本文主要是介绍大数据导论考察论文:模拟建立测控全国COVID-19流行趋势的模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大数据导论考察论文
- 一.背景分析
- 二.数据采集
- 三.数据分析
- 3.1理想中的挖掘分析
- 3.2模拟数据建模分析
- 四.数据可视化
- 五.可行性分析
- 5.1误差分析
- 5.2模型优点
- 5.3模型缺点
- 六.参考文献
话说,大一的文笔好稚嫩啊哈哈哈哈
数学建模部分为校赛作品,和tqs、ly学长共同完成,这是我第一次建模经历,感谢和学长们这一段建模过程,学到了好多
一.背景分析
新型冠状病毒肺炎(简称:COVID-2019)正在全世界范围内传播与扩散,它的爆发和蔓延给我国乃至全球的人民生活和经济发展带来了很大影响。
国家卫生健康委决定将新型冠状病毒感染的肺炎纳入法定传染病乙类管理,采取甲类传染病的预防、控制措施。在这次疫情中,大数据对于政府管理的科学高效和规划预测具有指导和预见作用,协助政府统筹调控。其中,主要表现在以下几个方面:
(1)利用大数据搭建信息管理公共服务平台,有力解决受疫情的民生问题。例如医院的预约挂号平台,排查密切接触患者等;
(2)其他社会资源的整体规划和分配。例如地理大数据平台的疫情实时地图,医疗资源的优化:做好预防措施和医疗资源的储蓄和分配等;
(3)统筹数字化资本,为行业进行针对性分析和调控。例如货币政策:央行降低金融机构负债成本(银行间流动性、政策性利率、专项再贷款等),金融机构对实体企业扩大支持(LPR利率、信贷规模、增信和信用救助、定向利率优惠)。
