2019独角兽企业重金招聘Python工程师标准>>> 
前面博主介绍了sql中join功能的大数据实现,本节将继续为小伙伴们分享倒排索引的建立。
一、需求
在很多项目中,我们需要对我们的文档建立索引(如:论坛帖子);我们需要记录某个词在各个文档中出现的次数并且记录下来供我们进行查询搜素,这就是我们做搜素引擎最基础的功能;分词框架有开源的CJK等,搜素框架有lucene等。但是当我们需要建立索引的文件数量太多的时候,我们使用lucene来做效率就会很低;此时我们需要建立自己的索引,可以使用hadoop来实现。
图1、待统计的文档
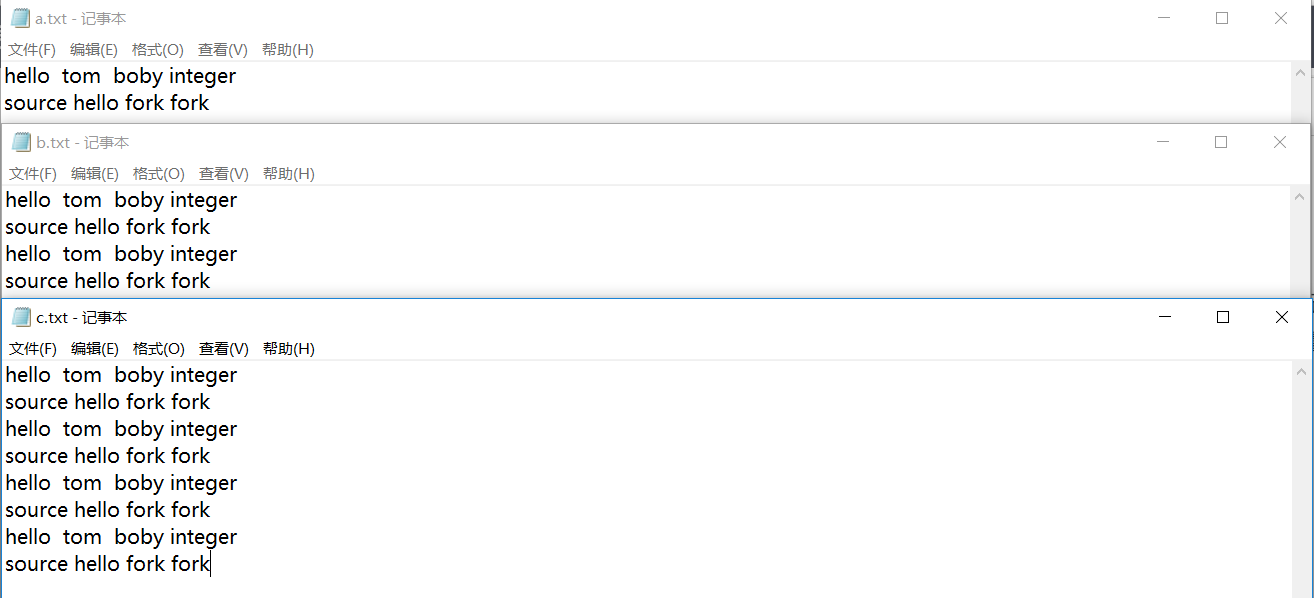
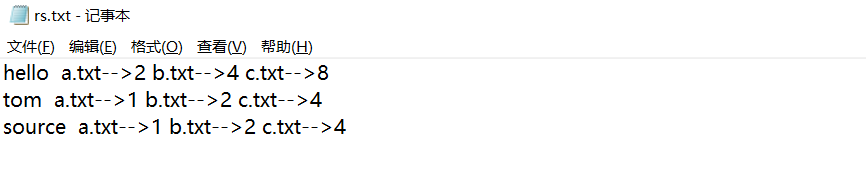
图2、建立的索引文件效果
二、代码实现
step1:map-reduce
package com.empire.hadoop.mr.inverindex;import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class InverIndexStepOne {static class InverIndexStepOneMapper extends Mapper<LongWritable, Text, Text, IntWritable> {Text k = new Text();IntWritable v = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();String[] words = line.split(" ");FileSplit inputSplit = (FileSplit) context.getInputSplit();String fileName = inputSplit.getPath().getName();for (String word : words) {k.set(word + "--" + fileName);context.write(k, v);}}}static class InverIndexStepOneReducer extends Reducer<Text, IntWritable, Text, IntWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {int count = 0;for (IntWritable value : values) {count += value.get();}context.write(key, new IntWritable(count));}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf);job.setJarByClass(InverIndexStepOne.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));// FileInputFormat.setInputPaths(job, new Path(args[0]));// FileOutputFormat.setOutputPath(job, new Path(args[1]));job.setMapperClass(InverIndexStepOneMapper.class);job.setReducerClass(InverIndexStepOneReducer.class);job.waitForCompletion(true);}}
step2:map-reduce
package com.empire.hadoop.mr.inverindex;import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class IndexStepTwo {public static class IndexStepTwoMapper extends Mapper<LongWritable, Text, Text, Text> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();String[] files = line.split("--");context.write(new Text(files[0]), new Text(files[1]));}}public static class IndexStepTwoReducer extends Reducer<Text, Text, Text, Text> {@Overrideprotected void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException {StringBuffer sb = new StringBuffer();for (Text text : values) {sb.append(text.toString().replace("\t", "-->") + "\t");}context.write(key, new Text(sb.toString()));}}public static void main(String[] args) throws Exception {if (args.length < 1 || args == null) {args = new String[] { "D:/temp/out/part-r-00000", "D:/temp/out2" };}Configuration config = new Configuration();Job job = Job.getInstance(config);job.setJarByClass(IndexStepTwo.class);job.setMapperClass(IndexStepTwoMapper.class);job.setReducerClass(IndexStepTwoReducer.class);// job.setMapOutputKeyClass(Text.class);// job.setMapOutputValueClass(Text.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 1 : 0);}
}
三、执行程序
#上传jarAlt+p
lcd d:/
put IndexStepOne.jar IndexStepTwo.jar
put a.txt b.txt c.txt#准备hadoop处理的数据文件cd /home/hadoop
hadoop fs -mkdir -p /index/indexinput
hdfs dfs -put a.txt b.txt c.txt /index/indexinput#运行程序hadoop jar IndexStepOne.jar com.empire.hadoop.mr.inverindex.InverIndexStepOne /index/indexinput /index/indexsteponeoutput hadoop jar IndexStepTwo.jar com.empire.hadoop.mr.inverindex.IndexStepTwo /index/indexsteponeoutput /index/indexsteptwooutput 四、运行效果
