本文主要是介绍HNSW算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
From:
- HNSW算法(nsmlib/hnswlib)-CSDN博客
- HNSW算法的基本原理及使用 - 知乎
HNSW是一种广泛使用的ANN图索引结构,包括DiskANN、DF-GAS、SmartSSD等。本文档主要总结HNSW的结构与工作流程,便于后期研究其工作流程在迁移到CSD中存在的I/O问题
数据结构
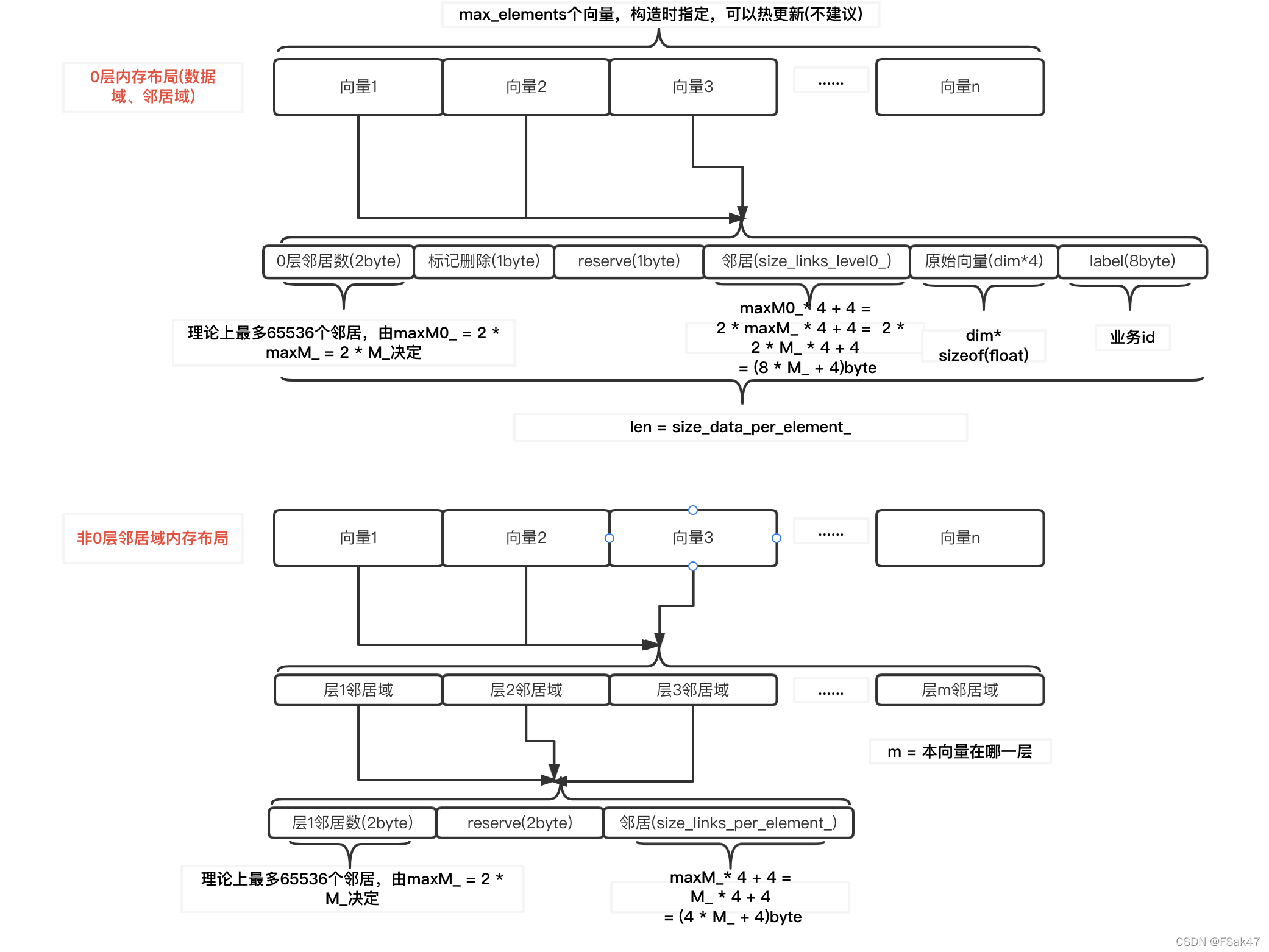
- HNSW在内存中的结构如下图所示。
- 最下层是0层,越往上层数越大。除了0层外,上层的内存布局结构都相同。
- 大概来说就是每层中的每个向量都会保存他的邻居数和邻居,不过0层会额外保存原始向量,非0层会额外保存其所在层到1层的所有邻居
- (不过我不理解的地方是为什么上层的每个向量都要保存自顶向下的每一层的邻居域,不会造成重复存储嘛?只需要该节点在下一层的邻居域不就好了?或者说每个节点在内存中其实值保存了一份,每层之间是共享的?需要进一步调研)。

详细说明:
- 首先厘清变量含义:
maxM_:非0层最大的最大邻居数
maxM0_:0层最大邻居数,=2*maxM_
2. 对于0层索引:
- header(4 byte):header前2字节指定该向量在0层当前有几个邻居,后面一字节是标记删除位(增量构建用到),为内存对齐header第四字节废弃;
- 邻居域:构造时就申请好了内存,每个0层向量可以有maxM0_个邻居向量(是非0层的2倍),占用字节数 = maxM0_ * 4 + 4字节(这个+4没解释是什么)
- 数据域:占用字节数 = dim * sizeof(float) = dim * 4字节,以及label,对于我们就是向量id(如feed_id、video_id),占用8字节,共计dim*4+8字节
