本文主要是介绍【多模态MLLMs+图像编辑】MGIE:苹果开源基于指令和大语言模型的图片编辑神器(24.02.03开源),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目主页:https://mllm-ie.github.io/
论文 :基于指令和多模态大语言模型图片编辑 2309.Guiding Instruction-based Image Editing via Multimodal Large Language Models (加州大学圣巴拉分校+苹果)
代码:https://github.com/apple/ml-mgie | gradio_UI
媒体:机器之心的解析https://mp.weixin.qq.com/s/c87cUuyz4bUgfW2_ma5xpA
封面图

网友实测
一些概念
MLLMs: 多模态大语言模型
多模态大语言模型(Multimodal large language models ),是从预训练的LLM(大语言模型)初始化参数,MLLM添加了一个视觉编码器(visual encoder 例如,CLIP-L )来提取视觉特征 f f f,以及一个适配器(adapter) W W W(一般为简单神经网络)将特征 f f f投影到语言模态中。根据论文2304.Visual Instruction Tuning(LLaVA) :MLLMs的训练可以概括为:
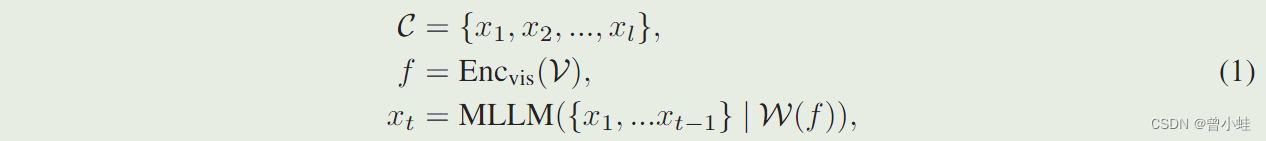
其中 l l l是 C C C 中单词切分后(word token)的长度。 C C C可以是图像标题(特征对齐)或数据的多模态指令(指令调优)。MLLM 遵循下一个单词预测的标准自回归训练,然后可以作为各种视觉任务的视觉助手(visual assistant),例如视觉问答(visual question answering)和复杂的推理(complex reasoning)。尽管 MLLM 能够通过上述训练进行视觉感知,但它的输出仍然仅限于文本。
MGIE : 多模态大语言模型引导的图像编辑
MGIE 表示:Multimodal large language model-Guided Image Editing (MGIE)
原文摘要:
基于指令(Instruction-based)的图像编辑通过自然命令提高了图像操作的可控性和灵活性,而无需详细描述或区域掩模。然而,人类的指令有时过于简短,目前的方法无法捕捉和遵循。多模态大语言模型(Multimodal large language models (MLLMs))在跨模态理解和视觉感知响应生成方面显示出很好的能力。
我们研究了(investigate) MLLM如何促进编辑指令(instructions),并提出 MLLM 引导的图像编辑 (MGIE)。
MGIE学习推导表达指令(derive expressive instructions)并提供明确指导(explicit guidance)。编辑模型共同捕获这种视觉想象,并通过端到端训练执行操作。我们评估了photoshop方式的修改,全局照片优化和局部编辑的各个方面。
大量的实验结果表明,表达性指令对于基于指令的图像编辑至关重要,我们的MGIE可以在保持竞争性推理效率的同时显著改善自动度量和人工评估。
Instruction-based image editing improves the controllability and flexibility of image manipulation via natural commands without elaborate descriptions or regional masks. However, human instructions are sometimes too brief for current methods to capture and follow. Multimodal large language models (MLLMs) show promising capabilities in cross-modal understanding and visual-aware response generation via LMs. We investigate how MLLMs facilitate edit instructions and present MLLM-Guided Image Editing (MGIE). MGIE learns to derive expressive instructions and provides explicit guidance. The editing model jointly captures this visual imagination and performs manipulation through end-to-end training. We evaluate various aspects of Photoshop-style modification, global photo optimization, and local editing. Extensive experimental results demonstrate that expressive instructions are crucial to instruction-based image editing, and our MGIE can lead to a notable improvement in automatic metrics and human evaluation while maintaining competitive inference efficiency.
