本文主要是介绍LLM - Qwen-72B LoRA 训练与推理实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
一.引言
二.模型简介
1.Qwen-Model 总览
2.Qwen-Chat-72B
- PreTrain
- Tokenizer
- Base Line
- SFT / RLHF
3.Qwen-72 模型架构
- Config.json
- c_attn/c_proj
- Attention Forward
- ROPE
- Qwen MLP
- Qwen Block
三.QLoRA 与 Infer 实战
1.SFT 指令微调
2.Infer 推理测试
3.LLM 模型下载
四.总结
一.引言
Qwen-72B 是阿里在 23 年底最新开源的大语言模型,其模型尺寸也再次刷新国内开源模型的记录,该模型是基于 Transformer 的大语言模型,在超大规模的预训练数据上训练得到,其预训练数据覆盖全面,包括网络文本、专业书籍、代码等等。同时,在 Qwen-72B 的基础上,基于对齐机制提供了基于 LLM 的 AI 助手 Qwen-72B-Chat。本文将基于 Qwen-72B-Chat 模型进行垂类领域 LoRA 微调并在推理集群尝试 Infer 推理。
二.模型简介
1.Qwen-Model 总览
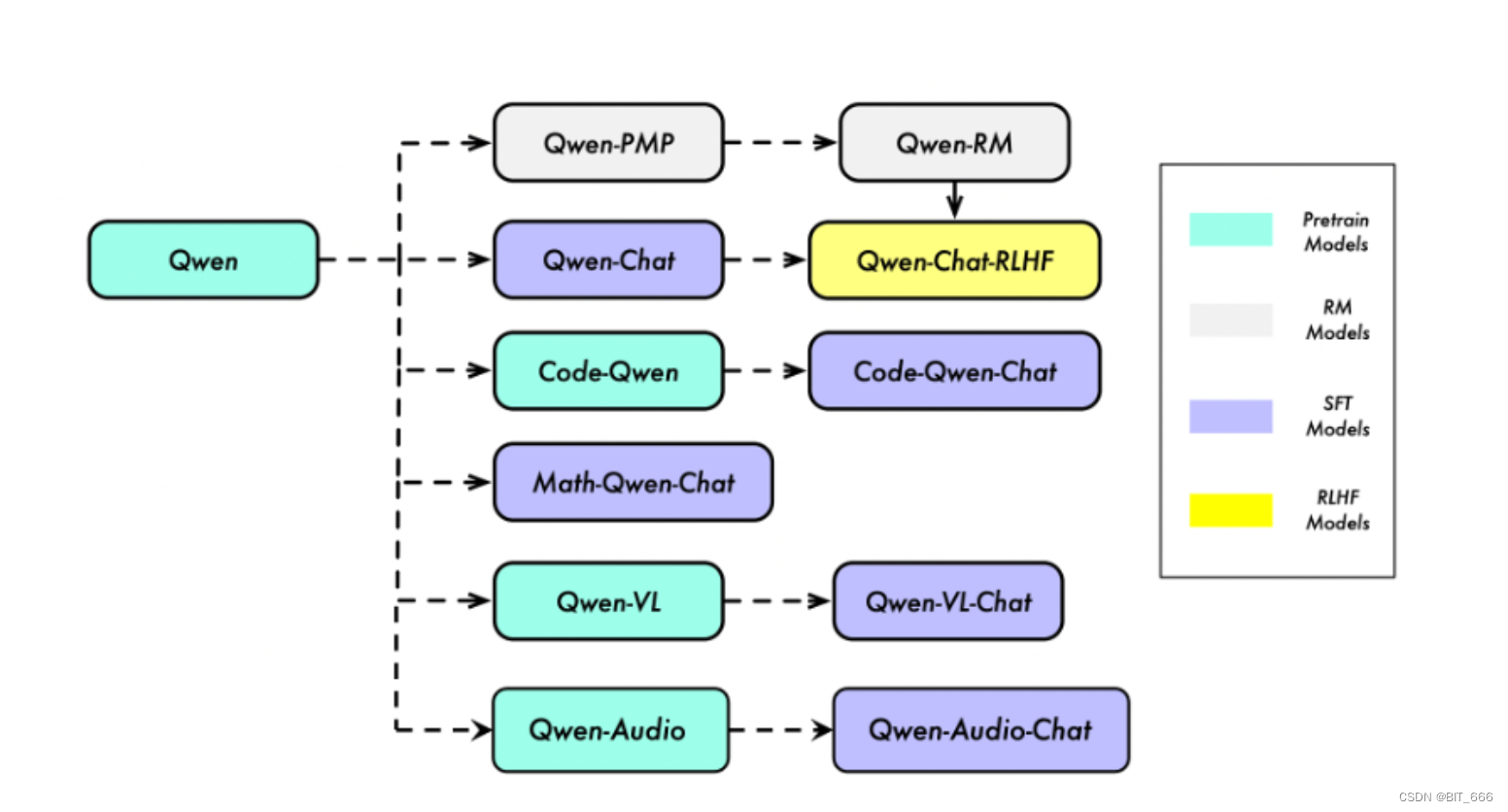
整体认知上,Qwen 不仅仅是一个包含 Base 以及 Chat 的语言类大模型,而是一个致力于实现通用人工智能(AGI)的项目,目前包含了大型语言模型(LLM)和大型多模态模型(LMM)。其下分属多个智能模块,同时覆盖多个训练场景。
按照训练场景不同,其包含了 PT - Pre Train、SFT - 有监督微调、RLHF - 强化学习人类反馈以及 RM - 奖励模型的全链路模型。本文 LoRA 使用的基座模型就是对应的 Qwen-Chat,其通过有监督微调以及 RLHF 人类反馈使其更适合应用于常用语言文本 AI 智能场景。除此之外,还有用于编程的 "Code-Qwen"、用于数学的 "Math-Qwen"、用于音频的 "Qwen-Audio" 以及视觉语言的 "Qwen-VL",基于上述模型在不同领域的特点,我们可以轻松实现文生文、文生图等工作应用场景。
2.Qwen-Chat-72B
- PreTrain
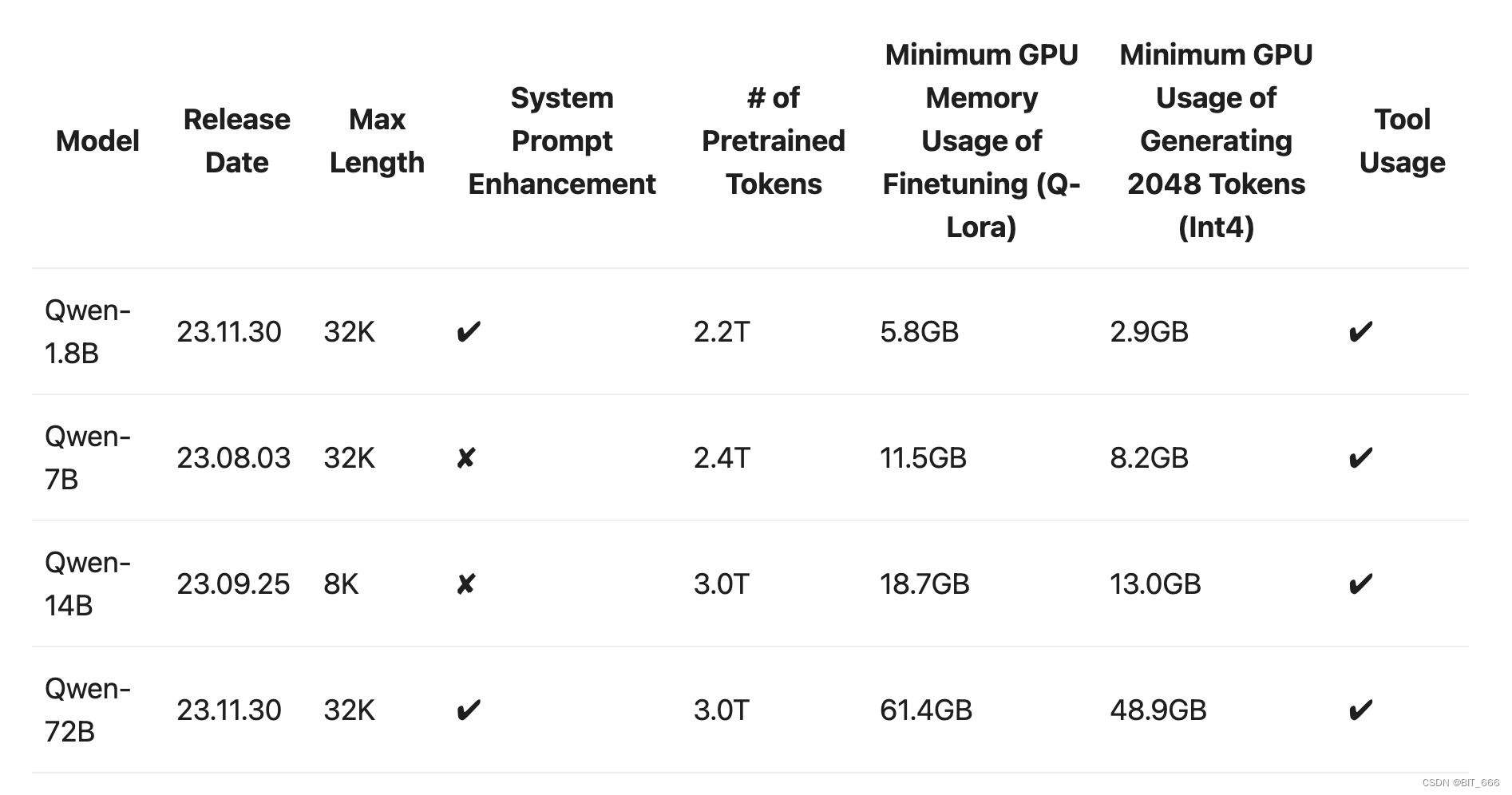
Qwen-72B 通过 3.0T Tokens 的预训练语料进行充分的训练,最大支持长度为 32k,Q-LoRA 最低显存要求为 61.4 GB,不过这里需要根据实际情况考量,博主这里实际 Q-LoRA 使用了 4 张 A-800,不过就推理而言其明显低于训练的消耗,但是显存也超过了单卡的 L40S,对卡的要求还是很高。
- Tokenizer

一个好的 Tokenizer 应当具备同等 token 数量下表征更多的文本类型,具有更高的压缩率即更高效的表达能力,Qwen本质上是一个多语言模型,而不是单一语言或双语模型。由于预训练数据的限制,该模型在英语和中文方面具有很强的能力,同时也能处理其他语言,如西班牙语、法语和日语。为了扩展其多语种能力,Qwen 采用了一种在编码不同语言信息方面具有高效率的分词器。与其他分词器相比,该分词器在一系列语言中展示了高压缩率。
- Base Line

评估基准显示,开源模型 Qwen-72B 以及最大的私有模型在性能上与 Llama 2、GPT-3.5 和 GPT-4具有竞争力。这里是对基础 Base语言模型的评估,一个好的 Base 模型可以为后续SFT(有监督微调)和 RLHF(强化学习人类反馈)做更好的基础。
