本文主要是介绍ClickHouse--05--MergeTree 表引擎,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- MergeTree 系列表引擎
- 前言
- MergeTree 系列表引擎 --功能
- MergeTree 系列表引擎 --种类
- 1.MergeTree
- 1.1MergeTree 建表语句:
- 1.2 MergeTree 引擎表目录解析
- 查询过程 
- 1.3 MergeTree 引擎表设置分区
MergeTree 系列表引擎
前言
ClickHouse 提供了大约 28 种表引擎,各有各的用途 纷繁复杂。ClickHouse 表引擎一共分为四个系列,分别是 Log 系列、MergeTree 系列、Integration 系列、Special 系列。其中包含了两种特殊的表引擎 Replicated、Distributed,功能上与其他表引擎正交,根据场景组合使用
- Log 系列用来做小表数据分析
- MergeTree 系列用来做大数据量分析
- Integration 系列则多用于外表数据集成。
- 再复制表 Replicated 系列
- 分布式表 Distributed 等,
在所有的表引擎中,最为核心的当属 MergeTree 系列表引擎,这些表引擎拥有最为强大的性能和最广泛的使用场合。对于非 MergeTree 系列的其他引擎而言,主要用于特殊用途,场景相对有限。
MergeTree 系列表引擎 --功能
而 MergeTree 系列表引擎是官方主推的存储引擎,有
- 主键索引
- 数据分区
- 数据副本
- 数据采样
- 删除和修改等功能,
- 支持几乎所有 ClickHouse 核心功能。
MergeTree 系列表引擎 --种类
MergeTree 系 列 表 引 擎 包 含 :
- MergeTree
- ReplacingMergeTree
- SummingMergeTree(汇总求和功能)
- AggregatingMergeTree(聚合功能)
- CollapsingMergeTree(折叠删除功能)
- VersionedCollapsingMergeTree(版本折叠功能)引擎
在这些的基础上还可以叠加 Replicated 和 Distributed。
1.MergeTree
- MergeTree 在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段在磁盘上不可修改。
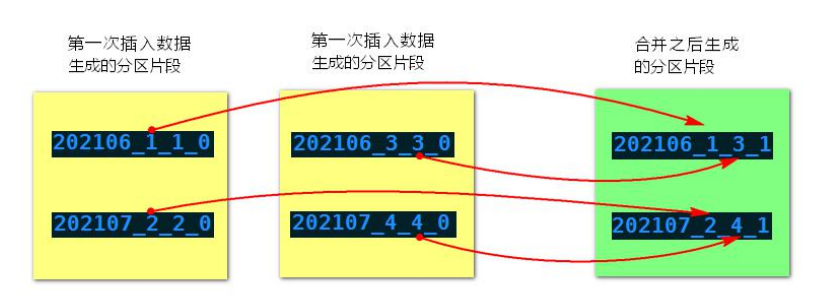
- 为了避免片段过多,ClickHouse 会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。这种数据片段往复合并的特点,也正是合并树名称的由来。

1.1MergeTree 建表语句:

-
ENGINE:ENGINE = MergeTree(),MergeTree 引擎没有参数。
-
ORDER BY:排序字段。比如 ORDER BY (Col1, Col2),值得注意的是,如果没有使用 PRIMARY KEY 显式的指定主键 ORDER BY 排序字段自动作为主键。如果不需要排序,则可以使用 ORDER BY tuple() 语法,这样的话,创建的表也就不包含主键。这种情况下,ClickHouse 会按照插入的顺序存储数据。必选项。
-
PARTITION BY : 分 区 字 段 , 例 如 要 按 月 分 区 , 可 以 使 用 表 达 toYYYYMM(date_column),这里的 date_column 是一个 Date 类型的列,分区名的格式会是"YYYYMM"。可选。
-
PRIMARY KEY:指定主键,如果排序字段与主键不一致,可以单独指定主键字段。否则默认主键是排序字段。大部分情况下不需要再专门指定一个 PRIMARY KEY子句,注意,在 MergeTree 中主键并不用于去重,而是用于索引,加快查询速度。可选。