主要方法
基本架构参考
InstructPix2Pix,LLaMA-7B为基线 ,着重借鉴了 LLaVA的模型
22.11.InstructPix2Pix: Learning to Follow Image Editing Instructions.
23.02.LLaMA: Open and Efficient Foundation Language Models
23.04.LLaVA: Large Language and Vision Assistant(Visual Instruction Tuning)
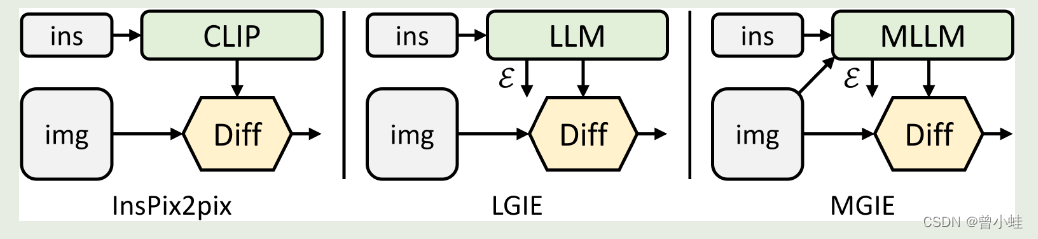
MGIR模型框架
使用的MLLMs预训练多模态模型 LLaVA-7B 进行指令调优(instruction tuning)并获得相应的视觉tokens : https://huggingface.co/liuhaotian/LLaVA-Lightning-7B-delta-v1-1 (只微调了词嵌入(word embedding)和LM head)
一个预训练的文本总结模型 Flan-T5-XXL(summarizer)获得对简洁的叙述:https://huggingface.co/google/flan-t5-xxl ,用在训练中,与生成精炼题词计算loss.
w一个是借助外部模型生成题词总结,一个是MLLM微调后输出的总结。
图 2:方法概述。
利用 MLLM 来增强基于指令的图像编辑 (“what will this image be like if [instruction]” ,来重写)。
训练好后,大视觉语言模型直接推导出简洁明确的表达指令(concise expressive instruction),并为预期目标提供明确的视觉相关指导(visual token)然后通过Edit head 注入到Diffusion模型。 扩散模型以端到端的方式通过编辑头联合训练和实现具有潜在想象的图像编辑。