- SFT / RLHF

这里将训练涉及的两种技术(SFT, RLHF)统称为 "对齐"。目前的共识是可以通过相对较少量的微调数据获得一个聊天模型。Qwen 专注于提高 SFT 数据的多样性和复杂性,并通过人工检查和自动评估严格控制质量。 基于一个良好的 SFT 模型,可以进一步探索 RLHF 的效果。特别是基于PPO(近端策略优化)的方法,但训练 RLHF 是困难的。除了 PPO 训练的不稳定性之外,另一个关键是奖励模型的质量。因此,Qwen 在构建可靠的奖励模型上进行了大量努力,通过在大规模偏好数据上进行奖励模型预训练,以及在精心标记的高质量偏好数据上进行微调。与 SFT 模型相比,我们发现经过 RLHF 的模型更具创造性,更好地遵循指令,因此其生成的回复更受人类评注者的青睐。当然,在垂类领域方面,我们也可以基于 DPO 轻量化的实现人类偏好专注,提高模型能力的偏向性,注意这里 RM-Model 或者 DPO 中构建的偏好 Pair 严格意义上并不一定代表一个是好的,一个是不好的,而是对于不同的场景,更加偏向哪个选择。
3.Qwen-72 模型架构
上面对 Qwen-72B 的基础信息做了了解,下面我们结合 HuggingFace 上的 modeling.py,简单看下 Qwen 模型的结构。
- Config.json
{"architectures": ["QWenLMHeadModel"],"auto_map": {"AutoConfig": "configuration_qwen.QWenConfig","AutoModelForCausalLM": "modeling_qwen.QWenLMHeadModel"},"attn_dropout_prob": 0.0,"bf16": false,"emb_dropout_prob": 0.0,"fp16": false,"fp32": false,"hidden_size": 8192,"intermediate_size": 49152,"initializer_range": 0.02,"kv_channels": 128,"layer_norm_epsilon": 1e-06,"max_position_embeddings": 32768,"model_type": "qwen","no_bias": true,"num_attention_heads": 64,"num_hidden_layers": 80,"onnx_safe": null,"rope_theta": 1000000,"rotary_emb_base": 1000000,"rotary_pct": 1.0,"scale_attn_weights": true,"seq_length": 32768,"tie_word_embeddings": false,"tokenizer_class": "QWenTokenizer","transformers_version": "4.32.0","use_cache": true,"use_dynamic_ntk": false,"use_flash_attn": "auto","use_logn_attn": false,"vocab_size": 152064
}首先来看下 Qwen-72B 默认的模型配置,我们主要看几个关键的参数:
"hidden_size": 8192 隐层大小
"max_position_embeddings": 32768 这里与 seq_len 是一样的,表示 32k 的上下文长度
"num_attention_heads": 64 head 的数量为 64,作为参考 Baichuan-2-13B 的 head 数为 40
