本文主要是介绍爬虫实战小案例—获取喜马拉雅账号的关注数据和粉丝数据生成电子表格并实现批量关注或者取关然后生成表格文件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
爬虫案例—获取喜马拉雅账号的关注数据和粉丝数据生成电子表格并实现批量关注或者取关然后生成表格文件
有好多人平时应该很喜欢听喜马拉雅的广播,也有自己的账号。我本人平时很少听喜马拉雅广播,前几天一个朋友问我能不能帮他获取喜马拉雅账号的已关注的数据和粉丝的数据, 然后再查找有哪些自己已关注的但没有关注自己(也就是不是自己的粉丝)的,还有自己没关注的粉丝数据。接下来这个朋友又提出能不能帮助实现批量取关和关注数据,然后再生成一个关注和取关的数据表格文件。
大家听起来估计也有点绕了,我也是有这个同感。话不多说了,我接到他这个请求之后,第一时间想到用爬虫来实现这个功能。喜马拉雅的登录页面如下:
登录之后进入 个人主页,点击账号头像然后再点击个人页。如下图所示:

然后进入到个人主页,按下F12键进入开发者工具模式(Chrome浏览器),再点击关注标签,进入关注页面,如下图所示:
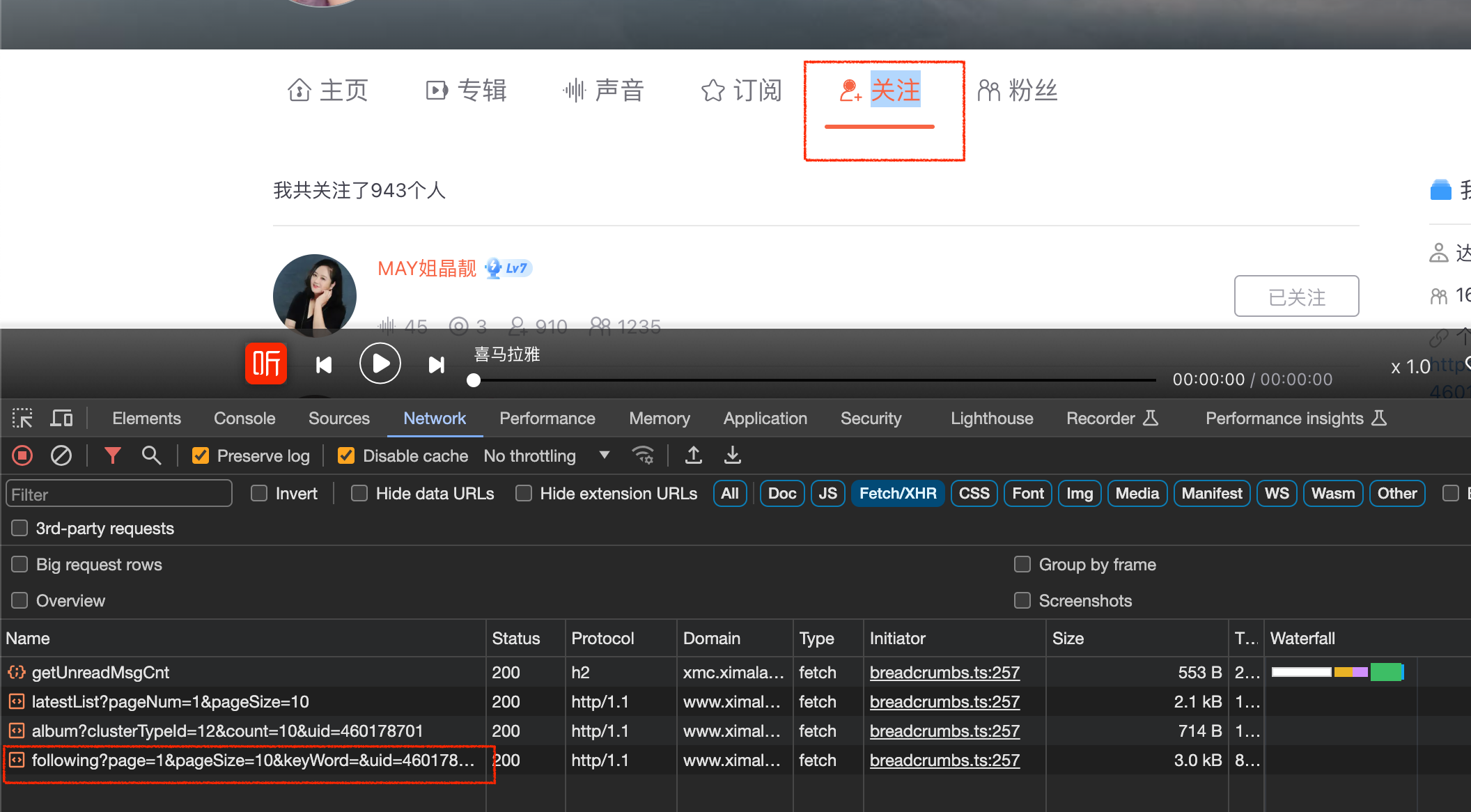
如红框所示就是关注页面的链接,点击红框可以看到headers请求头包含url,如下图所示:

通过分析此页面是异步加载方式,响应的数据为json格式,点击如下图红框所示的标签:

粉丝页面跟这个是同理。不在这里一一截图展示了。那么接下来就是如何获取关注和粉丝的数据了,登录账号以后,就很简单了,代码如下:
import pandas as pd
import requests
import datetimeheaders = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
}# 粉丝数据函数
def get_fans_info(fans_url):# cookies = {'Cookie':'_xmLog=h5&c8be971d-2bc5-45e7-8688-bcdd1db6756e&process.env.sdkVersion; xm-page-viewid=ximalaya-web; impl=www.ximalaya.com.login; x_xmly_traffic=utm_source%253A%2526utm_medium%253A%2526utm_campaign%253A%2526utm_content%253A%2526utm_term%253A%2526utm_from%253A; Hm_lvt_4a7d8ec50cfd6af753c4f8aee3425070=1704697013; wfp=ACM3OGI2ZWMyZjA0YmZmNzZjbgf-TtTrRsF4bXdlYl93d3c; 