本文主要是介绍mmdetection使用自己的voc数据集训练模型实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一.自己数据集整理
将labelimg格式数据集进行整理
1.1. 更换图片后缀为jpg
import os
import shutilroot_path='/media/ai-developer/img'file=os.listdir(root_path)for img in file:if img.endswith('jpeg') or img.endswith('JPG') or img.endswith('png'):img_path=os.path.join(root_path,img)name=os.path.splitext(img)[0]new_name=name+'.jpg'os.rename(img_path,os.path.join(root_path,new_name))print(name+'.jpg','修改成功....')
2.删除xml和jpg名称不对应的图片
import os
import shutil
imgs=[]
labels=[]xml_path='/media/ai-developer/277f00a0-3f2b-47a3-9870-b69d65db4d511/图像/20240130结果/ann'
jpg_path='/media/ai-developer/277f00a0-3f2b-47a3-9870-b69d65db4d511/图像/20240130结果/img'def get_file_list(path, ex):file_list = []for dir, folder, file in os.walk(path):for i in file:if os.path.splitext(i)[1] in ex:file_list.append(os.path.join(dir, i))return file_listfile_jpg = get_file_list(jpg_path, ['.jpg','.JPG','jpeg','png'])
file_xml = get_file_list(xml_path, ['.xml'])prefix_jpg_list=[]
prefix_xml_list=[]for b in file_jpg:prefix_jpg=os.path.splitext(b)[0]jpg_suffix = os.path.basename(prefix_jpg)prefix_jpg_list.append(jpg_suffix)for b in file_xml:prefix_xml=os.path.splitext(b)[0]xml_suffix = os.path.basename(prefix_xml)prefix_xml_list.append(xml_suffix)for c in prefix_jpg_list:if c not in prefix_xml_list:os.remove(os.path.join(jpg_path,c)+'.jpg')print(c + '.jpg 已将删除')for d in prefix_xml_list:if d not in prefix_jpg_list:os.remove(os.path.join(xml_path,d)+'.xml')print(d+'.xml 已将删除')
print('over')
1.3 查看class name
# -*- coding:utf-8 -*-from xml.dom.minidom import parse
import xml.dom.minidom