"num_hidden_layers": 80 堆叠的 Decoder 数量,作为参考的 Baichuan-2-13B 为 40
"vocab_size": 152064 词库的大小,以 XVERSE-65B 作为参考,其 vocab 数量为 100534
"rope_theta": 1000000 ROPE 旋转位置编码里 θ 的空间,大概长这样,其中 d 为向量维度:
![]()
可以看到 Qwen-72B 作为新开源的大模型,其在上下文长度、词库等方面都做到了较大的提升。
- c_attn/c_proj

LoRA 微调中增加 adapter 的两个 Linear 层分别为 c_attn 与 c_proj,size 分别为 hidden_size x 3倍的投影 size,c_proj 为 hidden_size x 投影 size 的 Linear 层,其中投影层 projection_size 由多头机制的 num_heads 与 kv_channels 决定。这里通过 c_attn 可以获取 Q/K/V 的对应 Embedding,所以有 x3 的操作,因为后续 forard 计算时会进行 split 操作:
mixed_x_layer = self.c_attn(hidden_states)query, key, value = mixed_x_layer.split(self.split_size, dim=2)- `c_attn` (即 "concatenated attention") 层通常负责计算查询(Query)、键(Key)和值(Value)向量。在 Transformer 架构中,每个注意力头的输入会通过一个线性层(`c_attn`)来生成这三个向量。具体地,给定输入 `x`,`c_attn` 会应用一个线性变换,其参数是连接在一起的权重矩阵。然后,这个连接后的输出会被分割成独立的查询、键和值分量,它们分别用于计算注意力分数。
- `c_proj` (即 "projection of concatenated outputs") 层则负责将多个注意力头的输出连接在一起,并通过一个线性变换投影到一个较小的维度空间,从而产生该层的最终输出。注意力头的输出首先被合并起来,然后 `c_proj` 会对合并后的结果应用另一个线性转换来获得期望输出的大小。
`c_attn` 层实现了多头自注意力机制的关键部分,它允许模型学习数据中的不同表示形式;而 `c_proj` 层确保了这些表示可以被有效整合,并为后续层提供了恰当的输入。这两个层在 Transformer 架构中是至关重要的,它们共同负责模型的核心操作——自注意力机制的实现和多头注意力信息的整合,所以 LoRA 时 c_attn、c_proj 都是我们选择的对象。
- Attention Forward

这里 QwenAttention 层的 forward 遵照了 Multi-Head Attention 的实现思路,经过 c_attn 后得到的 Q/K/V 分别 split_heads 分为多头并对 Q/K 应用 rotary_pos_emb ROPE 旋转 Embedding 添加位置信息,这里 Qwen 的 θ 设置的比较大,其 PE 的外推性也会更好。
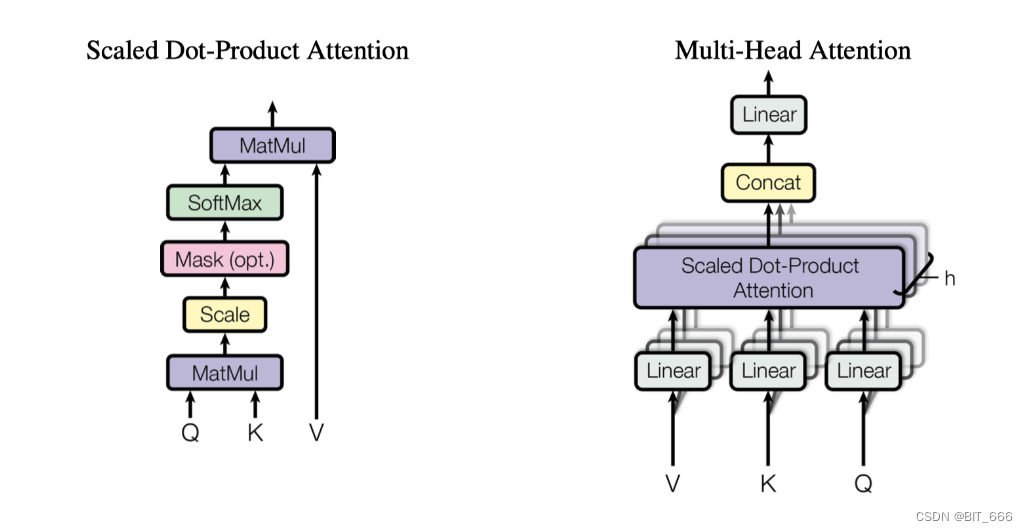
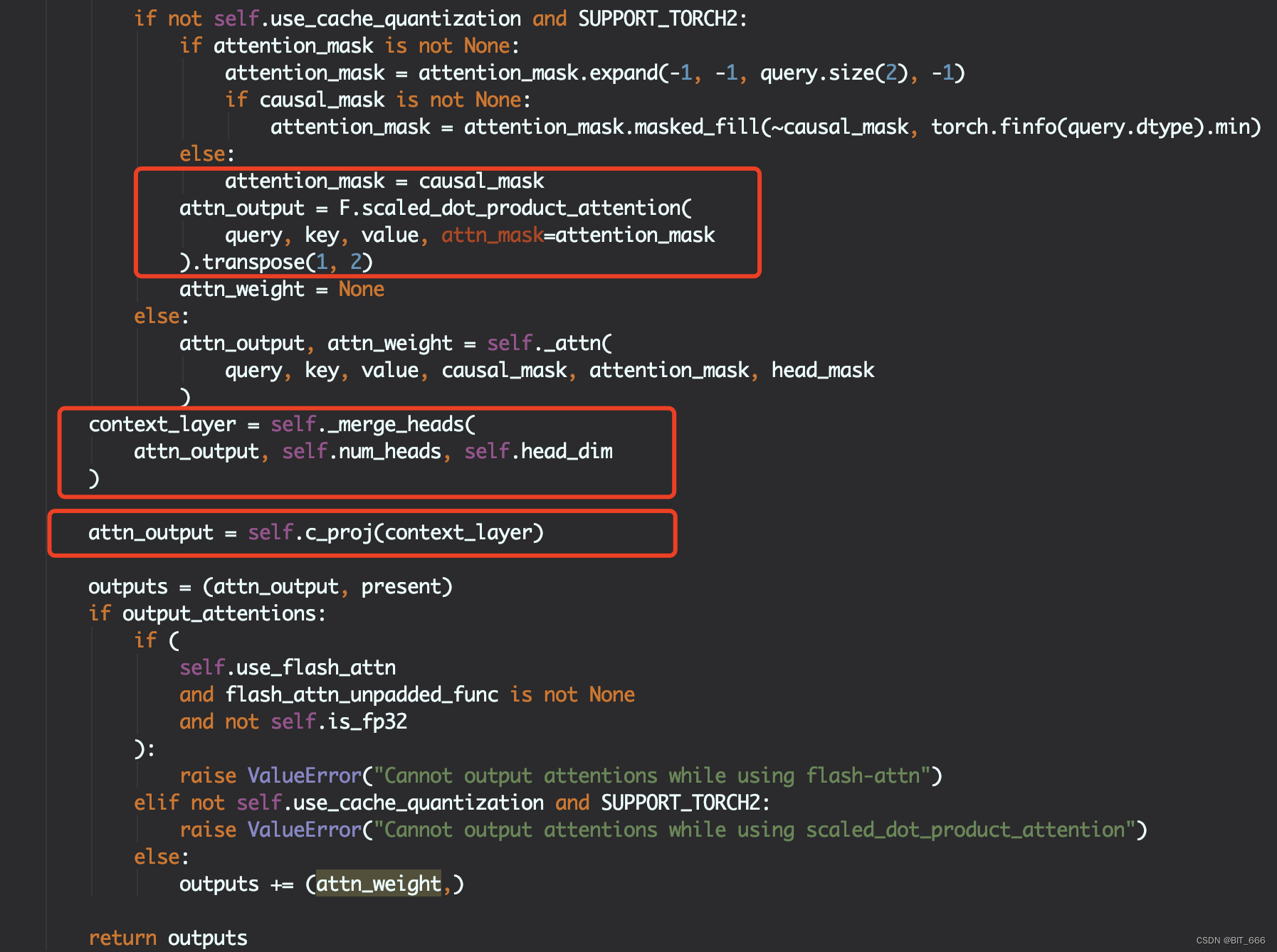
计算 Scaled_dot_product_attention,合并多头输出,通过 c_proj 转换得到 output 输出,这里 self.attn 方法为完整的基于 causal_mask 计算 Weights 并得到最终 Weighted-Output 的方法。