[hadoop@centos-aaron-h1 ~]$ hadoop jar IndexStepOne.jar com.empire.hadoop.mr.inverindex.InverIndexStepOne /index/indexinput /index/indexsteponeoutput
18/12/19 07:08:42 INFO client.RMProxy: Connecting to ResourceManager at centos-aaron-h1/192.168.29.144:8032
18/12/19 07:08:43 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/12/19 07:08:43 INFO input.FileInputFormat: Total input files to process : 3
18/12/19 07:08:43 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
18/12/19 07:08:44 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1545173547743_0001
18/12/19 07:08:45 INFO impl.YarnClientImpl: Submitted application application_1545173547743_0001
18/12/19 07:08:45 INFO mapreduce.Job: The url to track the job: http://centos-aaron-h1:8088/proxy/application_1545173547743_0001/
18/12/19 07:08:45 INFO mapreduce.Job: Running job: job_1545173547743_0001
18/12/19 07:08:56 INFO mapreduce.Job: Job job_1545173547743_0001 running in uber mode : false
18/12/19 07:08:56 INFO mapreduce.Job: map 0% reduce 0%
18/12/19 07:09:05 INFO mapreduce.Job: map 33% reduce 0%
18/12/19 07:09:20 INFO mapreduce.Job: map 67% reduce 0%
18/12/19 07:09:21 INFO mapreduce.Job: map 100% reduce 100%
18/12/19 07:09:23 INFO mapreduce.Job: Job job_1545173547743_0001 completed successfully
18/12/19 07:09:23 INFO mapreduce.Job: Counters: 50File System CountersFILE: Number of bytes read=1252FILE: Number of bytes written=791325FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=689HDFS: Number of bytes written=297HDFS: Number of read operations=12HDFS: Number of large read operations=0HDFS: Number of write operations=2Job Counters Killed map tasks=1Launched map tasks=4Launched reduce tasks=1Data-local map tasks=4Total time spent by all maps in occupied slots (ms)=53828Total time spent by all reduces in occupied slots (ms)=13635Total time spent by all map tasks (ms)=53828Total time spent by all reduce tasks (ms)=13635Total vcore-milliseconds taken by all map tasks=53828Total vcore-milliseconds taken by all reduce tasks=13635Total megabyte-milliseconds taken by all map tasks=55119872Total megabyte-milliseconds taken by all reduce tasks=13962240Map-Reduce FrameworkMap input records=14Map output records=70Map output bytes=1106Map output materialized bytes=1264Input split bytes=345Combine input records=0Combine output records=0Reduce input groups=21Reduce shuffle bytes=1264Reduce input records=70Reduce output records=21Spilled Records=140Shuffled Maps =3Failed Shuffles=0Merged Map outputs=3GC time elapsed (ms)=1589CPU time spent (ms)=5600Physical memory (bytes) snapshot=749715456Virtual memory (bytes) snapshot=3382075392Total committed heap usage (bytes)=380334080Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format Counters Bytes Read=344File Output Format Counters Bytes Written=297
[hadoop@centos-aaron-h1 ~]$ [hadoop@centos-aaron-h1 ~]$ hadoop jar IndexStepTwo.jar com.empire.hadoop.mr.inverindex.IndexStepTwo /index/indexsteponeoutput /index/indexsteptwooutput
18/12/19 07:11:27 INFO client.RMProxy: Connecting to ResourceManager at centos-aaron-h1/192.168.29.144:8032
18/12/19 07:11:27 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/12/19 07:11:27 INFO input.FileInputFormat: Total input files to process : 1
