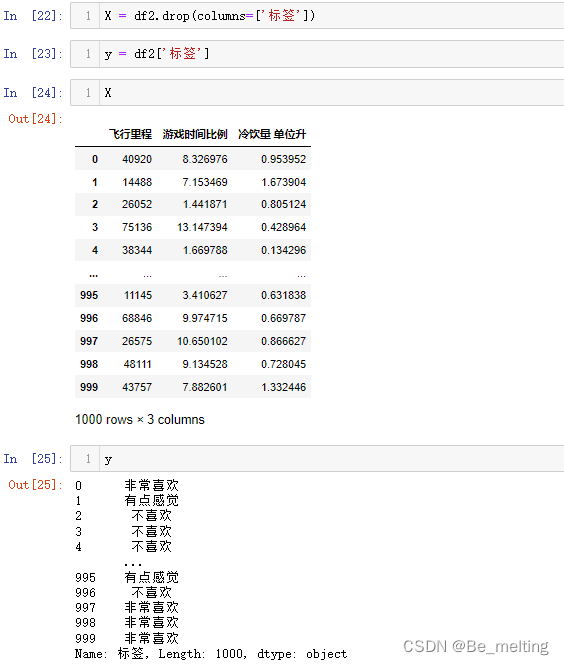
X = df2.drop(columns=['标签'])
y = df2['标签']
X
y
输出结果如下。
由于KNN中判定的依据是距离,所以不同的字段之间的数值大小就是一个很重要的影响,比如这里飞行里程可以高达万级,但是冷饮量只有小数级别,故需要消除量级的影响,进行数据的标准化,可以采用之前大数据处理工具中的MinMaxScaler,StandardScaler,也可以自己手动书写。
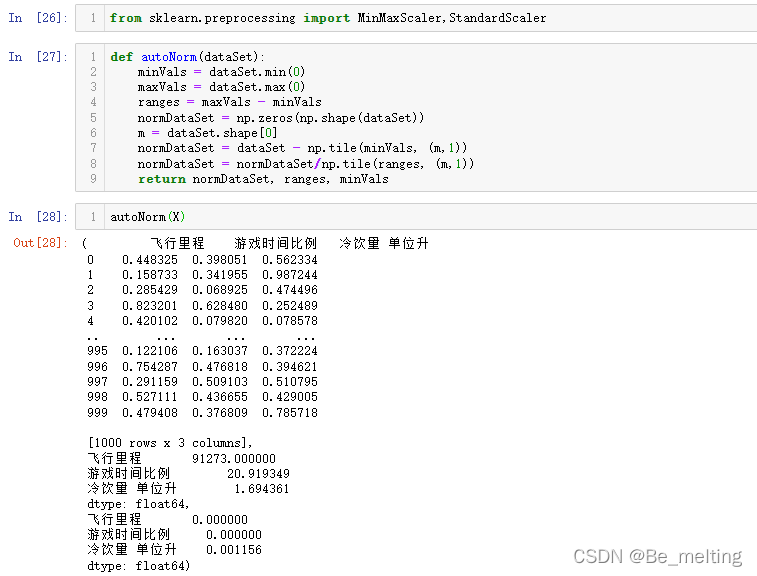
from sklearn.preprocessing import MinMaxScaler,StandardScaler
def autoNorm(dataSet):minVals = dataSet.min(0)maxVals = dataSet.max(0)ranges = maxVals - minValsnormDataSet = np.zeros(np.shape(dataSet))m = dataSet.shape[0]normDataSet = dataSet - np.tile(minVals, (m,1))normDataSet = normDataSet/np.tile(ranges, (m,1)) return normDataSet, ranges, minVals
autoNorm(X)
输出结果如下。函数功能处理标准化外海可以输出变化的范围和最小值。(除此之外也可以根据需求进行自定义封装)
数据标准化后,进行训练集和测试集的切分。
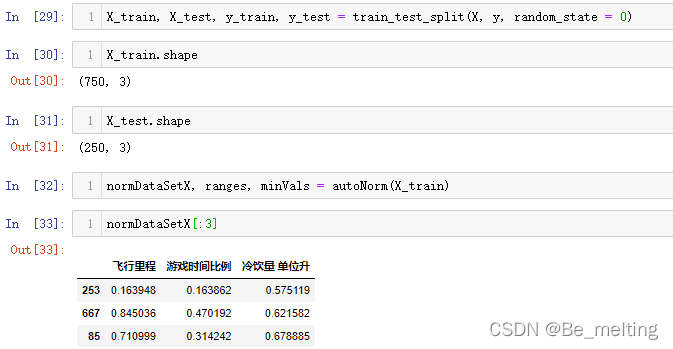
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
X_train.shape
X_test.shape
