本文主要是介绍中科大何向南团队+快手App联合出品 KuaiRec | 快手首个稠密为99.6%的数据集 | 相关介绍、下载、处理、使用方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1. 数据集介绍
- 1.1 相关链接:
- 1.2 构建方法
- 1.3 代表性验证
- 1.4 相关实验
- 2. 数据集下载
- 2.1 big matrix
- 2.1 small matrix
- 2.3 item_feat
- 2.4 social_network
- 2.5 注意点
- 3. 数据集处理
- 3.1 数据集读取
- 3.2 划分训练集测试集
- 3.3 拼接物品属性
- 3.4 转换成稀疏矩阵
- 3.5 social network处理
1. 数据集介绍

滴滴滴!作者在5.16进行了更新,解决了1225物品没有交互的bug,还新增了超多特征!
KuaiRec是中科大与快手团队合作产出的一个稠密度高达99.6%(一般推荐系统公开数据集的稠密度在1%以下)的数据集。
本文将对KuaiRec的构建过程、相关实验、数据信息及处理使用方法等内容进行说明。
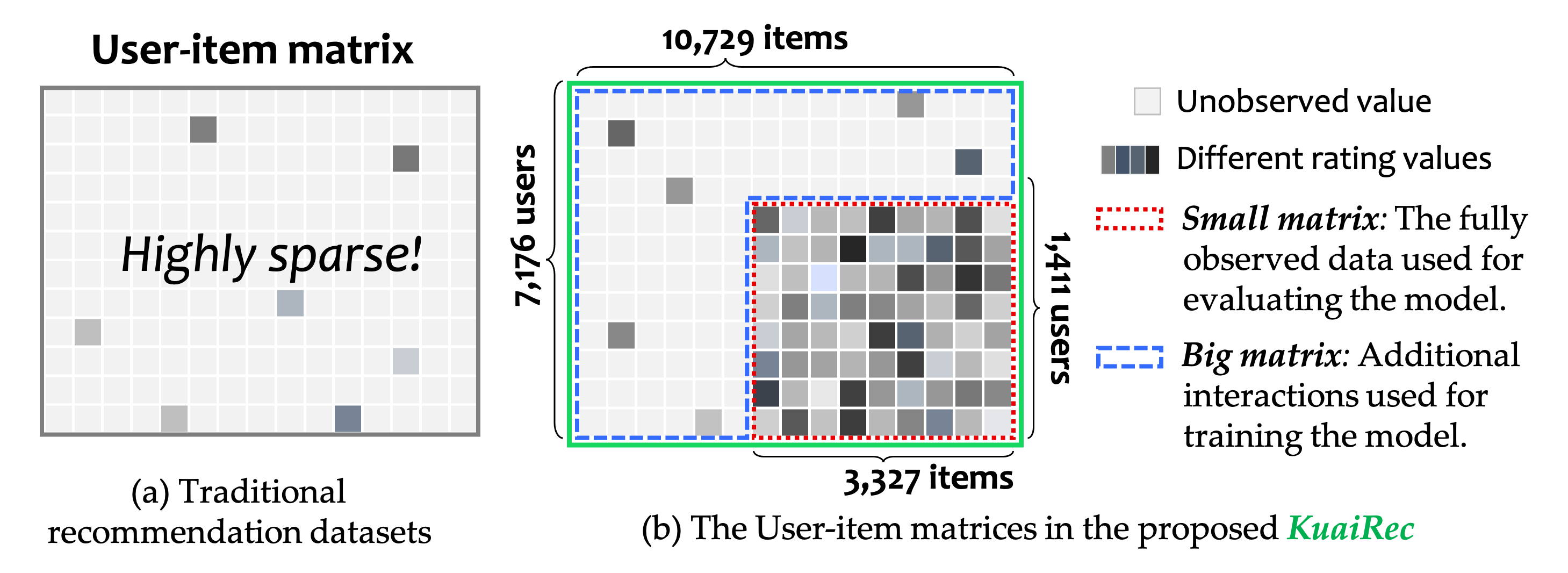
上图(b)为KuaiRec数据集,右下角的小矩阵是收集到的全曝光数据集;
通常来说,我们使用大矩阵训练,用小矩阵测试。
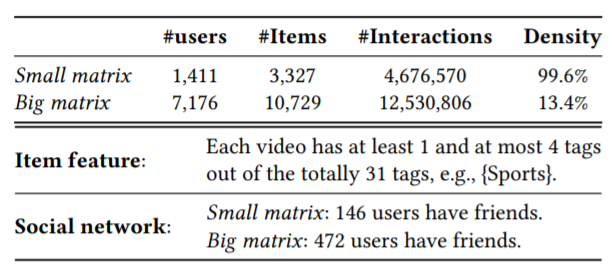
上图为属性信息,主要包含item feature和社交网络两部分。
1.1 相关链接:
论文:https://arxiv.org/abs/2202.10842
数据:https://rec.ustc.edu.cn/share/598635c0-9585-11ec-8259-414ede1f8d4f
代码:https://chongminggao.github.io/KuaiRec/
Example:http://m6z.cn/5U6xyQ
作者主页:https://chongminggao.me/
1.2 构建方法
- 所有数据均来源于2020年7月5日至2020年9月5日快手APP上的交互记录;
- 用户和视频均带有快手平台标记的“高质量”标签
- 对于缺失值(即用户未观看的其余视频),团队操纵在线推荐规则将这些视频强制推荐给用户,此过程持续了15天。
- 小矩阵的密度为99.6%,而非100%,是因为有部分用户显式的屏蔽过某些视频作者,导致无法将这些视频曝光给用户。
1.3 代表性验证
- 用
Kolmogorov–Smirnov假设检验来验证了收集到的小矩阵中的用户与视频与快手数据中的用户与视频有着同样的分布。即验证了小矩阵中的用户和视频具有代表性。
1.4 相关实验
作者选择用这个数据集来探究对话推荐系统中的一些关键问题,包括两方面:
- 首先,部分观察到的数据(有偏差和无偏差)如何影响 CRS 的评估?