1&remember_me=y; 1&_token=460178701&BC39CDE0340ND8AF9619AA1EE929208BF9A358F59A66F0159C7A3207C10994A33085862F14E2119M775F0459473319F_; 1_l_flag=460178701&BC39CDE0340ND8AF9619AA1EE929208BF9A358F59A66F0159C7A3207C10994A33085862F14E2119M775F0459473319F__2024-01-2419:20:17; Hm_lpvt_4a7d8ec50cfd6af753c4f8aee3425070=1706145114; web_login=1706148245440'# }session = requests.Session()res = session.get(fans_url, headers=headers)#, cookies=cookies)res_fans = res.json()['data']['fansPageInfo']fans_id = []fans_nickname = []for fan in res_fans:fans_id.append(fan['uid'])fans_nickname.append(fan['anchorNickName'])return fans_id, fans_nickname# return fans_lst# 关注数据函数
def get_following_info(following_url):# cookies = {'Cookie':'_xmLog=h5&c8be971d-2bc5-45e7-8688-bcdd1db6756e&process.env.sdkVersion; xm-page-viewid=ximalaya-web; impl=www.ximalaya.com.login; x_xmly_traffic=utm_source%253A%2526utm_medium%253A%2526utm_campaign%253A%2526utm_content%253A%2526utm_term%253A%2526utm_from%253A; Hm_lvt_4a7d8ec50cfd6af753c4f8aee3425070=1704697013; wfp=ACM3OGI2ZWMyZjA0YmZmNzZjbgf-TtTrRsF4bXdlYl93d3c; 1&remember_me=y; 1&_token=460178701&BC39CDE0340ND8AF9619AA1EE929208BF9A358F59A66F0159C7A3207C10994A33085862F14E2119M775F0459473319F_; 