- ROPE
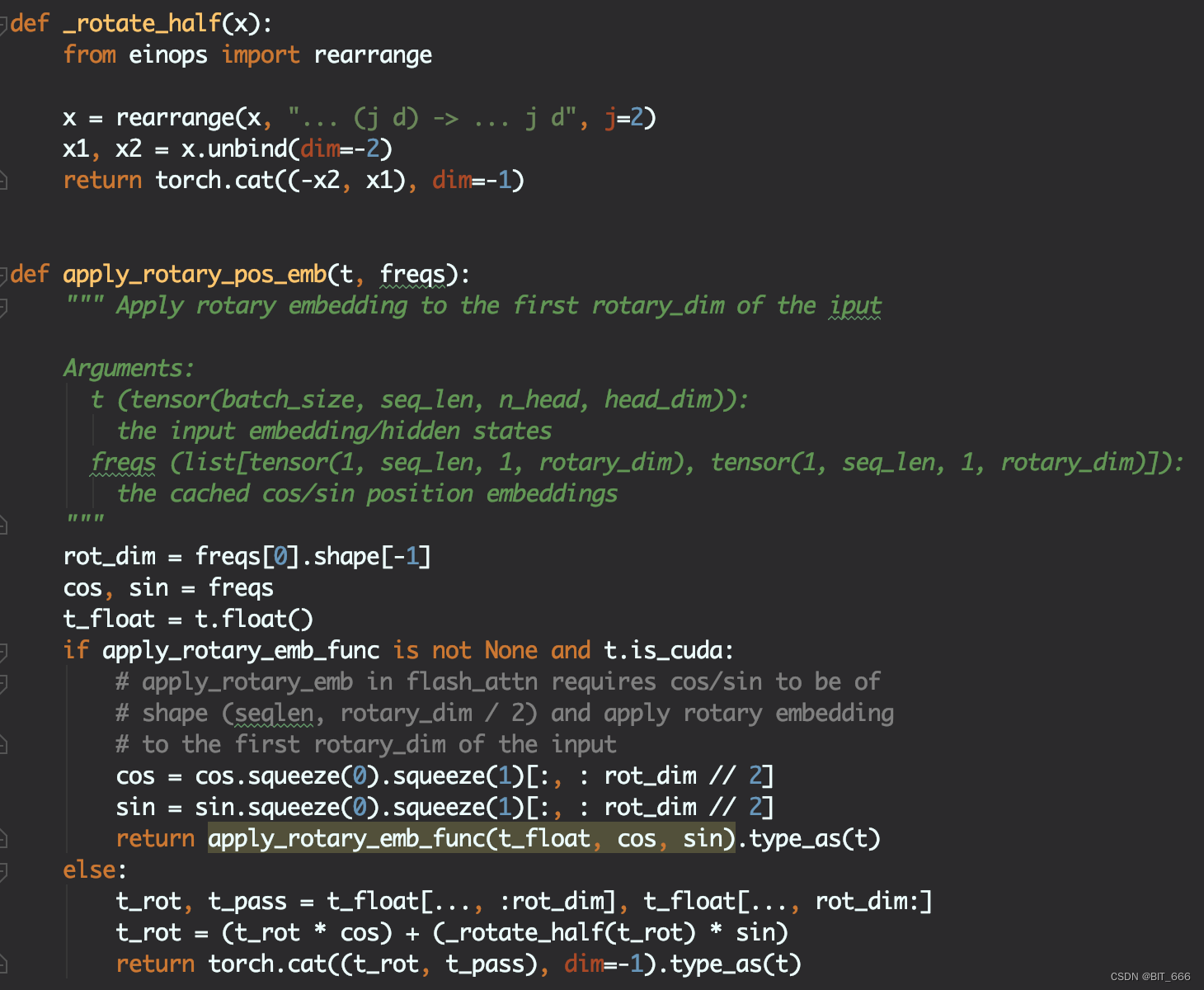
关于 ROPE 的由来与代码实现,博主在前面做了详细的分享,大家可以参考下面的链接,简单点来说,其通过下面优化的矩阵乘方式为 Q/K 引入位置信息,使的 token 能够在 Attention 计算中感知到相对位置信息。

ROPE 详解: LLM - 通俗理解位置编码与 RoPE_llm 位置编码-CSDN博客
ROPE 代码详解: LLM - 旋转位置编码 RoPE 代码详解_旋转位置编码 源码-CSDN博客
- Qwen MLP

LLM 中的 MLP 层是构成模型的主要组成部分之一。在 Transformer 架构中,MLP 层通常位于自注意力(Self-Attention)机制层后面,并且每个 Transformer 块中都有一个 MLP 层。通常我们认为 Attention 层负责抽取文本的浅层含义,而 MLP 层负责获取文本的语义即更深层的含义,这里 intermediate_size 参数通常在 Transformer 模型的配置中出现,它指的是 Transformer 块内MLP 层的隐藏单元数目。换句话说,它决定了在进入 MLP 层的前馈神经网络之前,经过自注意力计算后的 embedding 表示会被投影到一个更高维度的空间。通常情况下,该参数的大小为 hidden_states 的数倍,这里共有两个线性转换层:
w1 - 从 hidden_size 维映射到 intermediate_size // 2 维
w2 - 从 hidden_size 维映射到 intermediate_size // 2 维,并伴随一个 silu 激活函数

这里 mlp 的逻辑是 w1、w2 线性转换后进行哈达玛积,这里也是其基于传统 Attention 的一个改变即 parallel_product,最后再通过 c_proj 转换为 hidden_status 的维度。 更大的 intermediate_size 可能使模型能够捕捉更复杂的特征,但也会导致更多的计算开销和更大的模型尺寸,这里 intermediate_size = 49152,是 hidden_size = 8192 的 6 倍。
- Qwen Block

根据 config 的参数 num_hidden_layers = 80,Qwen 模型共计堆叠了 80 个 Block,其中每个 Block 是一个标准的 Decoder-Only 的结构,其包含两个 RMSNorm 的归一化 Layer:

除此之外包含一个标准的 Attention Layer 以及最后的 MLP 深度部分。

其完整的 Block 前向逻辑计算也很清晰,除了上面介绍的 Attention、RMSNormal 外,还涉及到两个类似 RNN 的残差网络,防止模型遗忘的情况。 Block 中很多结构都与 LLAMA-2 有异曲同工之妙,关于 LLAMA-2 与 LoRA 参数的详细内容可以参考下述链接:
LLAMA-2 模型结构: LLM - Transformer && LLaMA2 结构分析与 LoRA 详解-CSDN博客
Tips:
上面简单介绍了 Qwen-72B Transformer 模型的基础组件: c_attn、c_proj、w1、w2、mlp.cproj 及其对应的功能,这些组件也是我们 LoRA 训练中主要涉及到的 Layer 层。除此之外,模型中应用了诸如 KV-Cache、Flash Attention 等优化的操作,这些博主会在后面努力学习,争取和大家一起分享。
三.QLoRA 与 Infer 实战
1.SFT 指令微调