由于技术等客观因素限制,我就疫情中政府基于大数据应用,第二个方面中,通过分析卫生部门所采取措施对疫情传播所造成的影响,复盘我国抗击COVID-2019取得阶段性胜利的原因。为此,我将初步筛选全国疫情发展态势统计结果,模拟建立测控全国COVID-19流行趋势的模型。
二.数据采集
由于疫情影响较大,因而数据来源非常多,如信息管理系统、网络信息系统、物联网李彤、科学实验系统等。其中,大部分所需数据为网页数据,不但非结构化数据多,而且数据的实时性强。这里,我们可以通过“网页爬虫”的程序来实现网络数据采集。通过网络爬虫程序,我们从SiteURL中抽取目标链接写入URL队列中,并从中读取链接以获得该网页信息。从网页内容中抽取所需属性的内容值,写入数据库的Content中。考虑到疫情中的大数据数据量大,价值密度低的特点,我认为选择宽度优先的遍历策略更为合适。
准确、高质量的数据是大数据产生价值的必要条件。在数据流程处理流程方面,本文数据选用官方权威机构发布的数据,在中后期疫情得到重视并透明化后,数据错误、数据缺失等质量问题较少。同时,考虑到疫情数据更新快的时效性特点,针对本问题,数据应该及时采取每日数据并选用每日同一时间的数据,保证数据的可信性。
权衡数据来源的权威性、数据的规范性、数据的产生时间等衡量标准,本文数据来源为国家卫生健康委员会官方网站(http://www.nhc.gov.cn/),在预处理整理后,得:
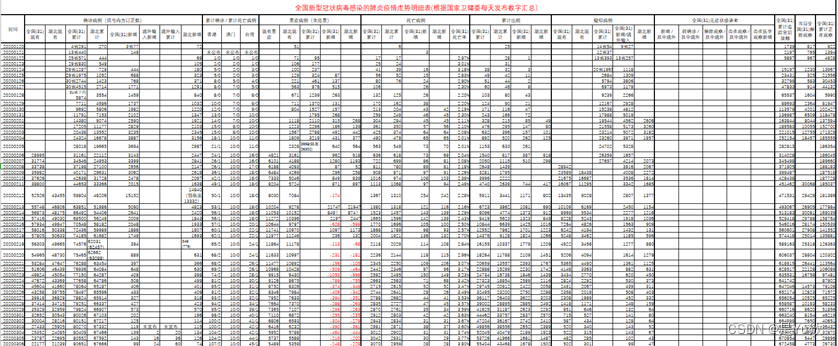
……
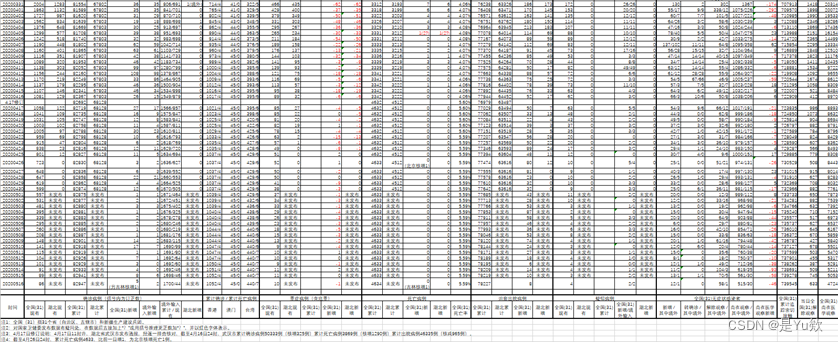