1_l_flag=460178701&BC39CDE0340ND8AF9619AA1EE929208BF9A358F59A66F0159C7A3207C10994A33085862F14E2119M775F0459473319F__2024-01-2419:20:17; Hm_lpvt_4a7d8ec50cfd6af753c4f8aee3425070=1706148771; web_login=1706148792369'# }following_id = []following_nickname = []session = requests.Session()res_follow = session.get(following_url, headers=headers)#, cookies=cookies)follow_data = res_follow.json()['data']for following in follow_data['followingsPageInfo']:# if following['beFollow']:following_id.append(following['uid'])following_nickname.append(following['anchorNickName'])return following_id, following_nicknameif __name__ == '__main__':# 获取当前日期做文件名file_date = str(datetime.date.today())# 创建粉丝数据fans_data = {'UID': [],'粉丝昵称': [],}# 创建关注数据following_data = {'UID': [],'关注昵称': [],}# 创建没有去关注的粉丝数据un_following_fans_data = {'UID': [],'粉丝昵称': [],}# 创建已关注的非粉丝数据un_fans_following_data = {'UID': [],'关注昵称': [],}# 粉丝的数据遍历for i in range(1, 17):fans_url = f'https://www.ximalaya.com/revision/user/fans?page={i}&pageSize=10&keyWord=&uid=460178701'fans_id_lst, fans_nickname_lst = get_fans_info(fans_url)fans_data['UID'].extend(fans_id_lst)fans_data['粉丝昵称'].extend(fans_nickname_lst)# 已关注的数据遍历for