本文主要是介绍[读书笔记]《大数据之路》——阿里数据整合及管理体系——OneData模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
阿里数据整合及管理体系——OneData模型
摘要#
阿里的《大数据之路》第9章介绍了其内部进行数据整合及管理的方法体系和工具OneData。他们在这一体系下,构建统 、规范、可共的全域数据体系,避免数据的冗余和重复建设,规避数据烟囱和不一致性,了解他们的建模理论,有助于扩宽我们对数据建模的视野和思考。
1. 概述#
阿里巴巴集团大数据建设方法论的核心 :从业务架构设计到模型设计,从数据研发到数据服务,做到数据可管理 、可追溯、可规避重复建设。
1.1 定位及价值#
定位:建设统一的、规范化的数据接人层( ODS )和数据中间层( DWD 和
DWS ),通过数据服务和数据产品,完成服务于阿里巴巴的大数据系统建设 ,即数据公共层建设。
价值:提供标准化的( Standard )、共享的( Shared )、数据服务( Service )能力,降低数据互通成本,释放计算、存储、人力等资源,以消除业务和技术之痛。
2. 体系架构#
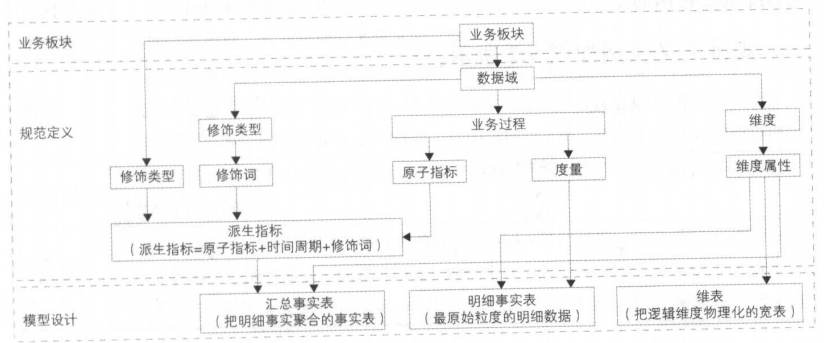
图1.2.1 体系架构图
2. 规范定义#
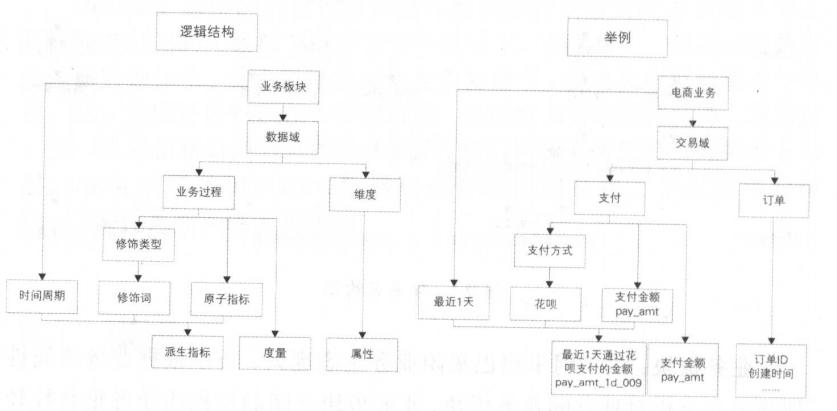
图2.1.1 规范定义实例
3. 模型设计#
3.1 指导理论#
维度建模理论:基于维度数据模型总线架构,构建一致性的维度
和事实。
3.2 模型层次#
(1) 操作数据层(ODS)
功能:同步;结构化;累积历史、清洗
(2) 公共维度模型层(DM):明细数据层(DWD)+汇总数据层(DWS)
功能:组合相关和相似数据;公共指标统一加工;建立一致性维度
(3) 应用数据层( DS )
功能:个性化指标加工;基于应用的数据组装
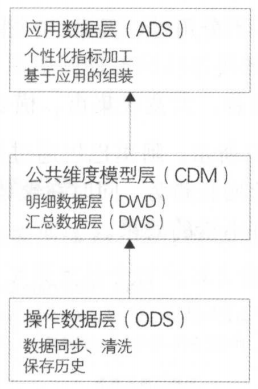
图3.2.1 模型层次关系图
3.3 基本原则#
(1) 高内聚和低辑合
(2) 核心模型与扩展模型分离
(3) 公共处理逻辑下沉及单一
(4) 成本与性能平衡
(5) 数据可回滚
(6) 一致性
(7) 命名清晰、可理解
4. 模型实施#
需求分析>架构设计>详细模型设计
4.1 业界常用的模型实施过程#
- Kimball 模型实施过程
(1) 高层模型
(2) 详细模型
(3) 模型审查、再设计和验证
(4) 提交 ETL 设计和开发
参考:Ralph Kimball, The DataWarehouse Lifecycle Toolkit
- Inmon 模型实施过程
三个层次:
ERD (Entity Relationship Diagram ,实体关系图)层
DIS (Data Item Set 数据项集)层
物理层(Physical Model ,物理模型)
参考:Inmon, Building the Data Warehouse
- 其他模型实施过程
· 业务建模,生成业务模型
· 领域建模,生成领域模型
· 逻辑建模,生成逻辑模型
· 物理建模,生成物理模型
4.2 OneData 实施过程#
- 指导方针
首先,在建设大数据数据仓库时,要进行充分的业务调研和需求分析。
其次,进行数据总体架构设计,主要根据数据域对数据进行划分;按照维度建模理论,构建总线矩阵、抽出业务过程和维度。
再次,对报表需求进行抽象整理出相关指标体系,使用 OneData 工具完成指标规范定义和模型设计。
最后,就是代码研发和运维。
- 实施工作流
(1) 数据调研
· 业务调研
· 需求调研
https://github.com/tygq5nux/jkgibzxucg/discussions/1916
https://github.com/djvb5gwz/kdnyzskenz/discussions/1932
https://github.com/tygq5nux/jkgibzxucg/discussions/1917
https://github.com/djvb5gwz/kdnyzskenz/discussions/1933
https://github.com/tygq5nux/jkgibzxucg/discussions/1918
https://github.com/djvb5gwz/kdnyzskenz/discussions/1934
https://github.com/tygq5nux/jkgibzxucg/discussions/1919
https://github.com/djvb5gwz/kdnyzskenz/discussions/1935
https://github.com/tygq5nux/jkgibzxucg/discussions/1920
https://github.com/djvb5gwz/kdnyzskenz/discussions/1936
https://github.com/tygq5nux/jkgibzxucg/discussions/1921
https://github.com/djvb5gwz/kdnyzskenz/discussions/1937
https://github.com/tygq5nux/jkgibzxucg/discussions/1922
https://github.com/djvb5gwz/kdnyzskenz/discussions/1938
https://github.com/tygq5nux/jkgibzxucg/discussions/1923
https://github.com/djvb5gwz/kdnyzskenz/discussions/1939
https://github.com/tygq5nux/jkgibzxucg/discussions/1924
https://github.com/djvb5gwz/kdnyzskenz/discussions/1940