- SAMPLE BY:采样字段,如果指定了该字段,那么主键中也必须包含该字段。比如 SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate,intHash32(UserID))。可选。
- TTL:数据的存活时间。在 MergeTree 中,可以为某个列字段或整张表设置 TTL。当时间到达时,如果是列字段级别的 TTL,则会删除这一列的数据;如果是表级别的 TTL,则会删除整张表的数据。可选。
- SETTINGS:额外的参数配置。可选。

示例:
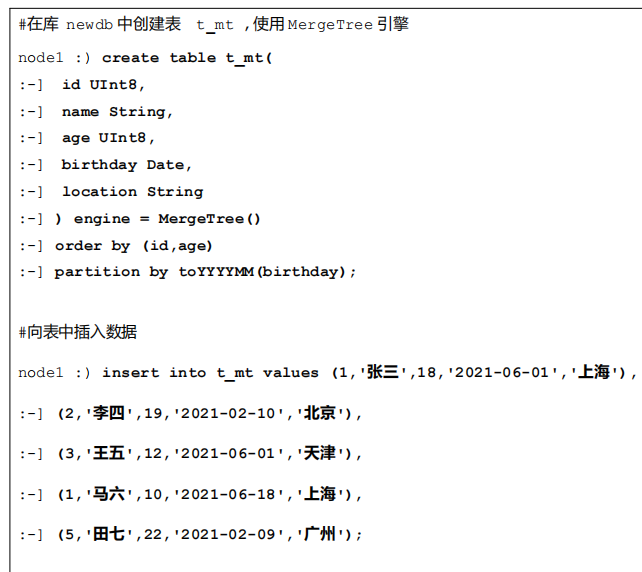

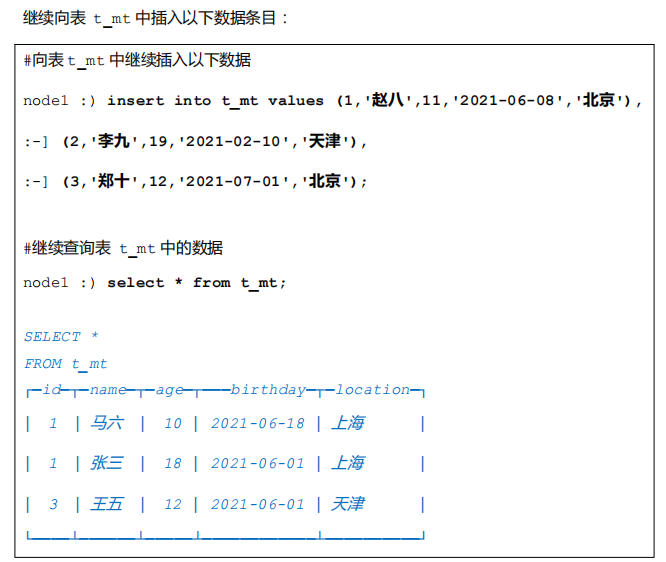

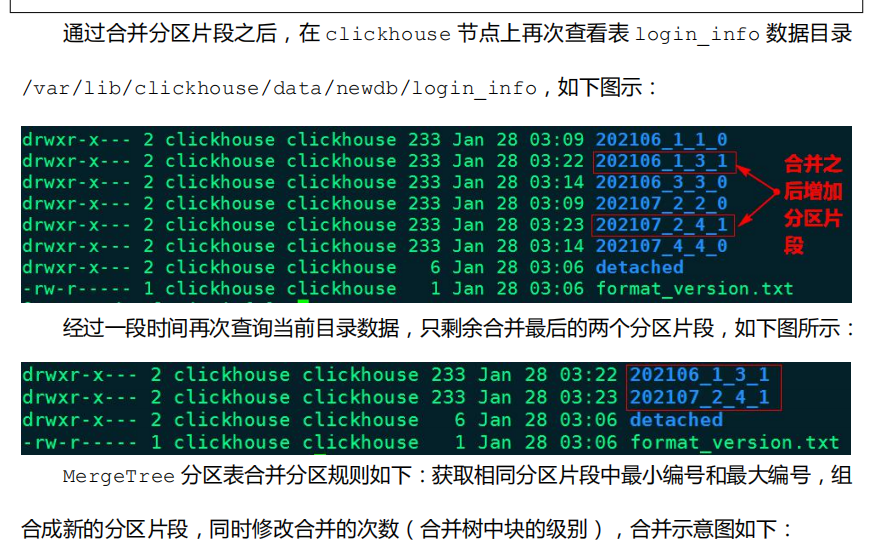
MergeTree引擎会在插入数据 15 分钟左右,将同一个分区的各个分区文件片段合并成一整个分区文件。
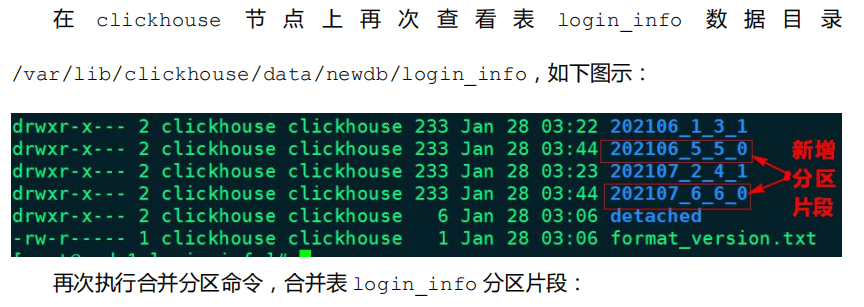
这里也可以手动执行 OPTIMIZE 语句手动触发合并

