本文主要是介绍基于网络数据的净水器销量影响因素分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是数据分析呢?数据分析就是利用适当的统计方法对收集来的数据进行分析,将数据汇总,充分发挥数据的作用。接下来聊聊数据分析的大致流程:
1.明确分析的目的,把数据的潜在价值挖掘出来,看看数据本身的规律
2.数据的采集与清洗(无非是线上线下、数据库之类的,数据清洗也许会是个大工程可能需要将不规整的数据弄得规整)
3.描述统计(以图形或表格的方式直观呈现出来,我经常用到图形可能是直方图、图形图、箱线图、散点图等。)
4.进行数据分析及建模
5.报告的撰写(一份好的数据分析报告,首先需要有一个好的分析框架,并且图文并茂,层次明晰,能够让阅读者一目了然。结构清晰、主次分明可以使阅读者正确理解报告内容;图文并茂,可以令数据更加生动活泼,提高视觉冲击力,有助于阅读者更形象、直观地看清楚问题和结论,从而产生思考。好的数据分析报告需要有明确的结论、建议或解决方案。)
这一切的前提是对行业的了解,数据与业务的结合,根据业务的需要制定发展计划,归类出需要整理的数据。
《基于网络数据的净水器销量影响因素分析》
主要针对自己的论文进行数据分析的了解,以统计学、数据挖掘理论知识为基础,借助R语言软件,通过网络爬虫获取净水器的相关数据。研究净水器销量影响因素以及影响程度,借助回归模型进行分析, 由于分析的被解释变量为数值型变量,解释变量为分类型变量及数值型变量,故建立多元线性回归模型进行分析
当时的主要研究框架如下:
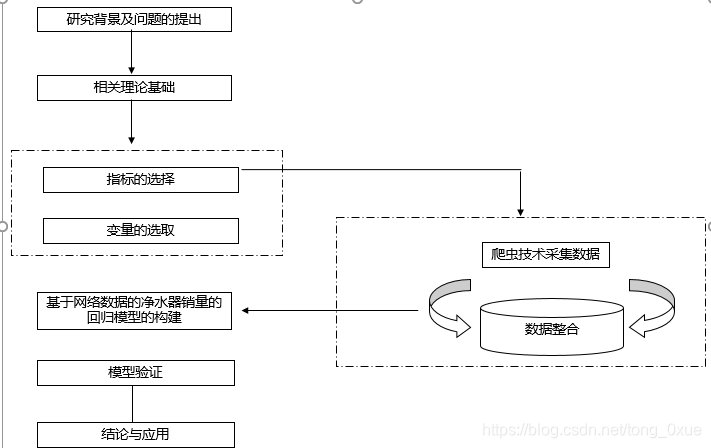
指标的选择:

描述统计
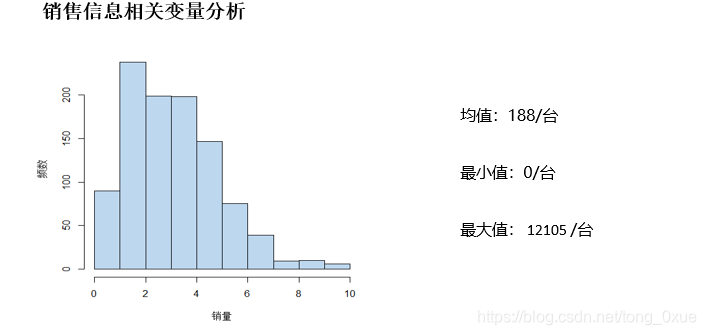
Ø净水器的销量作对数直方图,可以看出净水器销量是呈现右偏分布的。
Ø销量最高的是海尔品牌的非直饮净水器,保修期为1年,智能类型为阿里小智,其原价为699/元,促销价为168/元,价格波动幅度较大。
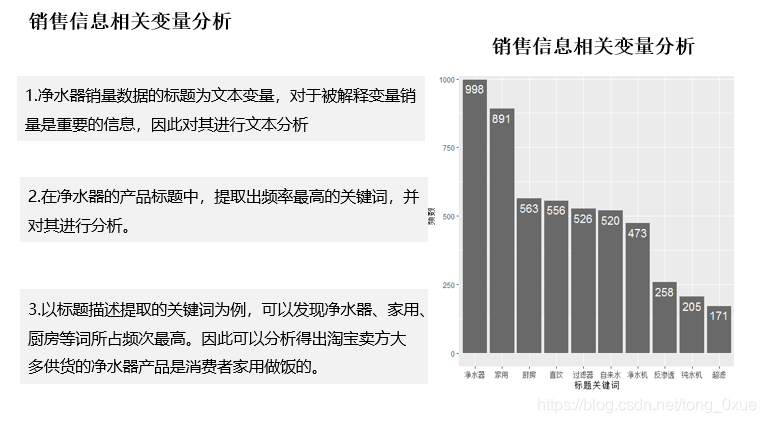