(注:此表为引用2020数学建模校赛附件《全国疫情发展事态统计》)
三.数据分析
3.1理想中的挖掘分析
世界卫生组织健康突发事件和风险评估部主任奥利弗·摩根提出:量化数据工具和机器学习可以提高疫情爆发时期的决策质量。根据他的研究,我认为疫情的爆发可分成三个阶段。在疫情爆发的不同阶段混合使用数据量化工具,可以有效提高决策质量,评估决策效果。
(1)调查阶段。特征是不确定性强,病例数少。作为计算机编程的R语言,适合统计计算和制图。 R有方法处理缺失值和异常值,在疫情初期可以有效地整合信息。
(2)疫情扩大阶段。需要检测新的公共卫生事件的警报,从而控制疫情扩散。使用开源的传染病智能(EIOS)平台,用于数据的处理、分类和组合。机器学习较好的能处理数据丢失的情况,并对疫情传播趋势做出预测。
(3)控制干预阶段。特点是强监控,以及不断优化对疫情的干预措施。通过建模优化干预措施。当疫情爆发的规模和演变存在不确定性时,通过提高对爆发的量化估计的准确性和及时性,提供物资和医疗服务可以优化对于疫情爆发的应对。
3.2模拟数据建模分析
由于技术等客观因素限制,这里通过筛选全国疫情发展态势统计结果,采用了微分建模中传染病模型SEIR模型,并在此基础上增加对自愈的考虑。这个模型用较为合适的解构将数据组织起来,减少数据重复并提供更好的数据共享。数据之间约束条件的使用保证数据之间依赖关系,防止出现不准确、不完整和不一致性的质量问题。
这里把中国在这次新冠疫情中的人群分为五类:S类,E类,I类,W类,R类。在总人口固定为N时,设第t天时五类人群的人数分别为S(t)、E(t)、I(t)、W(t)、R(t)。考虑自愈因素。