n in range(1, 100):following_url = f'https://www.ximalaya.com/revision/user/following?page={n}&pageSize=10&keyWord=&uid=460178701'following_id_lst, following_nickname_lst = get_following_info(following_url)following_data['UID'].extend(following_id_lst)following_data['关注昵称'].extend(following_nickname_lst)# 已关注的非粉丝数据for person_uid in following_data['UID']:if person_uid not in fans_data['UID']:un_fans_following_data['UID'].append(person_uid)un_fans_following_data['关注昵称'].append(following_data['关注昵称'][following_data['UID'].index(person_uid)])# 没有去关注的粉丝数据for unfollow_uid in fans_data['UID']:if unfollow_uid not in following_data['UID']:un_following_fans_data['UID'].append(unfollow_uid)un_following_fans_data['粉丝昵称'].append(fans_data['粉丝昵称'][fans_data['UID'].index(unfollow_uid)])# 创建DataFrame对象df1 = pd.DataFrame(fans_data)df2 = pd.DataFrame(following_data)df3 = pd.DataFrame(un_fans_following_data) # 关注的非粉丝数据df4 = pd.DataFrame(un_following_fans_data) # 没有关注的粉丝数据# 文件生成的路径可以根据自己实际情况设置with pd.ExcelWriter(f"../喜马拉雅项目/喜马拉雅数据表-{file_date}.xlsx") as xlsx:df1.to_excel(xlsx, sheet_name="粉丝数据")df2.to_excel(xlsx, sheet_name="已关注数据")df3.to_excel(xlsx, sheet_name='已关注的非粉丝数据')df4.to_excel(xlsx, sheet_name='没有去关注的粉丝数据')print('数据输出成功!')