0层全部数据保存在data_level0_memory_,构造索引时通过参数max_elements指定索引最大向量个数,data_level0_memory_一次性申请max_elements * size_data_per_element_字节的内存。
3. 对于非0层索引:
- 非0层主要存储每个向量在各个层的邻居表。具体是保存了每个向量丛它所在层向低层的邻居。如向量a构建时落在第3层,那么构建过程会不断更新它在1、2、3层的邻居向量。
- linkLists_是邻居表存储实体,是一个二维数组,行由max_elements即最大向量个数指定,列由该向量实际落在的层数,在构建该向量时具体分配内存。(但是每个向量落到的层不一样,如果做成一个二维数组怎么根据每个向量实际层数灵活分配内存?做成链表?而且linkLists_是每层都有一个还是整个索引共享一个也不清楚)
个人理解(From SmartSSD中的介绍):
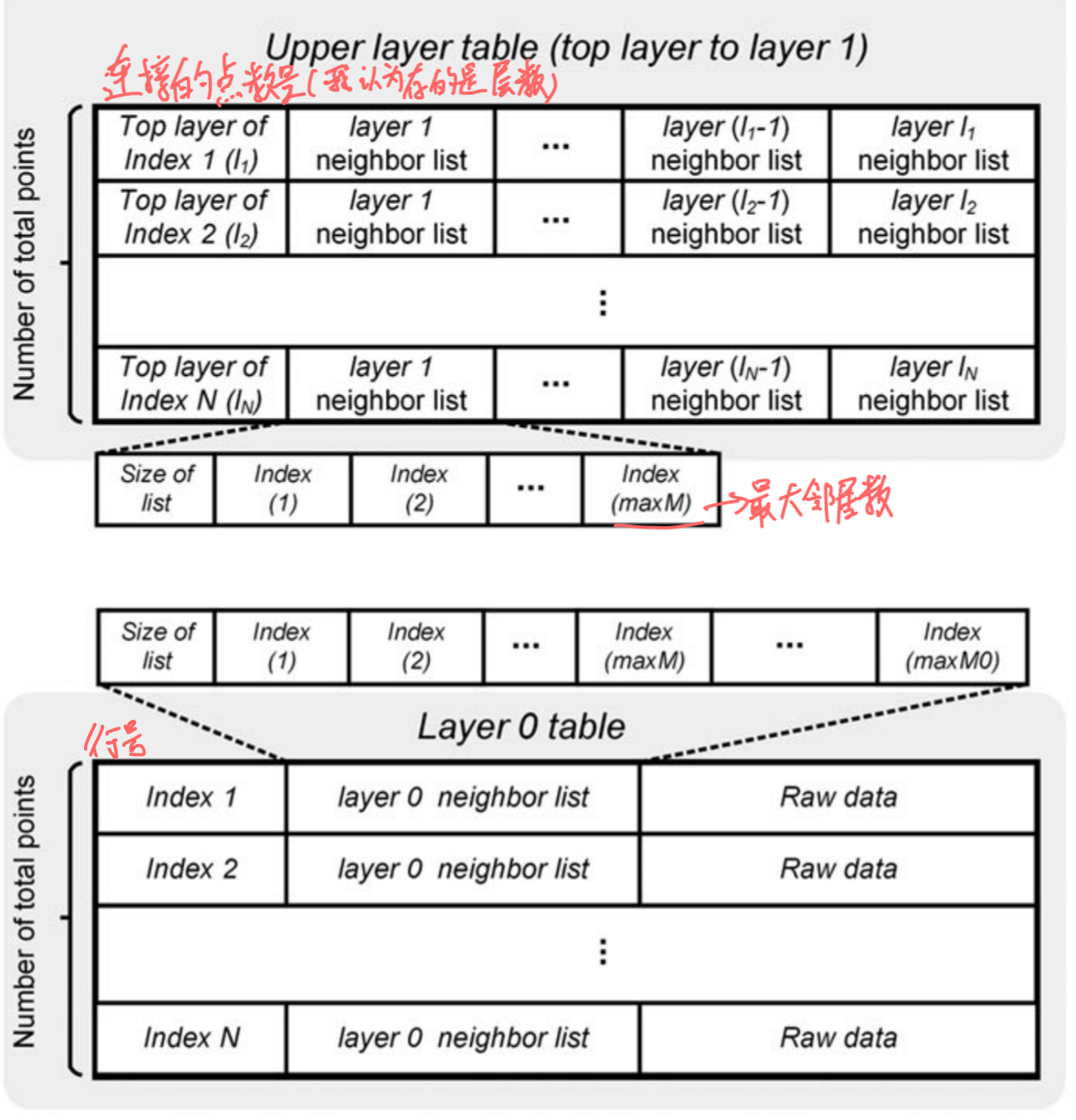
整个HNSW只包含两个表,一个表是存层0的,另一个表是1-N层的(上层的连接信息都存在表)。如图所示。
先说层0表,他有M行,M是总节点数。然后后续操作和数据结构都用这个表里的行数表示这个节点的索引。层0表主要目的是保存一个节点的邻居以及原始向量。邻居数量固定,因此层0表的空间是一开始就预分配好的。层0的邻居数是上层表邻居数的2倍(猜测是提高连通性保证召回率)。
然后是上层表,这个表主要是保存上层的节点间的连通信息。这个表的行数也和层0表相同,每行保存的是每个节点在上面每层的邻居。但是不是每个点都会贯穿所有层,所以需要保存这个点到底最高到几层,也就是每一行开头的第一个元素(这个数据布局和前面的那个图有点不一样,前面那个图没有每行开头的层数信息,不过大的数据结构是一样的)。按照论文的说法,由于不是每个节点都要贯穿每个层,没有延伸到的层就不需要分配空间可以节约内存。
这篇关于HNSW算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