source /root/.bashrc && accelerate launch --config_file /jfs/train/acc_config.yaml /jfs/codes/start/train_bash.py \--stage sft \--do_train \--dataset_dir /jfs/train/dataset \--dataset ${dataset_identify} \--finetuning_type lora \--lora_rank 8 \--template $template \--model_name_or_path $base_model_path \--lora_target c_attn,attn.cproj,w1,w2,mlp.cproj \--output_dir $output_dir \--overwrite_cache \--overwrite_output_dir \--per_device_train_batch_size 2 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 500 \--save_strategy epoch \--learning_rate 1e-4 \--num_train_epochs 3.0 \--quantization_bit 4 \--bf16这里训练基于 LLAMA-Factory 框架,其中:
lora_rank = 8
lora_target = c_attn, attn_cproj,w1,w2,mlp.cproj
bsz = 2
quantization_bit = 4
由于模型尺寸非常大,因此我们采用 QLora 的训练方式,通过 4-bit 方式缩减模型占用显存,除此之外 batch_size 也不能设置太大,对于过长的文本容易在训练中引发 oom,lora_rank 大家也可以尝试 16,如果内存不爆的话 ... 学习率默认为 5e-5,这里 epoch 设置的较小,适当增加了学习率。使用上述配置我们可训参数大概约为 6kw,约占总参数量的 0.087%,可以看到 72B 模型确实很庞大:
![]()
训练样本量约为 2.6w,根据 PT、SFT 场景的不同,样本的数量也会有差异:

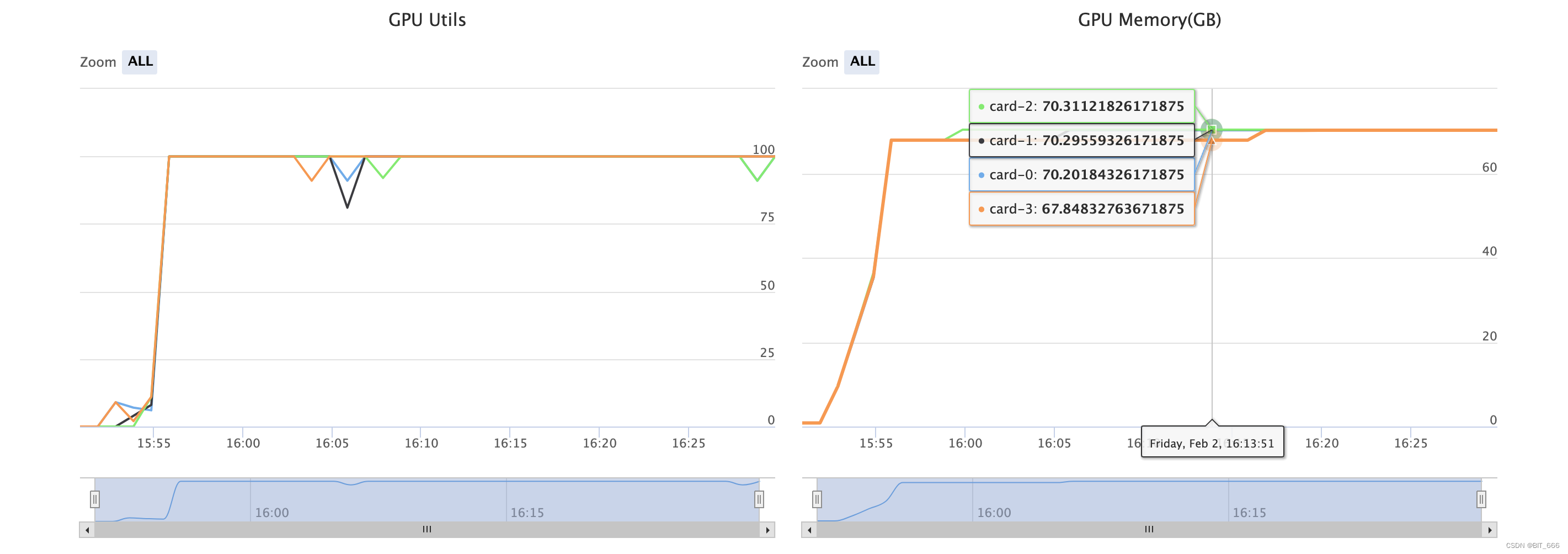
这里采用 4-bit 量化模型训练,训练过程中使用了 4 x A800 的配置,训练期间显存几乎全部打满:
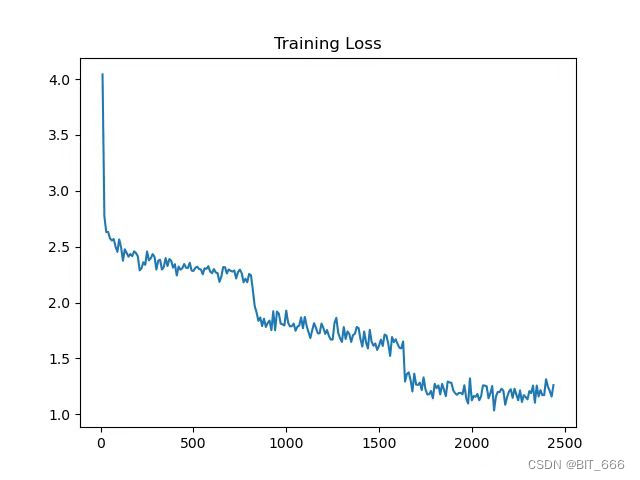
模型训练 LOSS 由 4+ 经过 3 轮 epoch 下降至 1.5 左右,可以看到在每一个 epoch 结束后,loss 会存在一个明显的向下阶跃:
2.Infer 推理测试
{"chat_format": "chatml","eos_token_id": 151643,"pad_token_id": 151643,"max_window_size": 6144,"max_new_tokens": 512,"do_sample": true,"emperature": 0.95,"top_k": 50,"top_p": 0.8,"repetition_penalty": 1.1,"transformers_version": "4.31.0"
}生成参数简单总结下:

这里推理实测需要 A800 x 2,推理时显存几乎全部使用,由于是内部数据,这里推理效果就不给大家展示了,不过实测 Qwen-72B-Chat 在微调 3 轮后已经在对应 SFT 语料上具备匹配 GPT-3.5 甚至更高尺寸模型的能力:

更详细的参数释义可以参考: LLM - model batch generate 生成文本_repetition_penalty-CSDN博客