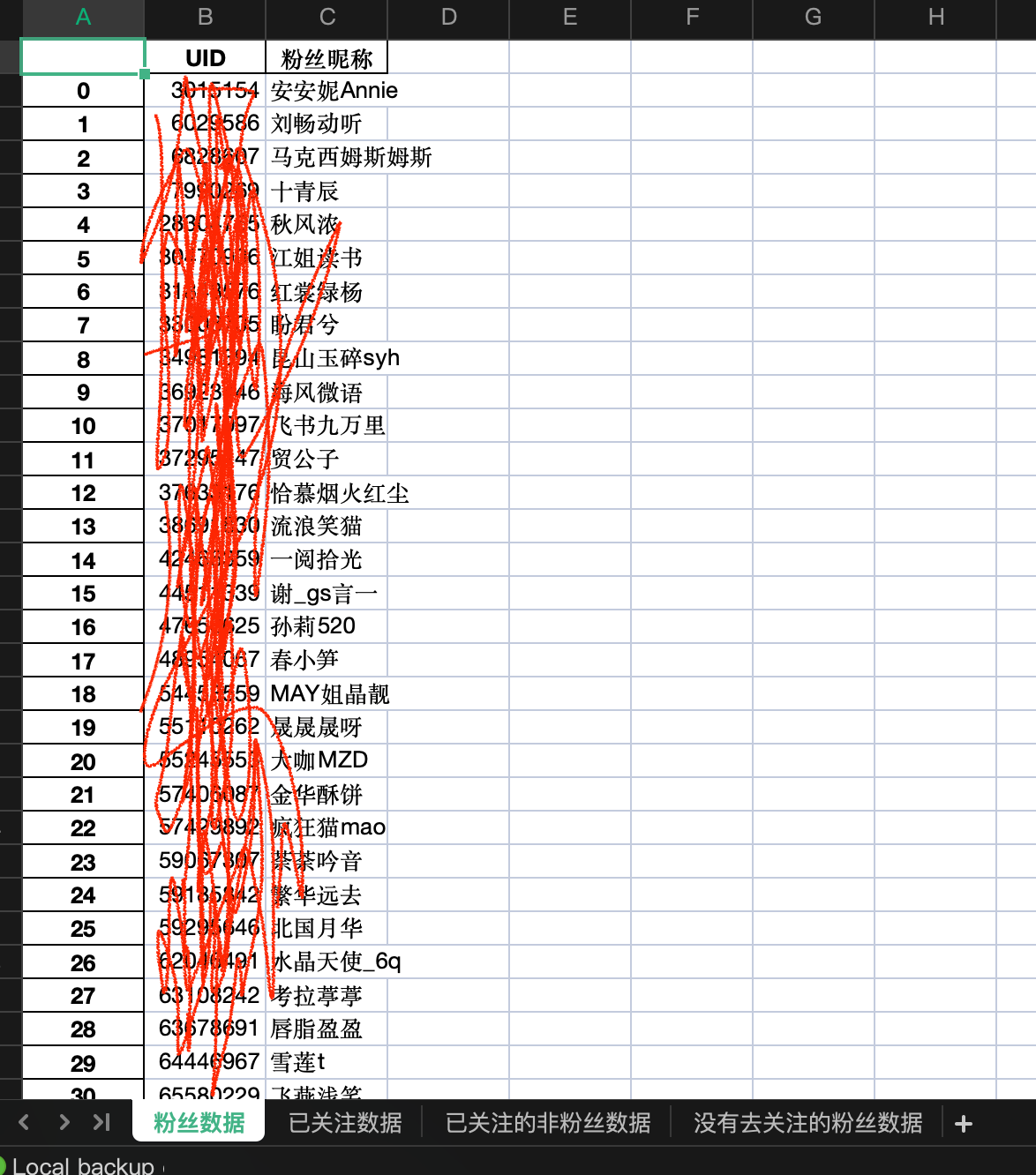
执行如上代码,会生成一个当日的获取数据。如下所示:
接下来,去实现批量关注和取消关注数据的操作,这里涉及到请求头里必须携带cookie,本人是通过手动获取的,因为hook技术我还不熟悉,如果有人熟悉,可以帮我完善一下我的代码,感谢!!!手动获取取消或者关注的cookie,如下图所示:

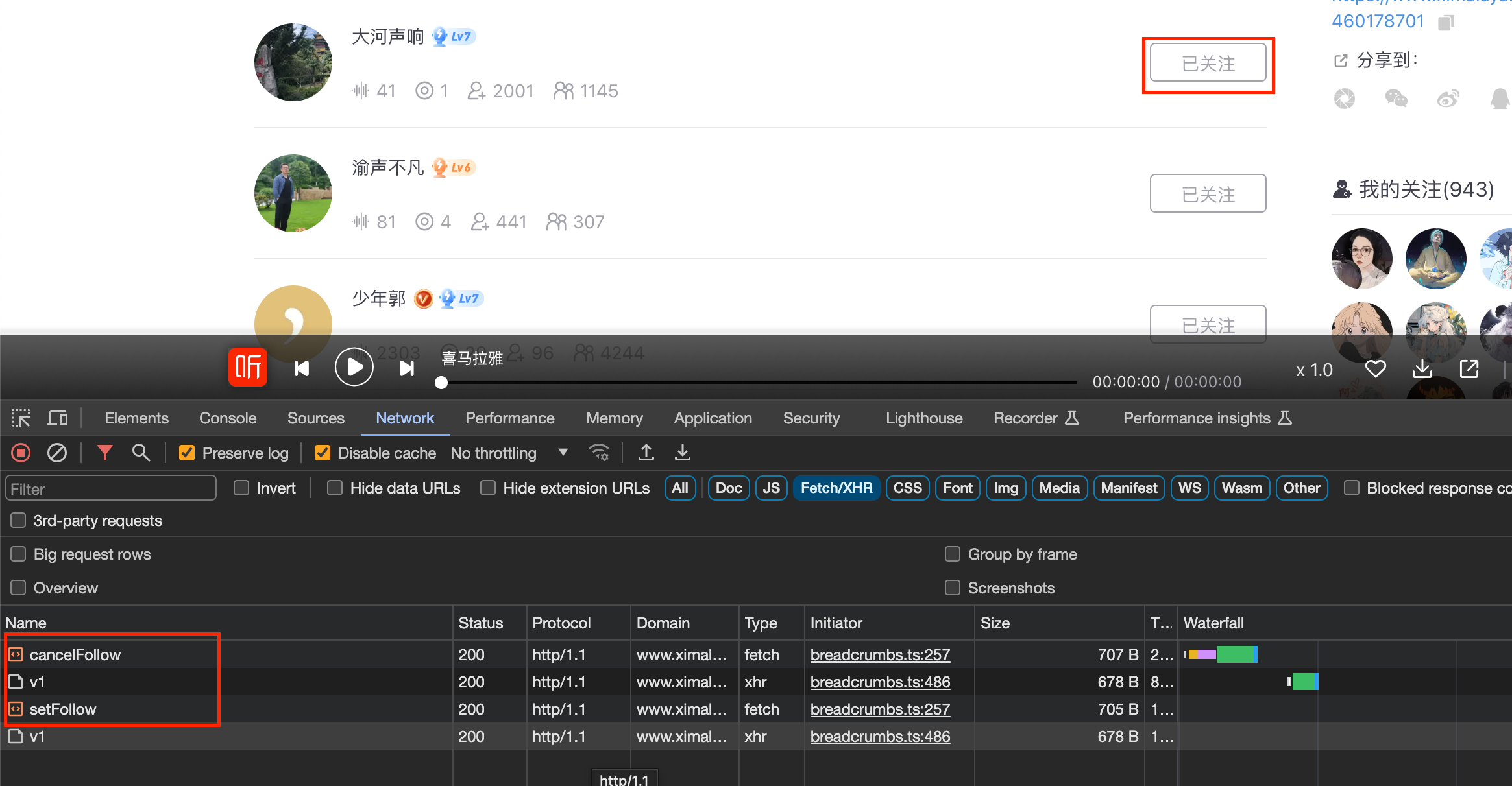
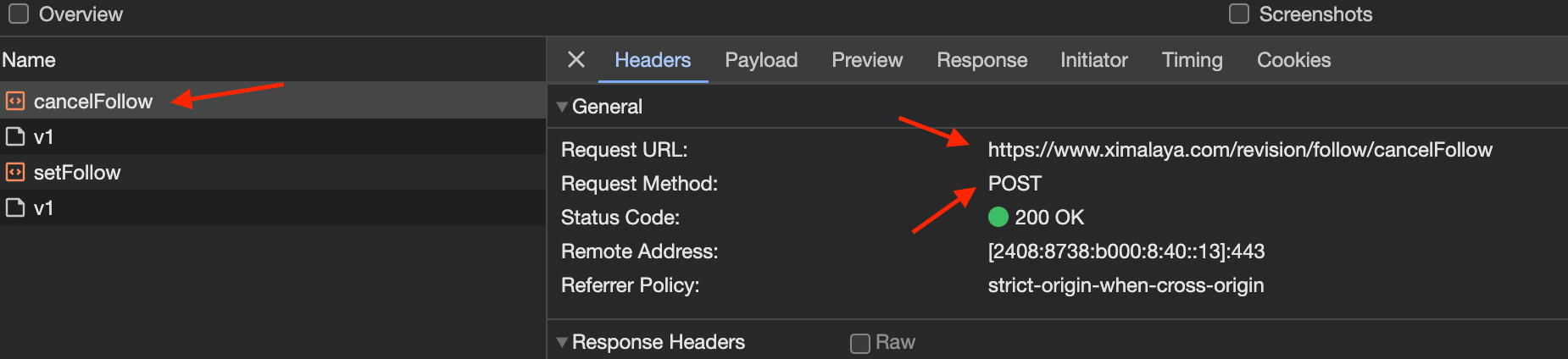
通过上图可以看到,取消关注的请求URL和请求方式POST,接下来点击Payload可以看到请求的data参数值,如下图所示:

点击cancelFollow可以看到红框内的Cookie值,如下图所示:
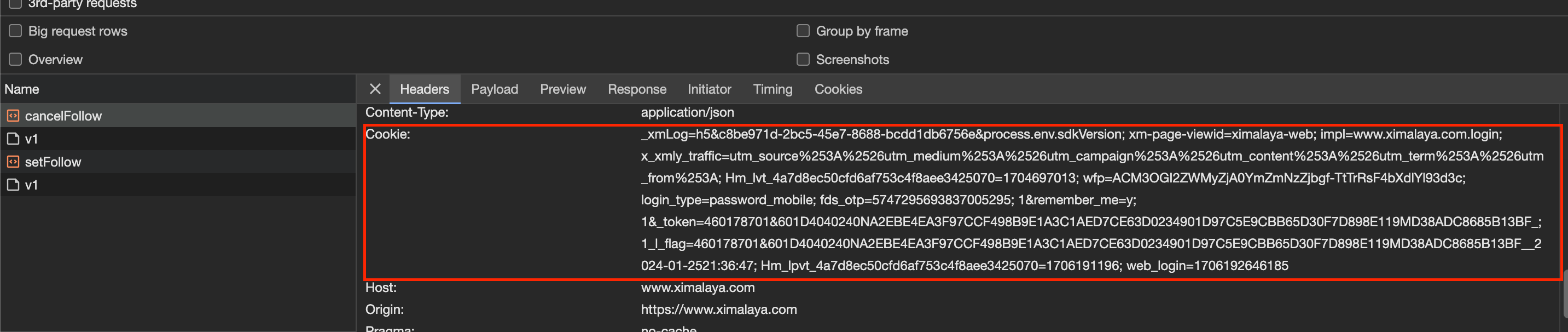
通过如上的分析,实现批量取关和关注的代码如下:
import requests
import pandas as pd
import datetimeheaders = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36','cookie': '你的cookie值'
}# 定义操作
def set_follow(url, uid):session = requests.Session()data = {'followingUid': uid}res = session.post(url, headers=headers, data=data)if res.status_code == 200:print(f'{uid} ' + res.json()['msg'])if res.json()['msg'] == 'isMutualFollowed':print('此UID为互相关注')# 取消关注
def cancel_follow(url, uid):session = requests.Session()data = {'followingUid': uid}res = session.post(url, headers=headers, data=data)if res.status_code == 200:print(f'{uid} ' + res.json()['msg'])def uid_input():try:while 1:uid = input('请输入uid:(q/Q退出)')if uid.lower() == 'q':breakdata_dict['UID'].append(uid)return data_dict['UID']except:print('请核对输入信息!!!')if __name__ == '__main__':file_date = str(datetime.date.today())cancel_follow_url = 'https://www.ximalaya.com/revision/follow/cancelFollow'set_follow_url = 'https://www.ximalaya.com/revision/follow/setFollow'url_dict = {'1': set_follow_url,'0': cancel_follow_url,}# 循环操作while 1:print('<操作选择>:', end='\t')operation = input('关注(1)取关(0)(q/Q)退出:')if operation == '1':data_dict = {'UID': []}data_uid = uid_input()for uid in data_uid:set_follow(url_dict['1'], int(uid))if data_dict['UID']:df1 = pd.DataFrame(data_dict)with pd.ExcelWriter(f"./关注-{file_date}.xlsx") as xlsx:df1.to_excel(xlsx, sheet_name='关注数据',index=False)elif operation.lower() == 'q':breakelif operation == '0':data_dict = {'UID': []}data_uid1 = uid_input()for uid in data_uid1:cancel_follow(url_dict['0'], int(uid))if data_dict['UID']:df2 = pd.DataFrame(data_dict)with pd.ExcelWriter(f"./取关-{file_date}.xlsx") as xlsx:df2.to_excel(xlsx, sheet_name="取关数据", index=False)elif operation.lower() == 'q':break
运行如下图所示:
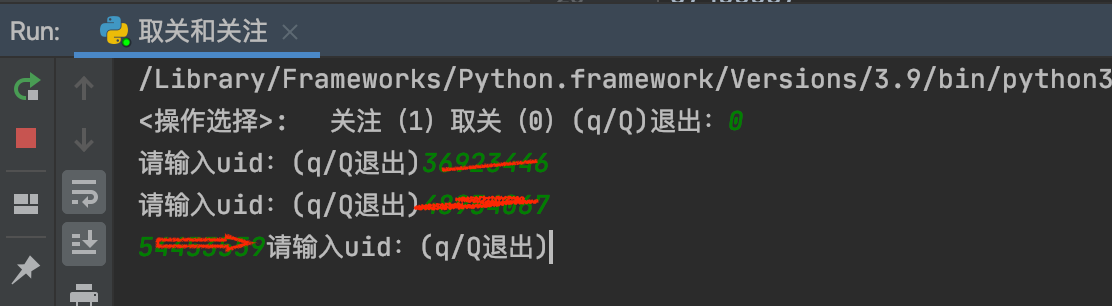
代码都是同步请求方式实现的,代码中的页面数目根据自己的实际情况可以修改。通过朋友验证,效果基本达到了他的要求。我也有点小小的成就感。
这篇关于爬虫实战小案例—获取喜马拉雅账号的关注数据和粉丝数据生成电子表格并实现批量关注或者取关然后生成表格文件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