import os
import xml.etree.ElementTree as ETxml_path = '/home/ai-developer/桌面/VOCdevkit/VOC2007/Annotations'classCount = dict()
jpg_name_set=set()def load_predefine_class():predef = open('predefined_classes.txt', 'r', encoding='utf-8')for c in predef:c = c[:-1]classCount[c] = 0def parse_files(path):root = ET.parse(path).getroot() # 利用ET读取xml文件for obj in root.iter('object'): # 遍历所有目标框# print('pic_name:', xml_name)name = obj.find('name').text # 获取目标框名称,即label名v = classCount.get(name, 0)classCount[name] = v + 1def traversal_dir(xml_path):for p,d,f in os.walk(xml_path):for t in f:if t.endswith(".xml"):path = os.path.join(p, t)parse_files(path)# print(path)def output():for k in classCount:print('%s : %d' % (k, classCount[k]))if __name__ == '__main__':traversal_dir(xml_path)output()
1.4 创建以下目录结构
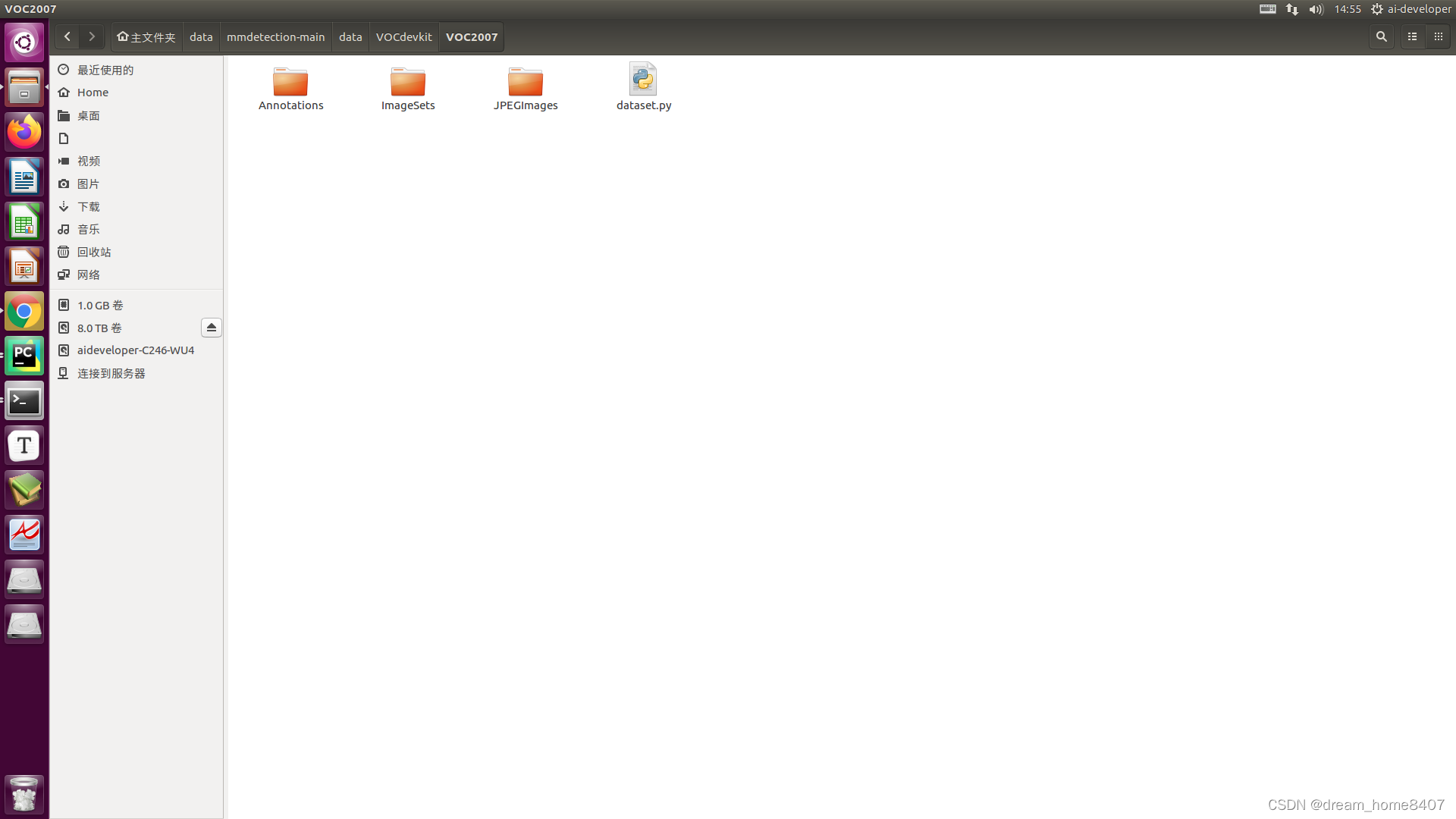
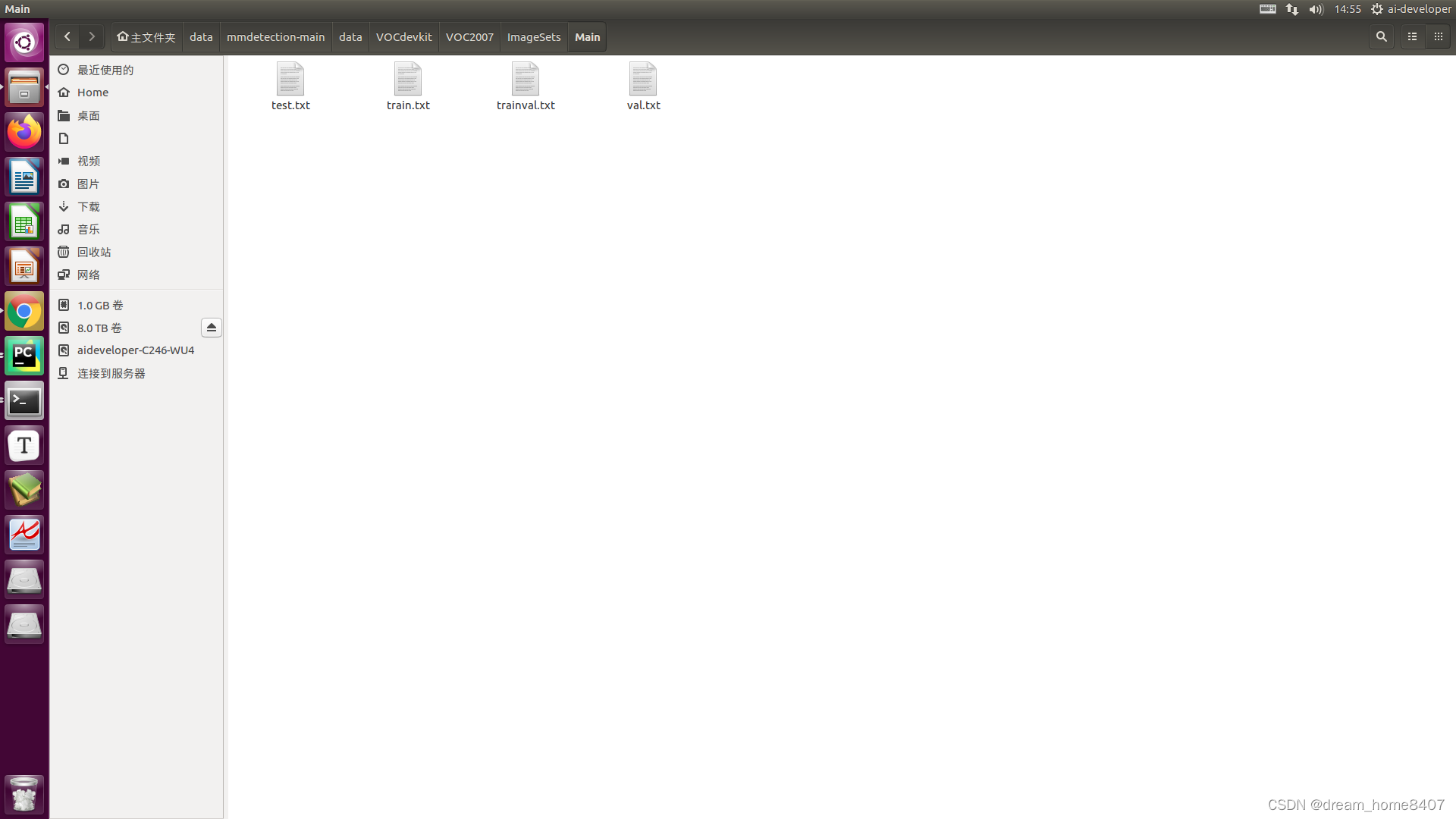
其中JPEGImgs里面是所有图片
Annotations里面是所有xml文件
dataset.py文件代码为
import os
import randomtrainval_percent =0.8 # 0.8
train_percent =0.8 #0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')for i in list:name = total_xml[i][:-4] + '\n'if i in trainval:ftrainval.write(name)if i in train:ftrain.write(name)else:fval.write(name)ftest.write(name)else:ftest.write(name)ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
print('数据集划分完成')
准备好一切后,python dataset.py自动划分数据集
由此,数据集已经准备完成
二.修改mmdetection配置文件
我的环境版本
``
torch 2.0.1
mmcv 2.1.0
mmdeploy 1.3.1
mmdeploy-runtime 1.3.1
mmdeploy-runtime-gpu 1.3.1
mmdet 3.2.0
mmengine 0.10.1
### 我使用的模型为cascade-rcnn-r101
## 1.0 修改voc0712.py
vi /mmdetection-main/configs/_base_/datasets/voc0712.py```python