normDataSetX, ranges, minVals = autoNorm(X_train)
normDataSetX[:3]
输出结果如下。这里其实也可以先将X进行autoNorm赋值,然后再进行切分,这样就不用分别对训练集和测试集进行autoNorm了。
1.4 模型创建与应用
模型的创建与应用基本上和之前介绍的模型一致,代码解析如下。
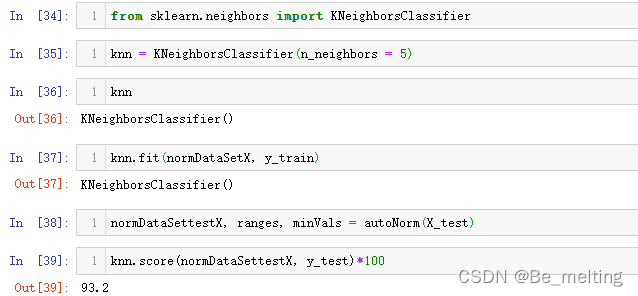
#第一步:导入模型模块
from sklearn.neighbors import KNeighborsClassifier
#第二步:指定一个初始的K值
knn = KNeighborsClassifier(n_neighbors = 5)
#第三步:模型数据训练
knn.fit(normDataSetX, y_train)
#第四步:模型得分/预测
normDataSettestX, ranges, minVals = autoNorm(X_test)
knn.score(normDataSettestX, y_test)*100
输出结果如下。
1.5 绘制决策边界
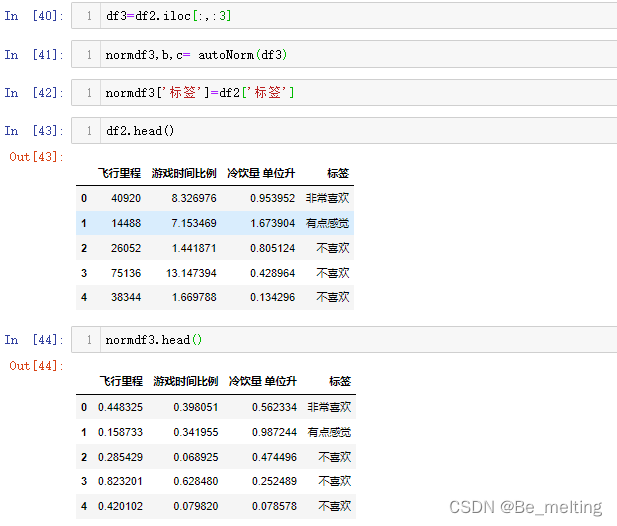
重新取出特征字段的数据,重命名为df3,然后进行标准化,最后再合并特征数据。
df3=df2.iloc[:,:3]
normdf3,b,c= autoNorm(df3)
normdf3['标签']=df2['标签']
df2.head()
normdf3.head()
输出结果如下。
接着可以通过pairplot快速查看字段关联,为了核实消除量级后是否还会对数据分布有影响,代码及输出结果如下。对比y轴的刻度信息及图形样式,证明消除量级对数据分布没有影响。
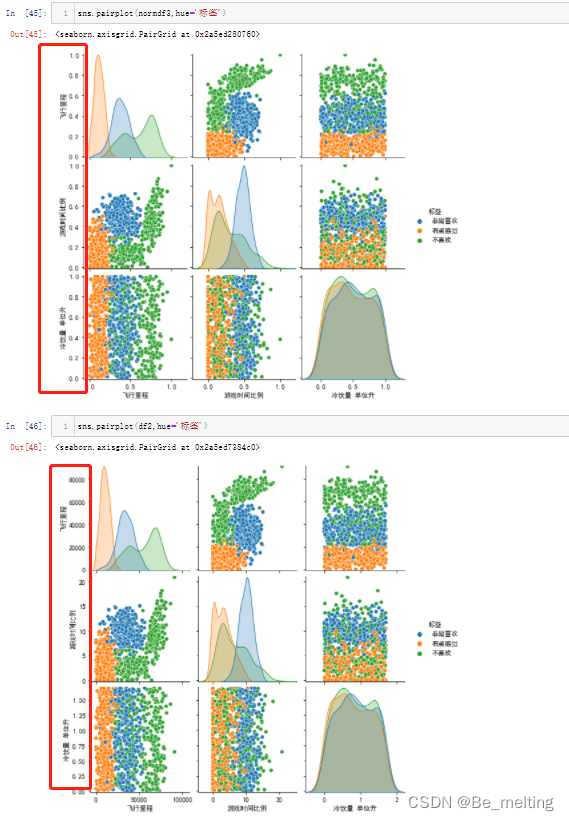
以游戏时间比例和飞行里程为例进行决策边界的绘制,首先查看一下关系图,代码及输出结果如下。