回归模型的构建
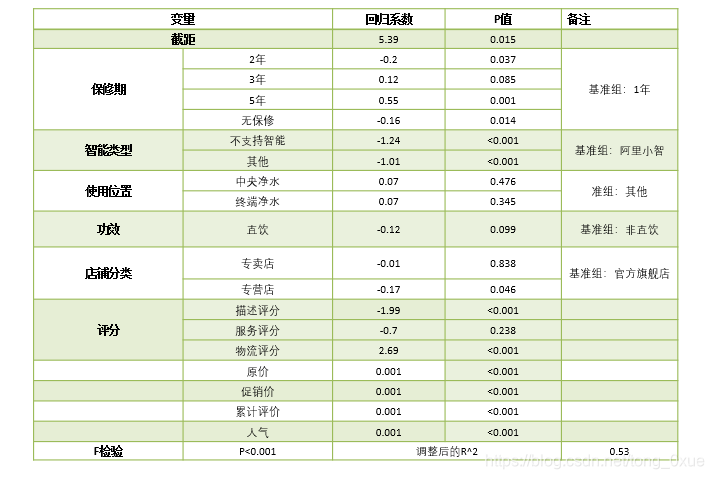
模型解读
Ø注:针对取对数后的净水器销量分析说明:统一对数线性模型的系数估计解读为“增长率”,在控制其它因素不变的情况下:
Ø保修期:保修期为5年的净水器销量最高,比保修期为1年的销量高55%;
Ø智能类型:阿里小智的净水器销量最高,其次为其他,不支持智能类型的净水器销量最低;
Ø功效:非直饮的净水器销量最高,功效为非直饮的净水器销量比直饮高12%;
Ø店铺分类:官方旗舰店的净水器销量最高,店铺分类为官方旗舰店的净水器销量比专营店的销量高17%;
Ø物流评分的增加会带来净水器销量的增加;
Ø原价的降低会带来净水器销量的增加;
Ø人气值的增加可能会带来净水器销量的增加。
Ø对因变量销量取对数后,建立对数线性模型 ,模型的F检验拒绝原假设,说明建立的模型显著。调整后的可决系数为0.53,模型的拟合程度尚可接受。
模型检验与修正
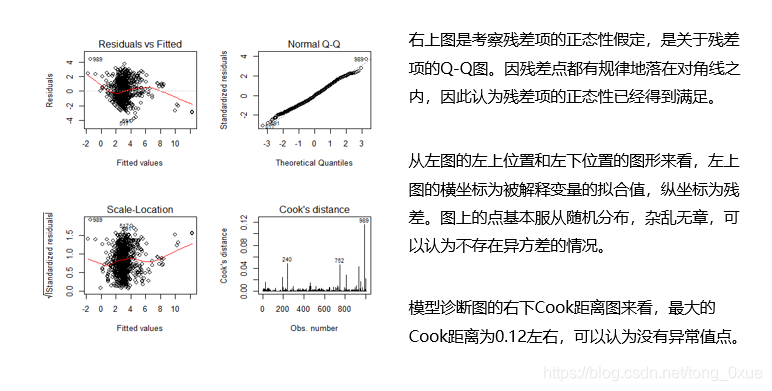
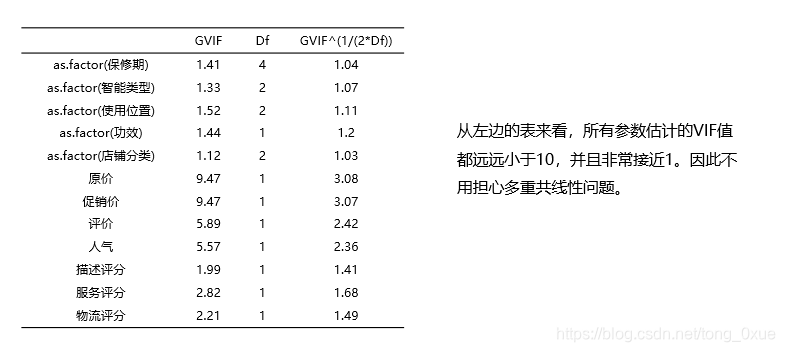
结论
通过对网络数据进行描述统计分析和模型分析,得出净水器销量影响因素如下所示:
(1)净水器的使用位置影响销量,即净水器用在终端净水的位置还是水运输过程中的净水,或者是水源头净水的位置,都将影响消费者对净水器的需求。
(2)店铺分类对净水器的销量有影响,专卖店和官方旗舰店的口碑,影响净水器的销量。
(3)净水器的智能类型影响净水器的销量,净水器的质量效果越好,其销量将会受到影响。
(4)净水器的功效决定净水器的用途,其功效也影响净水器的销量。功效为非直饮功效的销量比较高,而大多数消费者还是比较亲睐于非直饮的净水器。
(5)净水器的网络店铺评分影响净水器的销量。对店铺评分越高,被顾客关注度越高,净水器销售的成交量越高。
(6)保修期时间长的净水器销量较高,保修时间长使得顾客安全感提升且省去了很多维修费用。
(7)净水器价格低且打折力度大也会使得净水器的销量提高。
(8)当人气值和累计评价较高时,增加了消费者的购物信心其产品的销量也就会有所提高。
建议

创新点与不足

这篇关于基于网络数据的净水器销量影响因素分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