1.2 MergeTree 引擎表目录解析


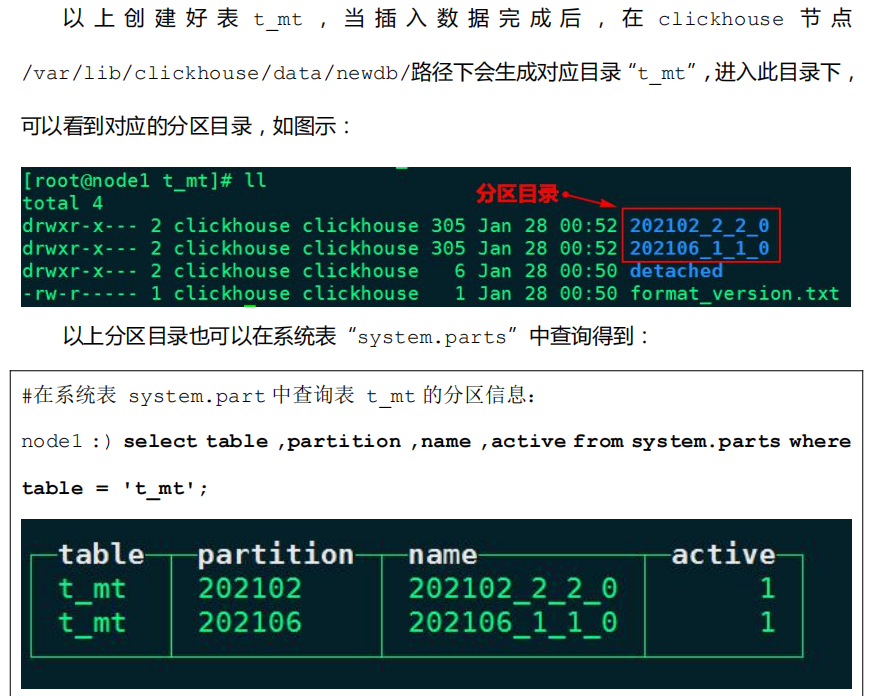

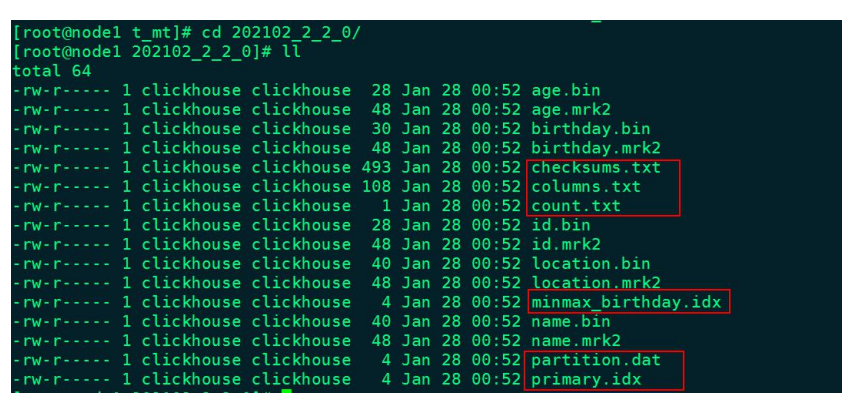
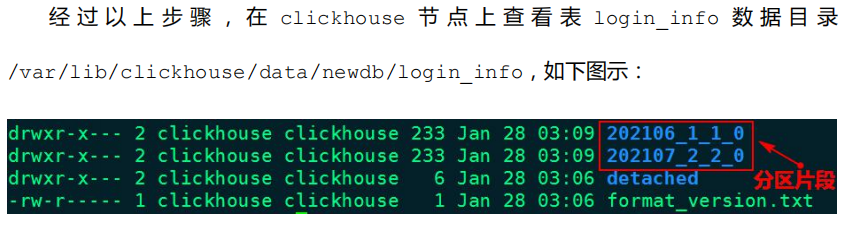
进入到某一个分区目录片段“202102_2_2_0”中,我们可以看到如下目录:


查询过程

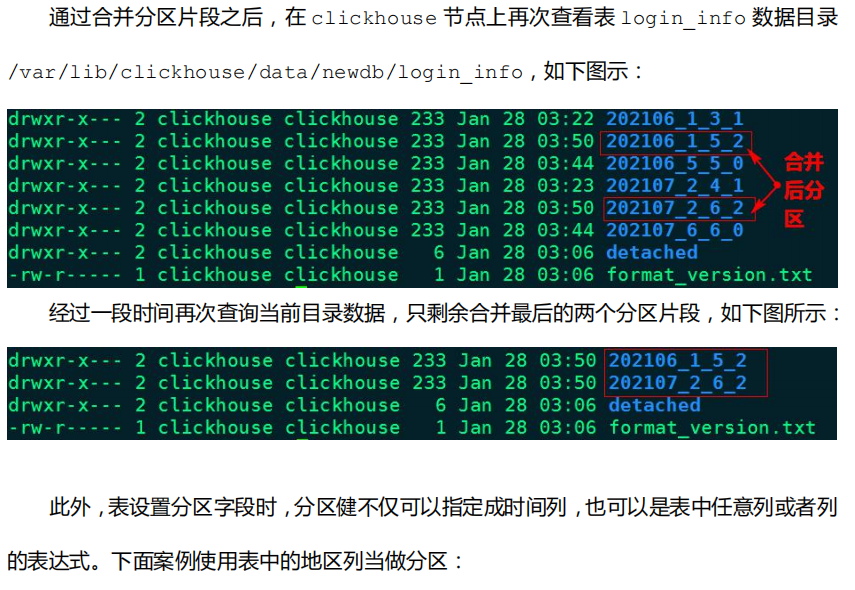
1.3 MergeTree 引擎表设置分区

案例


这篇关于ClickHouse--05--MergeTree 表引擎的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