- 我们能否通过估计缺失值(即矩阵补全)来改进对部分观测数据的评估?
除此之外,作者还探究了两个因素在评估中的影响:
- 观测数据的密度:从全曝光小矩阵中采样出不同密度的数据,使得观测密度在区间:{10%,20%,…, 100%}中。
- 曝光偏差的种类:通过随机性采样,基于流行商品的采样,以及基于正样本的采样,分别用以模拟部分曝光中的无偏数据、流行偏差、以及正样本偏差。
2. 数据集下载
数据下载链接:https://rec.ustc.edu.cn/share/598635c0-9585-11ec-8259-414ede1f8d4f
下载并解压数据集后,data文件夹中保存的是大矩阵和小矩阵,以及属性信息。
2.1 big matrix
big matrix:即图(b)中的蓝色部分,包含了7176名用户对10729个视频的12530806条交互记录,density为13.4%
2.1 small matrix
small matrix:即图(b)中的红色部分,包含了1411名用户对3327个视频的4676570条交互记录,density为99.6%.
2.3 item_feat
item_feat:每个视频最多包含4个tags(如体育、游戏…),共有31种tags。

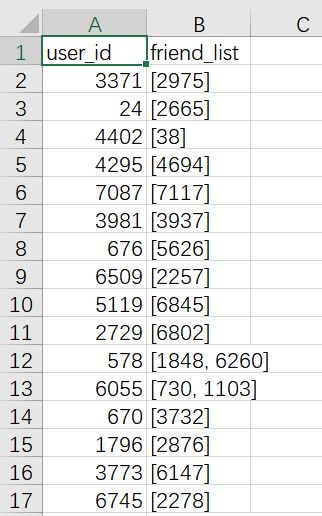
2.4 social_network
social_network: 用户社交网络数据;小矩阵中共有146名用户有社交关系,大矩阵中共有472名用户有社交关系。
loaddata.py和Statistic_KuaiRec.ipynb都是作者提供的加载数据集的代码
2.5 注意点
1.(最新版本的数据集已经修复这个bug啦) video_id = 1225是空缺值,这个video不存在任何交互记录~,处理时需要注意一下
如,负采样时:
neg = item + 1while neg <= max_item:if neg == 1225: # 1225 is an absent video_idneg = 1226
3. 数据集处理
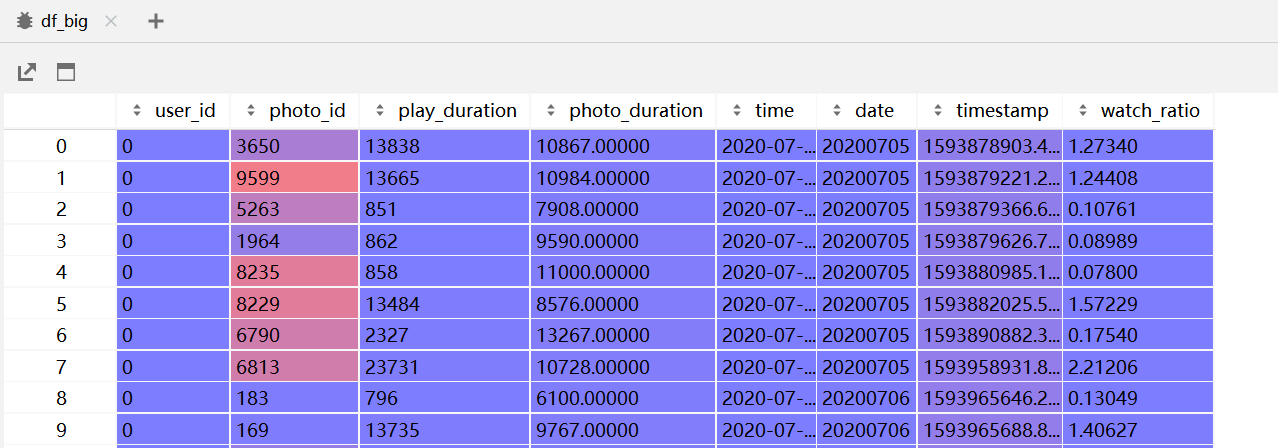
3.1 数据集读取
- 将
filePath改成数据集路径
filePath= "../environments/KuaishouRec/data/big_matrix.csv" # 写自己的路径
df_big = pd.read_csv(filePath)
注意一下,图中的photo_id就是csv文件中的video_id~(我下载的是老版本数据,当时还没有修改列名)
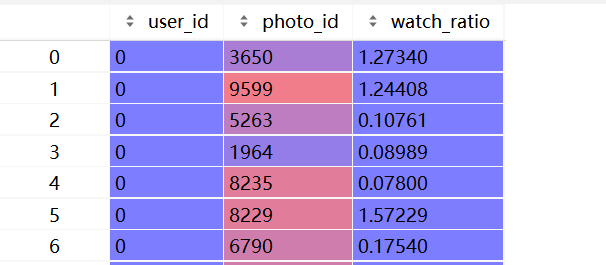
- 指定读取列,如只需要
u,i,r数据:
df_big = pd.read_csv(filePath, usecols=['user_id', 'photo_id', 'watch_ratio'])
3.2 划分训练集测试集
因为作者给出的是一个大数据集,并没有划分训练集和测试集,需要我们自己划分;调用sklearn.model_selection import train_test_split库就可以轻松划分了。
from sklearn.model_selection import train_test_split
import os
import pandas as pdDATAPATH = "../environments/KuaishouRec/data"
filePath = os.path.join(DATAPATH, "big_matrix.csv")
trainpath = os.path.join(DATAPATH, "train_big_matrix.csv")
testpath = os.path.join(DATAPATH, "test_big_matrix.csv")# 开始读取
df_big = pd.read_csv(filePath, usecols=['user_id', 'video_id', 'watch_ratio'])
# watch_ratio控制范围
df_big.loc[df_big['watch_ratio'] > 5, 'watch_ratio'] = 5
x_train,x_test=train_test_split(df_big,test_size=0.2,random_state=2022)x_train.sort_values("user_id", inplace=True)
x_test.sort_values("user_id", inplace=True)# save
x_train.to_csv(trainpath, index=False)
x_test.to_csv(testpath, index=False)print("split dataset completed")
