本文主要是介绍[超分辨率重建]ESRGAN算法训练自己的数据集过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、下载数据集及项目包
1. 数据集
1.1 文件夹框架的介绍,如下图所示:主要有train和val,分别有高清(HR)和低清(LR)的图像。

1.2 原图先通过分割尺寸的脚本先将数据集图片处理成两个相同的图像组(HR和LR)。
如训练x4的ESRGAN模型,那么我们需要将HR的图像尺寸与LR的图像尺寸比例是4:1。在我的训练中,我将HR的图像尺寸分割成了480x480,LR的图像分割成了120x120。如下图所示。


随后将分割好的图像按照train和val的分类,分成如1.1图中的文件结构。
2. 项目包
在我的下载资源中有SR项目包的下载,后续上链接。也可以在我上传的资源中下载。
二、训练ESRGAN
ESRGAN模型包括生成模型的训练和判别模型的训练。
2.1 配置RRDBNet_train.py(生成模型)的参数及训练
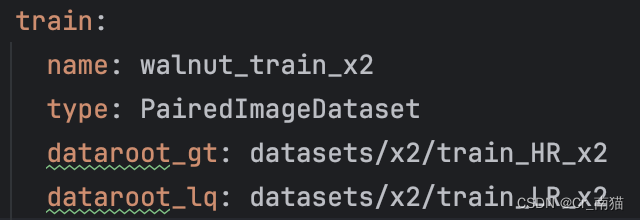
2.1.1 训练的图像路径设置:dataroot_gt为HR图像的路径、dataroot_lq为LR图像的路径。
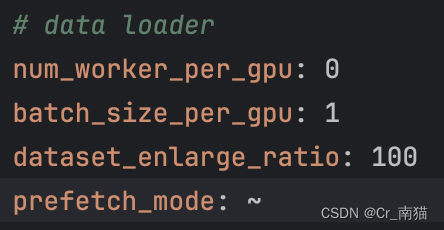
2.1.2 batch_size_per_gpu为batchsize的设置,根据显存大小相应设置,显存越大可以设置的值越大,但是训练时间也会增大。
2.1.3 val的数据集路径设置,dataroot_gt为HR的图像路径、dataroot_lq为LR图像的路径。

2.1.4 训练迭代次数的设置,可以设置到10万或者更大

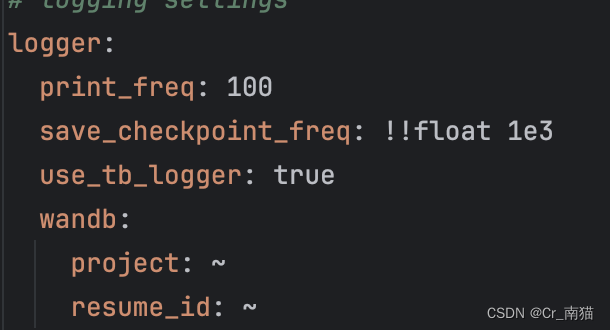
2.1.5 训练结果指标的计算psnr和ssim。val_freq参数为保存结果的频率。下图中我的设置为1e3即1000轮保存一次。

2.1.6 保存训练权重的频率设置。下图中我的设置为1e3,即为1000次保存一次训练权重。
2.1.7 RRDBNet_train.py的训练
python basicsr/train.py -opt options\train\ESRGAN\train_RRDBNet_PSNR_x4.yml2.2 配置ESRGAN_train.py(判别模型)的参数及训练
2.2.1 ESRGAN_train.py的参数设置
ESRGAN_train.py的参数设置与RRDBNet_train.py相同,但是多了一个pretrain_network_g参数的设置,即填RRDBNet_train.py训练完以后最好的那次权重路径。

2.2.2 ESRGAN_train.py的训练
python basicsr/train.py -opt options\train\ESRGAN\train_RRDBNet_PSNR_x4.yml三、测试
3.1 测试图片路径的设置
包括HR和LR的路径,分别为dataroot_gt和dataroot_lq。

3.2 ESRGAN模型权重的路径导入
在pretrain_network_g参数中导入ESRGAN模型训练完后生成的权重路径。

四、训练中断后,继续训练
只需要在训练代码后加上--auto_resume
python basicsr/train.py -opt options\train\ESRGAN\train_RRDBNet_PSNR_x4.yml --auto_resume------------------ 今天不学习,明天变垃圾。 ---------------------
这篇关于[超分辨率重建]ESRGAN算法训练自己的数据集过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