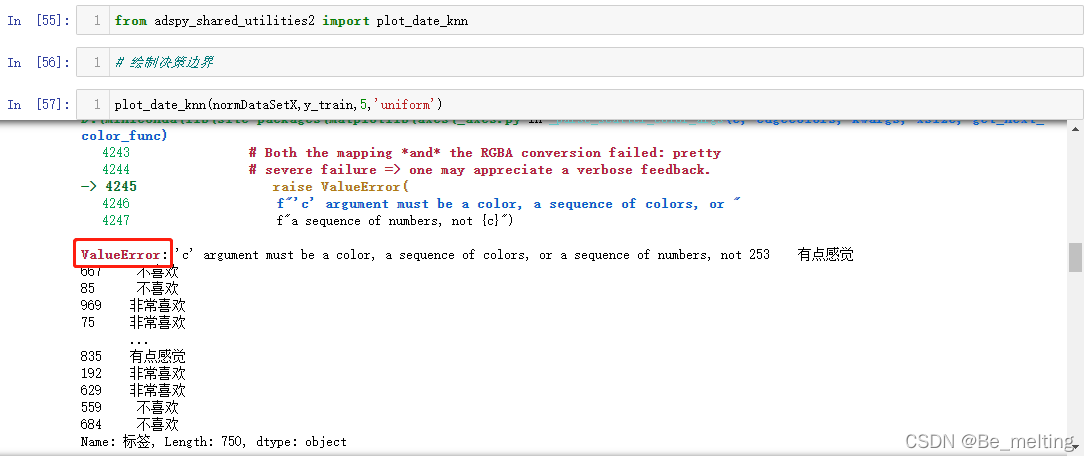
需要注意封装的函数中需要用到c参数用于指定分类的颜色,这里c对应的就是标签中的分类信息,由于指定了是中文,导致无法正确识别颜色。因此可以进行标签值的对应,也是通过字典的方式,代码如下。
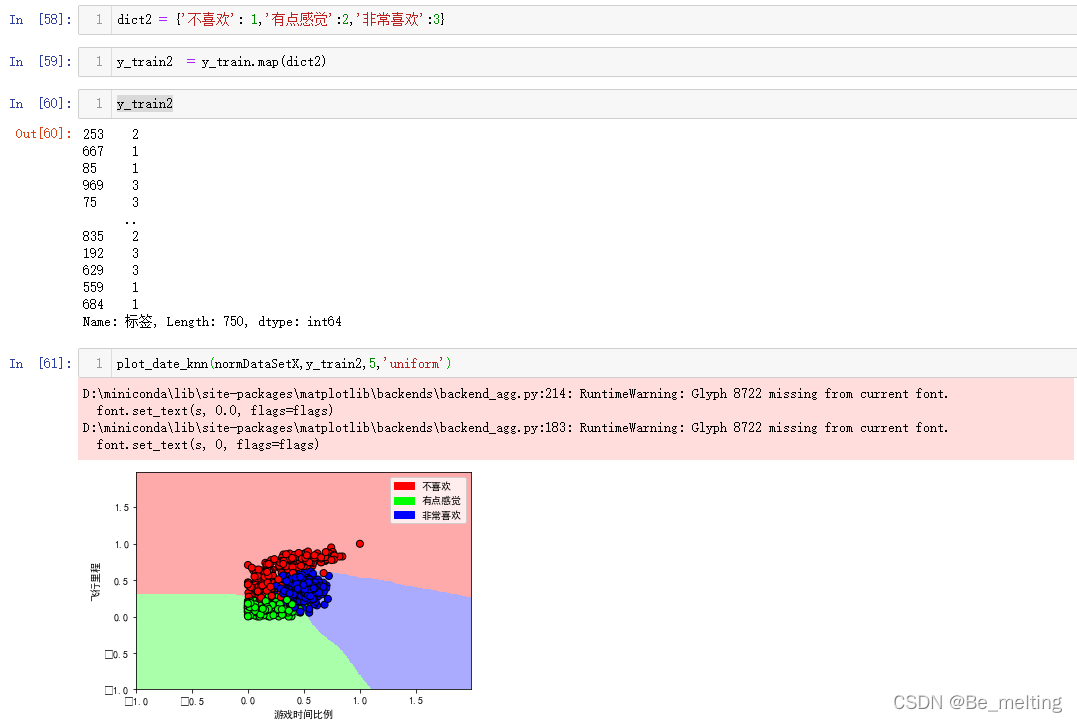
dict2 = {'不喜欢': 1,'有点感觉':2,'非常喜欢':3}
y_train2 = y_train.map(dict2)
y_train2
plot_date_knn(normDataSetX,y_train2,5,'uniform')
输出结果如下。
如果要解决负号问题,代码如下。
plt.rcParams['axes.unicode_minus']=False
plot_date_knn(normDataSetX,y_train2,5,'uniform')
输出结果中正常显示负号。

补充plot_date_knn函数全部代码,可以对比之前详细讲解决策边界的绘制过程。
def plot_date_knn(X, y, n_neighbors, weights):X_mat = X[['游戏时间比例', '飞行里程']].valuesy_mat = y.valuescmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights)clf.fit(X_mat, y_mat)mesh_step_size = .01 # step size in the meshplot_symbol_size = 50x_min, x_max = X_mat[:, 0].min() - 1, X_mat[:, 0].max() + 1y_min, y_max = X_mat[:, 1].min() - 1, X_mat[:, 1].max() + 1xx, yy = numpy.meshgrid(numpy.arange(x_min, x_max, mesh_step_size),numpy.arange(y_min, y_max, mesh_step_size))Z = clf.predict(numpy.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)plt.figure()plt.rcParams['font.sans-serif']=['SimHei']plt.pcolormesh(xx, yy, Z, cmap=cmap_light)plt.scatter(X_mat[:, 0], X_mat[:, 1], s=plot_symbol_size, c=y, cmap=cmap_bold, edgecolor='black')plt.xlim(xx.min(), xx.max())plt.ylim(yy.min(), yy.max())patch0 = mpatches.Patch(color='#FF0000', label='不喜欢')patch1 = mpatches.Patch(color='#00FF00', label='有点感觉')patch2 = mpatches.Patch(color='#0000FF', label='非常喜欢')# patch3 = mpatches.Patch(color='#AFAFAF', label='lemon')plt.legend(handles=[patch0, patch1, patch2])plt.xlabel('游戏时间比例')plt.ylabel('飞行里程')plt.show()
这篇关于【机器学习】KNN算法实战项目一:婚恋对象分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