S 类,易感者 (Susceptible),指未得病者,但缺乏免疫能力,与感染者接触后容易受到感染;
E 类,暴露者 (Exposed),指接触过感染者,但暂无能力传染给其他人的人,对潜伏期长的传染病适用;
I 类,感病者 (Infectious),指染上传染病的人,可以传播给 S 类成员,将其变为 E 类或 I 类成员;
W类,未隔离者,指无法追踪到的和传染源有直接接触的人。对于优化后的模型来说,病人和可控者皆被完全隔离,使病毒的进一步传播中断。所以,此时的不可控的人中带病毒者将成为社会上的流动病毒;
R 类,康复者 (Recovered),指被隔离或因病愈而具有免疫力的人。如免疫期有限,R 类成员可以重新变为 S 类。
后面公式太多了,直接贴图
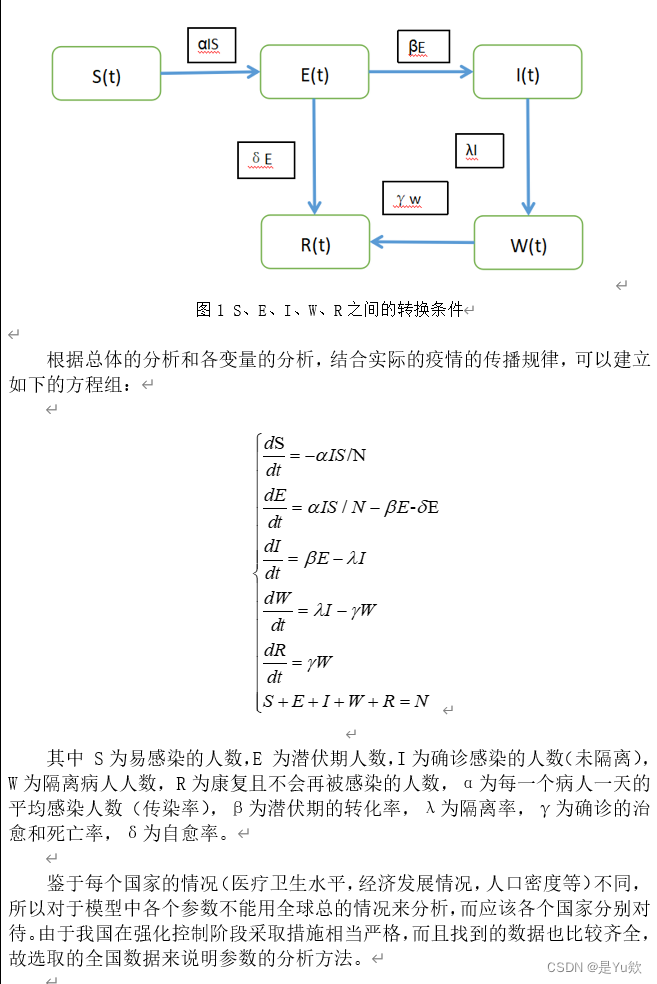
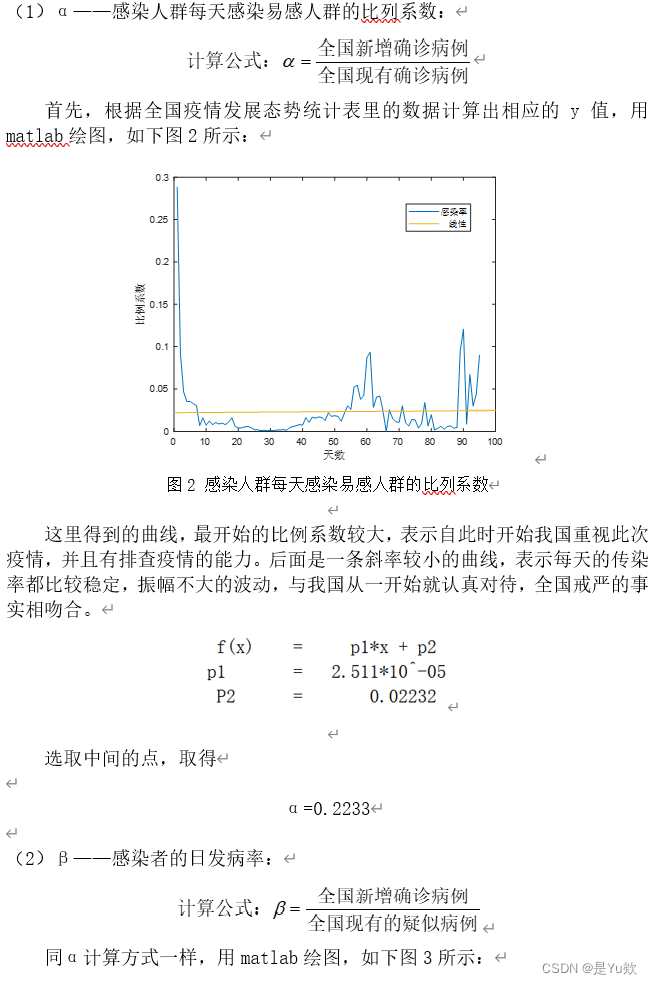
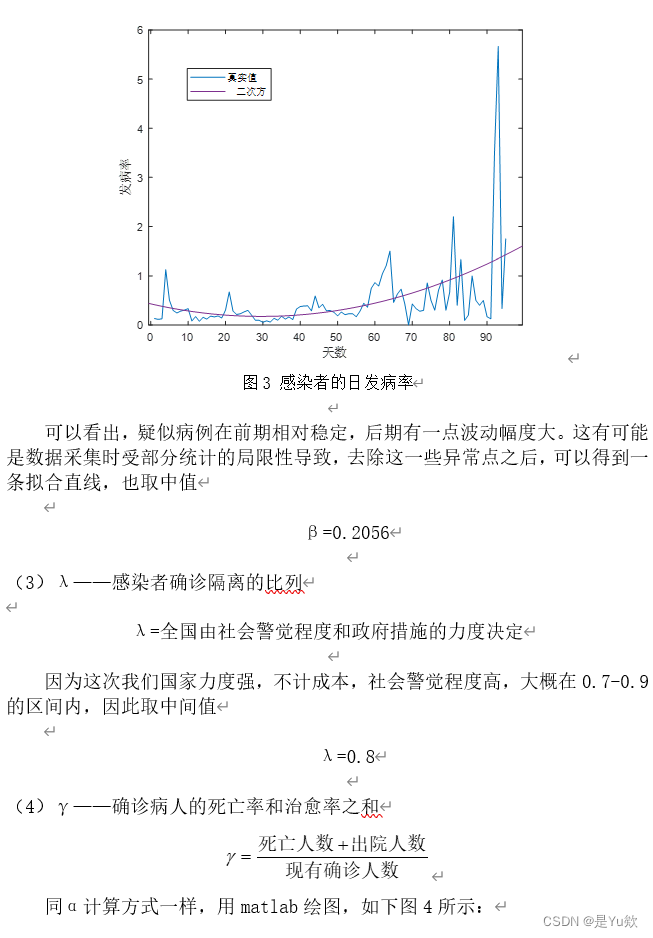
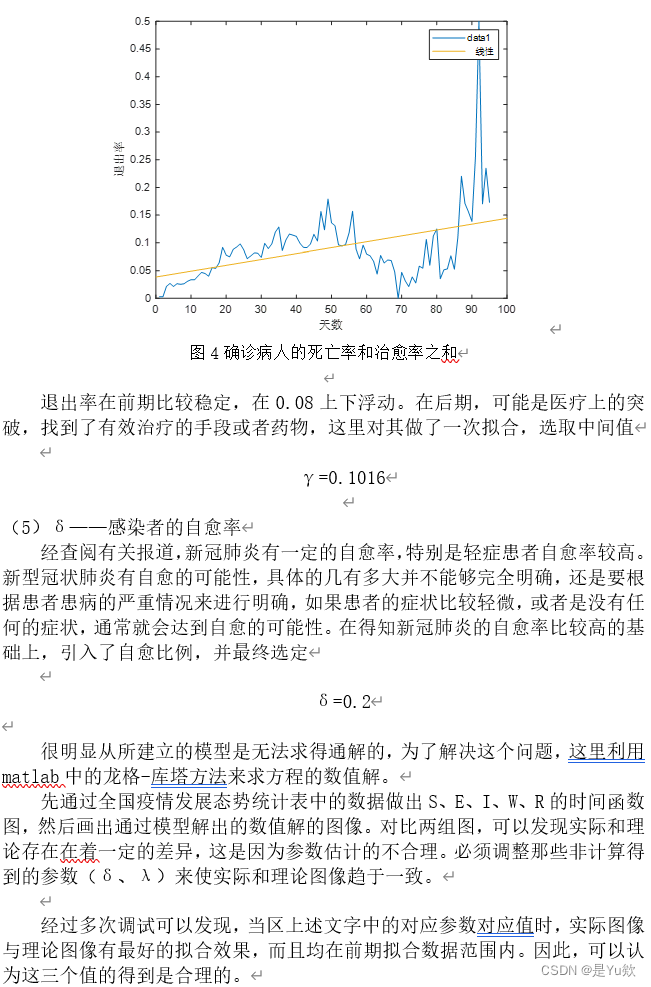
四.数据可视化
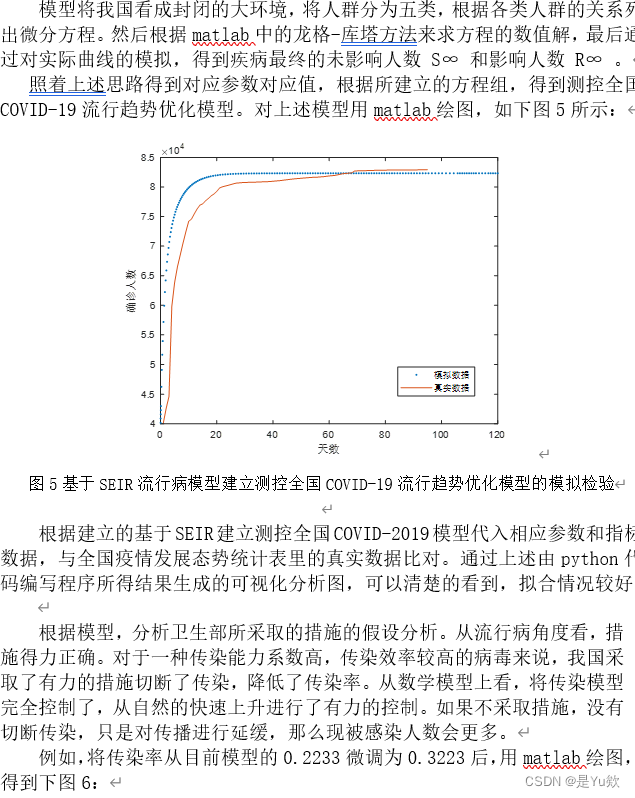
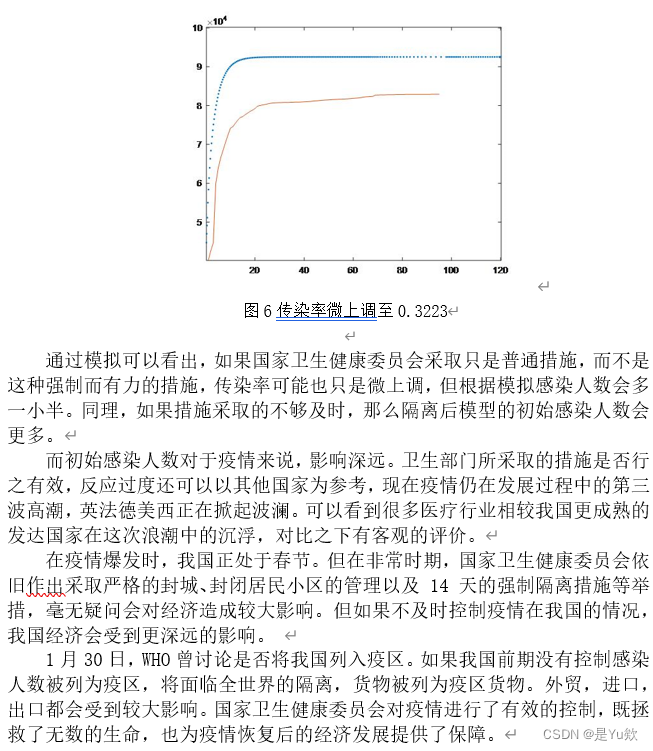
五.可行性分析
5.1误差分析
a.新冠肺炎的潜伏期是在2天~14天之间(甚至有极少数患者会出现24天潜伏期),初期症状和一般病毒感染引起的感冒有相似,以及疫情初期检测能力有限,导致有关部门调查统计的数据有能不太准确,有一定的“延迟”;