https://github.com/tygq5nux/jkgibzxucg/discussions/1925
https://github.com/djvb5gwz/kdnyzskenz/discussions/1941
https://github.com/tygq5nux/jkgibzxucg/discussions/1926
https://github.com/tygq5nux/jkgibzxucg/discussions/1927
https://github.com/tygq5nux/jkgibzxucg/discussions/1928
https://github.com/tygq5nux/jkgibzxucg/discussions/1929
https://github.com/tygq5nux/jkgibzxucg/discussions/1930
https://github.com/tygq5nux/jkgibzxucg/discussions/1931
https://github.com/tygq5nux/jkgibzxucg/discussions/1932
https://github.com/tygq5nux/jkgibzxucg/discussions/1933
https://github.com/tygq5nux/jkgibzxucg/discussions/1934
https://github.com/tygq5nux/jkgibzxucg/discussions/1935
https://github.com/tygq5nux/jkgibzxucg/discussions/1936
https://github.com/tygq5nux/jkgibzxucg/discussions/1937
https://github.com/tygq5nux/jkgibzxucg/discussions/1938
https://github.com/tygq5nux/jkgibzxucg/discussions/1939
https://github.com/tygq5nux/jkgibzxucg/discussions/1940
https://github.com/tygq5nux/jkgibzxucg/discussions/1941
https://github.com/tygq5nux/jkgibzxucg/discussions/1942
https://github.com/tygq5nux/jkgibzxucg/discussions/1943
https://github.com/tygq5nux/jkgibzxucg/discussions/1944
https://github.com/tygq5nux/jkgibzxucg/discussions/1945
https://github.com/tygq5nux/jkgibzxucg/discussions/1946
https://github.com/tygq5nux/jkgibzxucg/discussions/1947
https://github.com/tygq5nux/jkgibzxucg/discussions/1948
https://github.com/bolo3m2k/rdhslbggtt/discussions/524
https://github.com/zjd6qwwu/xiellftjwv/discussions/507
https://github.com/zjd6qwwu/xiellftjwv/discussions/508
https://github.com/bolo3m2k/rdhslbggtt/discussions/525
https://github.com/bolo3m2k/rdhslbggtt/discussions/526
https://github.com/zjd6qwwu/xiellftjwv/discussions/509
https://github.com/bolo3m2k/rdhslbggtt/discussions/527
https://github.com/zjd6qwwu/xiellftjwv/discussions/510
https://github.com/bolo3m2k/rdhslbggtt/discussions/528
https://github.com/bolo3m2k/rdhslbggtt/discussions/529
https://github.com/zjd6qwwu/xiellftjwv/discussions/511
https://github.com/bolo3m2k/rdhslbggtt/discussions/530
https://github.com/bolo3m2k/rdhslbggtt/discussions/531
https://github.com/bolo3m2k/rdhslbggtt/discussions/532
https://github.com/bolo3m2k/rdhslbggtt/discussions/533
https://github.com/bolo3m2k/rdhslbggtt/discussions/534
https://github.com/bolo3m2k/rdhslbggtt/discussions/535
https://github.com/bolo3m2k/rdhslbggtt/discussions/536
https://github.com/zjd6qwwu/xiellftjwv/discussions/513
https://github.com/zjd6qwwu/xiellftjwv/discussions/514
httÿ
这篇关于[读书笔记]《大数据之路》——阿里数据整合及管理体系——OneData模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