3.LLM 模型下载
这里 LoRA 模型的第一步是下载模型,Qwen-72B-Chat 下载异常缓慢且经常出错,所以这里写了一个 While True 的脚本,跑起来之后就不管了,直到 need_download_files 里的文件全部下载完毕才会退出 while 循环。需要下载的文件可以到 HF 的官网手动获取,也可以通过爬虫指定 repo_id 自动获取。
#!/usr/bin/python
# -*- coding: UTF-8 -*-from huggingface_hub import snapshot_download
from huggingface_hub import hf_hub_download
import os# 获取待下载文件
need_download_files = [".gitattributes","LICENSE","NOTICE","README.md","cache_autogptq_cuda_256.cpp","cache_autogptq_cuda_kernel_256.cu","config.json","configuration_qwen.py","cpp_kernels.py","generation_config.json","model-00001-of-00082.safetensors","model-00002-of-00082.safetensors","model-00003-of-00082.safetensors","model-00004-of-00082.safetensors","model-00005-of-00082.safetensors","model-00006-of-00082.safetensors","model-00007-of-00082.safetensors","model-00008-of-00082.safetensors","model-00009-of-00082.safetensors","model-00010-of-00082.safetensors","model-00011-of-00082.safetensors","model-00012-of-00082.safetensors","model-00013-of-00082.safetensors","model-00014-of-00082.safetensors","model-00015-of-00082.safetensors","model-00016-of-00082.safetensors","model-00017-of-00082.safetensors","model-00018-of-00082.safetensors","model-00019-of-00082.safetensors","model-00020-of-00082.safetensors","model-00021-of-00082.safetensors","model-00022-of-00082.safetensors","model-00023-of-00082.safetensors","model-00024-of-00082.safetensors","model-00025-of-00082.safetensors","model-00026-of-00082.safetensors","model-00027-of-00082.safetensors","model-00028-of-00082.safetensors","model-00029-of-00082.safetensors","model-00030-of-00082