其中,
Edit Head 表示:序列到序列模型 (4层transformer),它将来自 MLLM 的顺序视觉标记(sequential visual tokens)映射到语义上有意义的潜在编码 U = {u1, u2,…, uL} 作为编辑指导
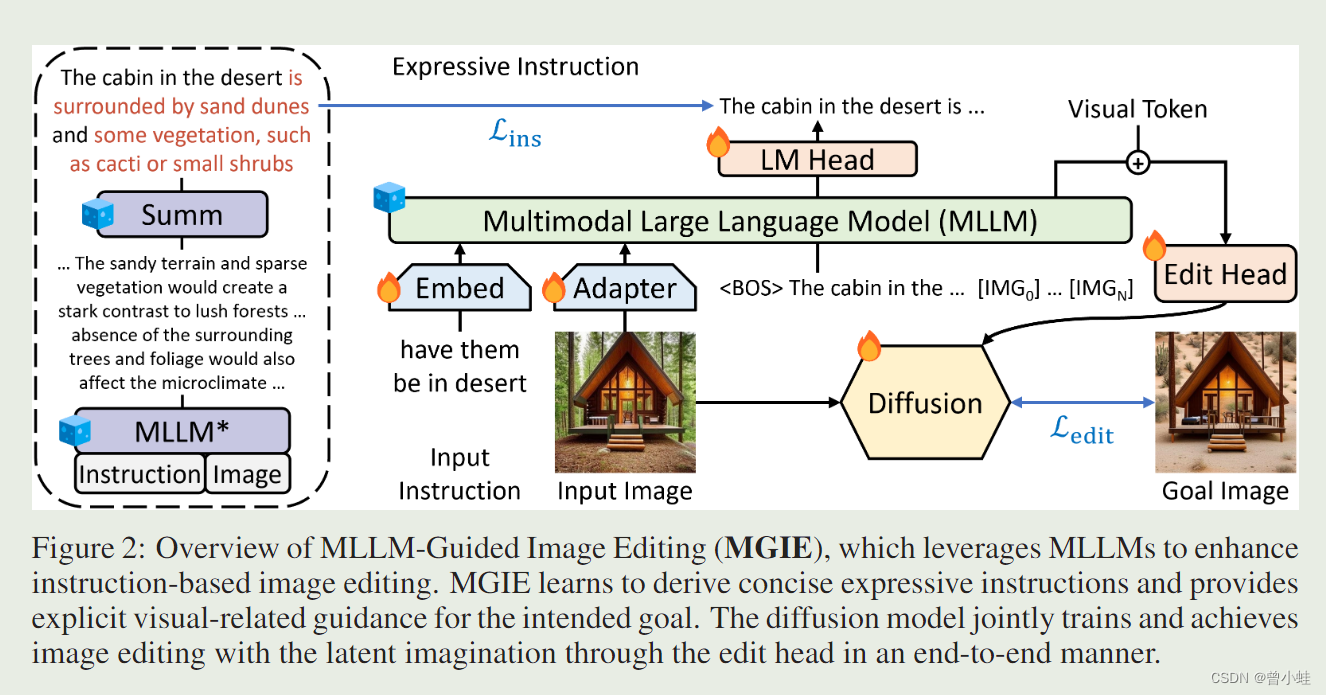
具体算法训练流程
V V V表示:输入图片
X X X表示:指令(例如具体修改意图:改颜色、修改内容)
O O O表示: 最终的目标图像
T T T:表示: 序列到序列模型 (4层transformer),它将来自 MLLM 的顺序视觉标记(sequential visual tokens)映射到语义上有意义的潜在编码 U = {u1, u2,…, uL} 作为编辑指导
u u u表示: 最终提示修改的视觉语义编辑
F F F表示:stable diffusion的预训练模型
算法 1 展示了 MGIE 学习过程。
MLLM 通过指令损失 L_ins 导出简洁指令 ε。借助 [IMG] 的潜在想象,图片转变其模态并引导 图片合成结果图像。编辑损失 L_edit 用于扩散训练。由于大多数权重可以被冻结(MLLM 内的自注意力块),因而可以实现参数高效的端到端训练。

公式2
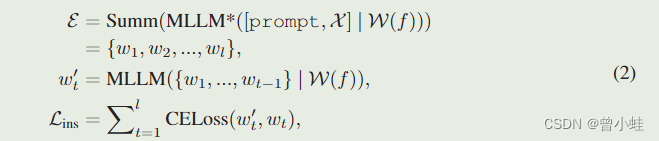
公式5
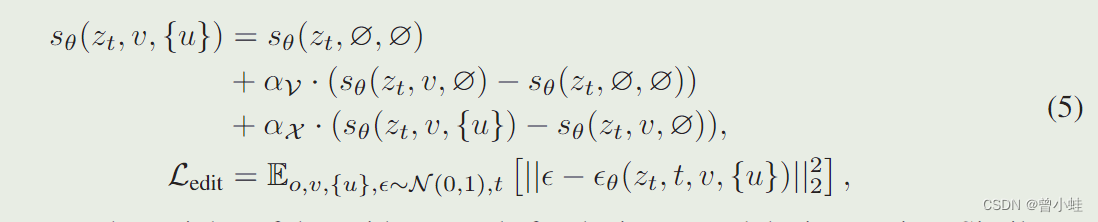
与主流方法对比

这篇关于【多模态MLLMs+图像编辑】MGIE:苹果开源基于指令和大语言模型的图片编辑神器(24.02.03开源)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