b.不可控的的疑似病例数据缺乏;
c.传染病模型采用了了几个关键的数据,进行概全的目的,对于总的若干因变量会带来间歇性误差;
d.医疗水平提高,对于疫情治愈能力提高。
5.2模型优点
a.本模型在经典的传染病模型SIR上加入了潜伏期的考虑和自愈情况的分析,在比较封闭的地区,本模型可以大致模拟出疫情的大致走向,只要参数准确,就可以得出与真实数据相差无几的曲线。在大体上本模型模拟了这次疫情的一个人群结构分布;
b.在因变量的筛选时注重几个方面的选择,这样能过具有普遍性和依据性,在最后推理的时候有多方面的结合和深入,并且比较尝试不同取值,对应参数科学,而且拟合性好。
5.3模型缺点
a.本模型是将一个地区作为一个整体,但是没有考虑人口分散和人口聚集的影响,也没有分析人口流动和无症状感染;
b.因为人的反馈很强,无法做到对于人们警戒的变化而变化对于一些情况特殊的地区模拟起来难度大,对于参数的估计难以准确;
c.有些参数难以得到数据。或者数据不够准确。无法估计长时间的疫情情况。
六.参考文献
[1] 王议锋,田 一,杨 倩. 非典数学模型的建立与分析[J].工程数学学报, 2003(:20.7).
[2] 李 贝,徐海臻,郭佳佳. 考虑自愈的SARS的传播模型[J].工程数学学报, 2003(:20.7).
[3] 周丹文 .MATLAB中基于GARCH模型[D].南京审计大学,2019.
这篇关于大数据导论考察论文:模拟建立测控全国COVID-19流行趋势的模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