3.3 拼接物品属性
- 先读取item feature,维度为
item_num*2
data_feat = pd.read_csv(os.path.join(DATAPATH, 'item_feat.csv'))print("number of items:", len(data_feat))
- 我们想转换成
item_num*4,因为每个物品最多有4个tag;因此建立一个列表list_feat,再将物品feature读进去;最后将其转换为dataframe结构。
data_feat = pd.read_csv(os.path.join(DATAPATH, 'item_feat.csv'))print("number of items:", len(data_feat))list_feat = [0] * len(data_feat)for i in range(len(data_feat)):list_feat[i] = data_feat[str(i)]['feature_index']df_feat = pd.DataFrame(list_feat, columns=['feat0', 'feat1', 'feat2', 'feat3'], dtype=int)
- 这里要注意一下缺失值处理哦!因为本身就有
feature0,因此我们将NAN的feature置为-1,最后再统一加一。
df_feat.index.name = "video_id"# 本身就有feature=0的值,所以设置为-1,再整体加一df_feat[df_feat.isna()] = -1df_feat = df_feat + 1df_feat = df_feat.astype(int)
4. 最后我们将物品属性矩阵与大矩阵组合起来:
# 把大矩阵和item特征组合起来df_big = df_big.join(df_feat, on=['video_id'], how="left")df_big.loc[df_big['watch_ratio'] > 5, 'watch_ratio'] = 5user_features = ["user_id"]item_features = ["video_id"] + ["feat" + str(i) for i in range(4)] + ["photo_duration"]reward_features = ["watch_ratio"]
3.4 转换成稀疏矩阵
这部分是将大矩阵处理成(u,i,r)形式。
- 首先将
video_iduser_id转成离散形式
lbe_video = LabelEncoder() # 弄成离散的
lbe_video.fit(df_big['video_id'].unique())lbe_user = LabelEncoder()
lbe_user.fit(df_big['user_id'].unique())
- 利用
csr_matrix进行转化
# 类似(u,i,r)mat = csr_matrix((df_big ['watch_ratio'],(lbe_user.transform(df_big ['user_id']), lbe_photo.transform(df_big ['video_id']))),shape=(df_big ['user_id'].nunique(), df_big ['video_id'].nunique())).toarray()
3.5 social network处理
以下代码是将用户社交网络处理为稀疏矩阵:
def construct_social_mat(self):print("loading social networks...")trustNet = pd.read_csv(os.path.join(DATAPATH, 'social_network.csv'))trust_dict = dict(zip(trustNet['user_id'], trustNet['friend_list']))socialNet = sp.dok_matrix((self.n_users, self.n_users), dtype=np.int8)for user_id, friend_ids in trust_dict.items():friend_ids = friend_ids.strip('[').strip(']').split(',')for friend_id in friend_ids:socialNet[user_id, int(friend_id)] = 1return socialNet.tolil()
这篇关于中科大何向南团队+快手App联合出品 KuaiRec | 快手首个稠密为99.6%的数据集 | 相关介绍、下载、处理、使用方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