18/12/19 07:11:28 INFO mapreduce.JobSubmitter: number of splits:1
18/12/19 07:11:28 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
18/12/19 07:11:28 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1545173547743_0002
18/12/19 07:11:28 INFO impl.YarnClientImpl: Submitted application application_1545173547743_0002
18/12/19 07:11:29 INFO mapreduce.Job: The url to track the job: http://centos-aaron-h1:8088/proxy/application_1545173547743_0002/
18/12/19 07:11:29 INFO mapreduce.Job: Running job: job_1545173547743_0002
18/12/19 07:11:36 INFO mapreduce.Job: Job job_1545173547743_0002 running in uber mode : false
18/12/19 07:11:36 INFO mapreduce.Job: map 0% reduce 0%
18/12/19 07:11:42 INFO mapreduce.Job: map 100% reduce 0%
18/12/19 07:11:48 INFO mapreduce.Job: map 100% reduce 100%
18/12/19 07:11:48 INFO mapreduce.Job: Job job_1545173547743_0002 completed successfully
18/12/19 07:11:48 INFO mapreduce.Job: Counters: 49File System CountersFILE: Number of bytes read=324FILE: Number of bytes written=394987FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=427HDFS: Number of bytes written=253HDFS: Number of read operations=6HDFS: Number of large read operations=0HDFS: Number of write operations=2Job Counters Launched map tasks=1Launched reduce tasks=1Data-local map tasks=1Total time spent by all maps in occupied slots (ms)=3234Total time spent by all reduces in occupied slots (ms)=3557Total time spent by all map tasks (ms)=3234Total time spent by all reduce tasks (ms)=3557Total vcore-milliseconds taken by all map tasks=3234Total vcore-milliseconds taken by all reduce tasks=3557Total megabyte-milliseconds taken by all map tasks=3311616Total megabyte-milliseconds taken by all reduce tasks=3642368Map-Reduce FrameworkMap input records=21Map output records=21Map output bytes=276Map output materialized bytes=324Input split bytes=130Combine input records=0Combine output records=0Reduce input groups=7Reduce shuffle bytes=324Reduce input records=21Reduce output records=7Spilled Records=42Shuffled Maps =1Failed Shuffles=0Merged Map outputs=1GC time elapsed (ms)=210CPU time spent (ms)=990Physical memory (bytes) snapshot=339693568Virtual memory (bytes) snapshot=1694265344Total committed heap usage (bytes)=137760768Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format Counters Bytes Read=297File Output Format Counters Bytes Written=253
[hadoop@centos-aaron-h1 ~]$ 五、运行结果
[hadoop@centos-aaron-h1 ~]$ hdfs dfs -cat /index/indexsteponeoutput/part-r-00000
boby--a.txt 1
boby--b.txt 2
boby--c.txt 4
fork--a.txt 2
fork--b.txt 4
fork--c.txt 8
hello--a.txt 2
hello--b.txt 4
hello--c.txt 8
integer--a.txt 1
integer--b.txt 2
integer--c.txt 4
source--a.txt 1
source--b.txt 2
source--c.txt 4
tom--a.txt 1
tom--b.txt 2
tom--c.txt 4
[hadoop@centos-aaron-h1 ~]$ [hadoop@centos-aaron-h1 ~]$ hdfs dfs -cat /index/indexsteptwooutput/part-r-00000
boby a.txt-->1 b.txt-->2 c.txt-->4
fork a.txt-->2 b.txt-->4 c.txt-->8
hello b.txt-->4 c.txt-->8 a.txt-->2
integer a.txt-->1 b.txt-->2 c.txt-->4
source a.txt-->1 b.txt-->2 c.txt-->4
tom a.txt-->1 b.txt-->2 c.txt-->4
[hadoop@centos-aaron-h1 ~]$ 最后寄语,以上是博主本次文章的全部内容,如果大家觉得博主的文章还不错,请点赞;如果您对博主其它服务器大数据技术或者博主本人感兴趣,请关注博主博客,并且欢迎随时跟博主沟通交流。