# dataset settings
dataset_type = 'VOCDataset'
data_root = 'data/VOCdevkit/'# Example to use different file client
# Method 1: simply set the data root and let the file I/O module
# automatically Infer from prefix (not support LMDB and Memcache yet)# data_root = 's3://openmmlab/datasets/detection/segmentation/VOCdevkit/'# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
# backend_args = dict(
# backend='petrel',
# path_mapping=dict({
# './data/': 's3://openmmlab/datasets/segmentation/',
# 'data/': 's3://openmmlab/datasets/segmentation/'
# }))
backend_args = Nonetrain_pipeline = [dict(type='LoadImageFromFile', backend_args=backend_args),dict(type='LoadAnnotations', with_bbox=True),dict(type='Resize', scale=(1000, 600), keep_ratio=True),dict(type='RandomFlip', prob=0.5),dict(type='PackDetInputs')
]
test_pipeline = [dict(type='LoadImageFromFile', backend_args=backend_args),dict(type='Resize', scale=(1000, 600), keep_ratio=True),# avoid bboxes being resizeddict(type='LoadAnnotations', with_bbox=True),dict(type='PackDetInputs',meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape','scale_factor'))
]
train_dataloader = dict(batch_size=2,num_workers=2,persistent_workers=True,sampler=dict(type='DefaultSampler', shuffle=True),batch_sampler=dict(type='AspectRatioBatchSampler'),dataset=dict(type='RepeatDataset',times=3,dataset=dict(type='ConcatDataset',# VOCDataset will add different `dataset_type` in dataset.metainfo,# which will get error if using ConcatDataset. Adding# `ignore_keys` can avoid this