.safetensors","model-00031-of-00082.safetensors","model-00032-of-00082.safetensors","model-00033-of-00082.safetensors","model-00034-of-00082.safetensors","model-00035-of-00082.safetensors","model-00036-of-00082.safetensors","model-00037-of-00082.safetensors","model-00038-of-00082.safetensors","model-00039-of-00082.safetensors","model-00040-of-00082.safetensors","model-00041-of-00082.safetensors","model-00042-of-00082.safetensors","model-00043-of-00082.safetensors","model-00044-of-00082.safetensors","model-00045-of-00082.safetensors","model-00046-of-00082.safetensors","model-00047-of-00082.safetensors","model-00048-of-00082.safetensors","model-00049-of-00082.safetensors","model-00050-of-00082.safetensors","model-00051-of-00082.safetensors","model-00052-of-00082.safetensors","model-00053-of-00082.safetensors","model-00054-of-00082.safetensors","model-00055-of-00082.safetensors","model-00056-of-00082.safetensors","model-00057-of-00082.safetensors","model-00058-of-00082.safetensors","model-00059-of-00082.safetensors","model-00060-of-00082.safetensors","model-00061-of-00082.safetensors","model-00062-of-00082.safetensors","model-00063-of-00082.safetensors","model-00064-of-00082.safetensors","model-00065-of-00082.safetensors","model-00066-of-00082.safetensors","model-00067-of-00082.safetensors","model-00068-of-00082.safetensors","model-00069-of-00082.safetensors","model-00070-of-00082.safetensors","model-00071-of-00082.safetensors","model-00072-of-00082.safetensors","model-00073-of-00082.safetensors","model-00074-of-00082.safetensors","model-00075-of-00082.safetensors","model-00076-of-00