error.ignore_keys=['dataset_type'],datasets=[dict(type=dataset_type,data_root=data_root,ann_file='VOC2007/ImageSets/Main/trainval.txt',data_prefix=dict(sub_data_root='VOC2007/'),filter_cfg=dict(filter_empty_gt=True, min_size=32, bbox_min_size=32),pipeline=train_pipeline,backend_args=backend_args),# dict(# type=dataset_type,# data_root=data_root,# ann_file='VOC2012/ImageSets/Main/trainval.txt',# data_prefix=dict(sub_data_root='VOC2012/'),# filter_cfg=dict(# filter_empty_gt=True, min_size=32, bbox_min_size=32),# pipeline=train_pipeline,# backend_args=backend_args)])))val_dataloader = dict(batch_size=2,num_workers=2,persistent_workers=True,drop_last=False,sampler=dict(type='DefaultSampler', shuffle=False),dataset=dict(type=dataset_type,data_root=data_root,ann_file='VOC2007/ImageSets/Main/test.txt',data_prefix=dict(sub_data_root='VOC2007/'),test_mode=True,pipeline=test_pipeline,backend_args=backend_args))
test_dataloader = val_dataloaderval_evaluator = dict(type='VOCMetric', metric='mAP', eval_mode='11points')
test_evaluator = val_evaluator
2.0 修改cascade-rcnn_r50_fpn.py
vi mmdetection-main/configs/base/models/cascade-rcnn_r50_fpn.py
修改3出位置 ,num_classes=自己对应的类别数量,
3.0 cascade-rcnn_r50_fpn_1x_coco.py文件修改
vi /mmdetection-main/configs/cascade_rcnn/cascade-rcnn_r50_fpn_1x_coco.py
_base_ = ['../_base_/models/cascade-rcnn_r50_fpn.py',# '../_base_/datasets/coco_detection.py','../_base_/datasets/voc0712.py','../_base_/schedules/schedule_2x.py', '../_base_/default_runtime.py'
]
4.0 修改voc.py
vi /mmdetection-main/mmdet/datasets/voc.py

5.0 修改class_name.py
vi /mmdetection-main/mmdet/evaluation/functional/class_names.py
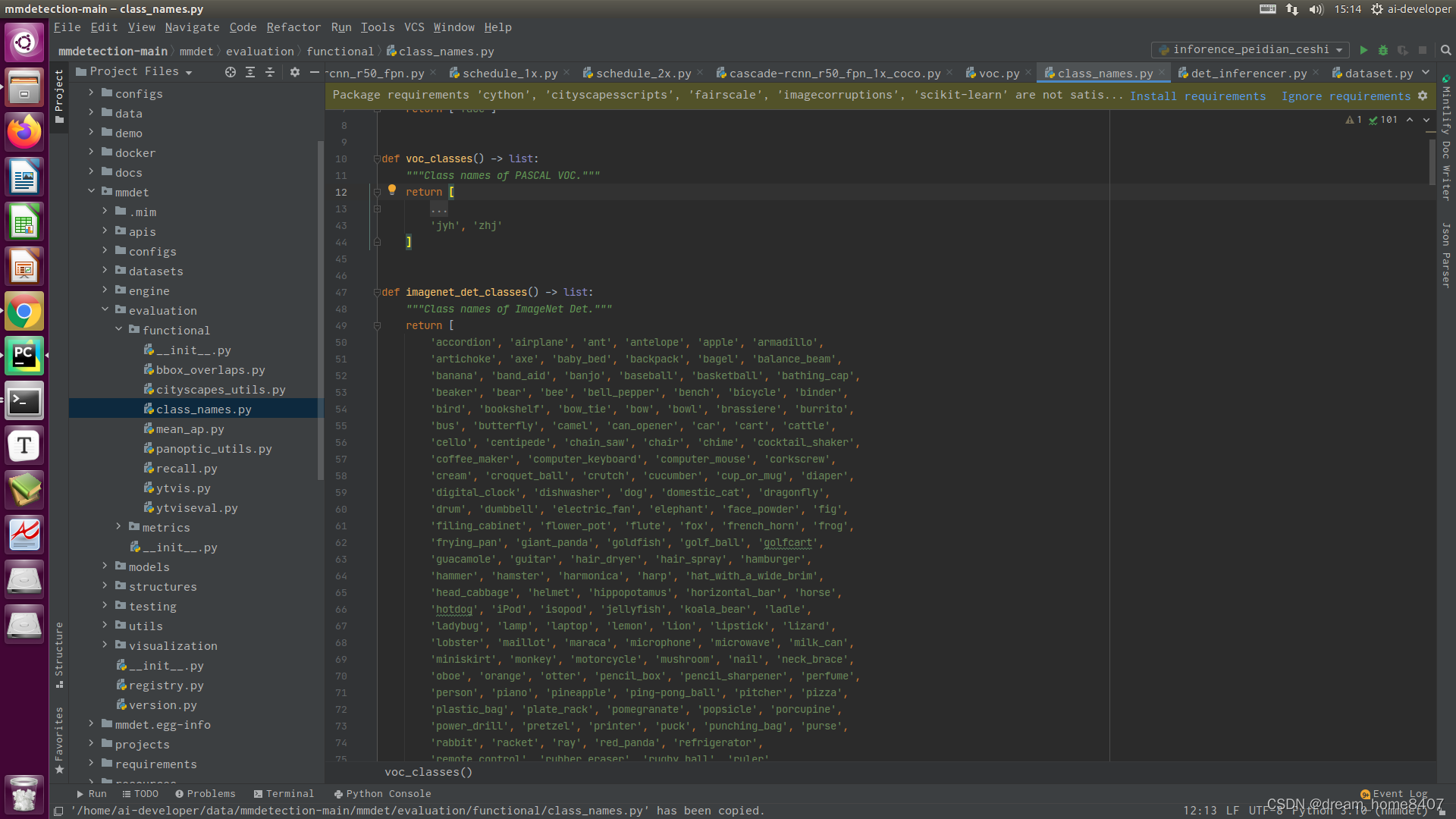
好了,配置文件修改完成,接下来就是开始训练
三.启动训练
单卡训练模型示例
python3 ./tools/train.py ./configs/faster_rcnn_r50_fpn_1x.py
python tools/train.py configs/cascade_rcnn/cascade_rcnn_r50_fpn_1x_coco.py --work-dir work_dirs/cascade_rcnn_r50_fpn_1x_0603/多gpu分布式训练示例./tools/dist_train.sh configs/cascade_rcnn/cascade-rcnn_r101_fpn_1x_coco.py 2 --work-dir work_dirs/cascade_rcnn_r101_fpn_1x_0120resume 训练./tools/dist_train.sh configs/cascade_rcnn/cascade_rcnn_r101_fpn_20e_coco.py 2 --resume-from work_dirs/cascade_rcnn_r101_fpn_1x_coco0716/latest.pth --work-dir work_dirs/cascade_rcnn_r101_fpn_1x_coco0716
四.模型推理
from mmdet.apis import DetInferencer
import mmcv
import os
import time
import cv2
import matplotlib.pyplot as pltconfig_file = '/home/ai-developer/data/mmdetection-main/work_dirs/cascade_rcnn_r101_fpn_1x25/cascade-rcnn_r101_fpn_1x_coco.py'
checkpoint_file = '/home/ai-developer/data/mmdetection-main/work_dirs/cascade_rcnn_r101_fpn_1x25/epoch_19.pth'inferencer = DetInferencer(model=config_file,weights=checkpoint_file,device='cuda:0') # ,palette ='random'imgdir = '/home/ai-developer/data/mmdetection-main/work_dirs/cascade_rcnn_r101_fpn_1x_0205/test_img'
imgs = os.listdir(imgdir)
i = 0
start = time.time()
for img in imgs:i = i + 1name=os.path.basename(img)# print('name:',name)imgpath = os.path.join(imgdir, img) # or img = mmcv.imread(img), which will only load it once# print(imgpath)out_dir = os.path.join('./results/shebei0205', img)result = inferencer(imgpath,out_dir=out_dir,show=False)#,show=True
这篇关于mmdetection使用自己的voc数据集训练模型实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