082.safetensors","model-00077-of-00082.safetensors","model-00078-of-00082.safetensors","model-00079-of-00082.safetensors","model-00080-of-00082.safetensors","model-00081-of-00082.safetensors","model-00082-of-00082.safetensors", "model.safetensors.index.json","modeling_qwen.py","qwen.tiktoken","qwen_generation_utils.py","special_tokens_map.json","tokenization_qwen.py","tokenizer_config.json"]# 获取当前已下载成功的文件
def list_files_in_folder(folder_path):file_set = set()for root, dirs, files in os.walk(folder_path):for file in files:file_set.add(file)return file_set# 下载指定文件
def download_file(repo_id, local_dir, filename):snapshot_download(repo_id="Qwen/Qwen-72B-Chat", local_dir='/jfs/train/models/Qwen-72B-Chat', local_dir_use_symlinks=False, allow_patterns=[filename])def pre_download():# 目标路径folder_path = '/jfs/train/models/Qwen-72B-Chat'success_files = list_files_in_folder(folder_path)# 循环判断while len(success_files) != len(need_download_files):for filename in need_download_files:try:if filename not in success_files:print(f"{filename} Start Download ...")download_file(repo_id, local_dir, filename)except Exception as e:print("An error occurred:", e)success_files = list_files_in_folder(folder_path)pre_download()全部模型文件包含 82 个 safetensors,总计约为 135G,在脚本中导入 HF 镜像并执行上述脚本即可,下载了 2 天 2 夜终于搞定了:
cmd_exec="export HF_ENDPOINT=https://hf-mirror.com && python /jfs/train/models/getModel.py"
四.总结
国内的大模型竞争越来越激烈,更多的开源模型也会陆续问世,在当前环境下,除了模型本身表达能力提高外,拥有自己场景下独一无二的数据也是十分关键的事情,Data x LLM x GPU 是未来大模型的发展方向,当然最后还需要一个应用场景,从而实现 AIGC 的切实落地。
这篇关于LLM - Qwen-72B LoRA 训练与推理实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



