本文主要是介绍【LLM问答】两阶段的对话式问答模型ChatQA思路和兼看两阶段的RAG知识问答引擎QAnything,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、ChatQA
1.1 微调
如下图,ChatQA微调包含两个阶段,Supervised Fine-tuning和Context-Enhanced Instruction Tuning

1.1.1 阶段一:SFT(Supervised Fine-tuning)
这个阶段的目标是基于LLM,通过SFT,提高模型对话的能力,使其能够更好地遵循指令并进行对话。
- 数据集构建:为了进行有监督微调,作者们收集了128K个样本,这些样本来自于多个高质量的指令遵循和对话数据集。这些数据集包括:
- Soda:一个社交对话数据集。
- ELI5:包含详细答案的长形式问答数据集。
- FLAN和链式思维数据集:用于训练模型生成连贯的思维链。
- Self-Instruct和Unnatural Instructions:用于指令调整。
- 私有众包对话数据集,以及两个公开的人工编写对话数据集:OpenAssistant和Dolly。
- 无法回答的案例:为了减少在无法回答的情况下产生的幻觉答案,在数据集中加入了无法回答的样本。这些样本是通过让标注者提供所有上下文位置给用户问题,然后删除相关文本来构建的。对于无法回答的问题,使用“对不起,我无法根据上下文找到答案”作为响应。
- 数据统一格式:为了微调,所有的SFT数据都被统一为对话格式。在数据中添加了一个“系统”角色来设置一般指令,指导LLM提供有礼貌和有帮助的答案。同时,添加了“用户”和“助手”角色来整合来自指令调整数据集的指令和响应对。
- 微调过程:使用统一的格式对LLM基础模型进行微调。这个过程旨在提高模型在遵循指令和生成对话方面的性能。
第一阶段LLM的输入输出:
输入:格式模版如下
System: This is a chat between a user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user’s questions
based on the context. The assistant should also indicate when the answer cannot be
found in the context.
User: {Question 1}
Assistant: {Answer 1}
...
User: {Latest Question}
Assistant:
输出:Assistant的最新回答。
小结:通过这个阶段的微调,模型能够更好地理解对话的上下文,并在对话中提供有帮助和准确的回答。这为后续的上下文增强指令调整阶段奠定了基础,使得模型能够在对话式问答任务中更好地利用上下文信息。
1.1.2 阶段二:上下文增强指令调整(Context-Enhanced Instruction Tuning)
该阶段旨在进一步的增强模型在对话式问答中对上下文的敏感性和处理检索增强生成的能力。这个阶段的训练数据集由上下文化单轮问答和对话式问答数据集混合而成,具体包括:
- Human Annotated Data:
- HumanAnnotatedConvQA数据集:这是一个人工注释的对话式问答数据集,包含7k个对话。这些对话是通过让标注者扮演好奇的用户提出问题(以及后续问题)和作为代理给出答案来构建的。每个文档都会生成一个多轮对话,平均每个对话有5个用户-代理回合。
- 合成数据生成(Synthetic Data Generation):
- SyntheticConvQA数据集:这是一个通过GPT-3.5-turbo生成的中等大小的高质量合成数据集。这个数据集是通过从公共爬取(common crawl)中收集的7k篇文档构建的,每篇文档用于生成一个单轮对话式问答样本,总共产生了7k个多轮对话,平均每个对话有4.4个用户-代理回合。
- 训练混合(Training Blends):
- 对话式问答数据集:HumanAnnotatedConvQA 或 SyntheticConvQA。
- 单轮问答数据集:DROP、NarrativeQA、Quoref、ROPES、SQuAD1.1、SQuAD2.0、NewsQA、TAT-QA(了增强问答模型处理表格文档和算术计算的能力)。
- 阶段一的SFT数据集:这些数据集在第二阶段的指令调整中仍然被使用,以保持模型的指令遵循能力。
第二阶段的输入输出:
输入:格式模版
System: This is a chat between a user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user’s questions
based on the context. The assistant should also indicate when the answer cannot be
found in the context.
{Context for Latest Question}
User: {Instruction} + {Question 1}
Assistant: {Answer 1}
...
User: {Latest Question}
Assistant:
输出:与第一阶段一样,输出Assistant的最新回答。
小结:通过第二阶段的上下文增强指令调整,模型能够更好地理解和利用对话中的上下文信息,从而在对话式问答任务中提供更准确和相关的回答。这一阶段的训练特别强调了模型在处理检索增强生成任务时的能力,这对于对话式问答中处理长文档或需要检索的上下文尤为重要。
1.2 ChatQA(检索增强对话式问答(Retrieval for Multi-Turn QA))

在对话式问答中,当提供的文档内容过长,无法直接输入到大型语言模型(LLM)时,检索器(Retriever)变得尤为重要。RAG(检索器的作用是从文档中检索出与当前对话历史和用户问题相关的上下文片段。然后,这些相关的上下文片段被用作LLM的输入,以生成对话式问答的答案。)因此微调检索器,有助于提高其在对话式问答任务中的性能。
1.2.1 微调检索器(Fine-tuning Retriever)
为了构建高质量的微调数据集,作者们利用了对话式问答数据集(HumanAnnotatedConvQA或SyntheticConvQA)来构建对话式查询和上下文对。这些对话式查询和上下文对用于进一步微调一个单轮检索器,使其能够更好地处理对话式输入。
1.2.2 对话式查询重写(Conversational Query Rewriting)
使用查询重写器(Query Rewriter)根据对话历史重写当前问题。重写后的问题可以直接用作单轮查询检索器的输入,以检索相关上下文。然而,这种方法需要额外的计算时间来生成重写后的查询,并且可能还需要使用像GPT-3.5-turbo这样的强大模型,这可能会增加API成本。
1.2.3 对比(Comparisons)
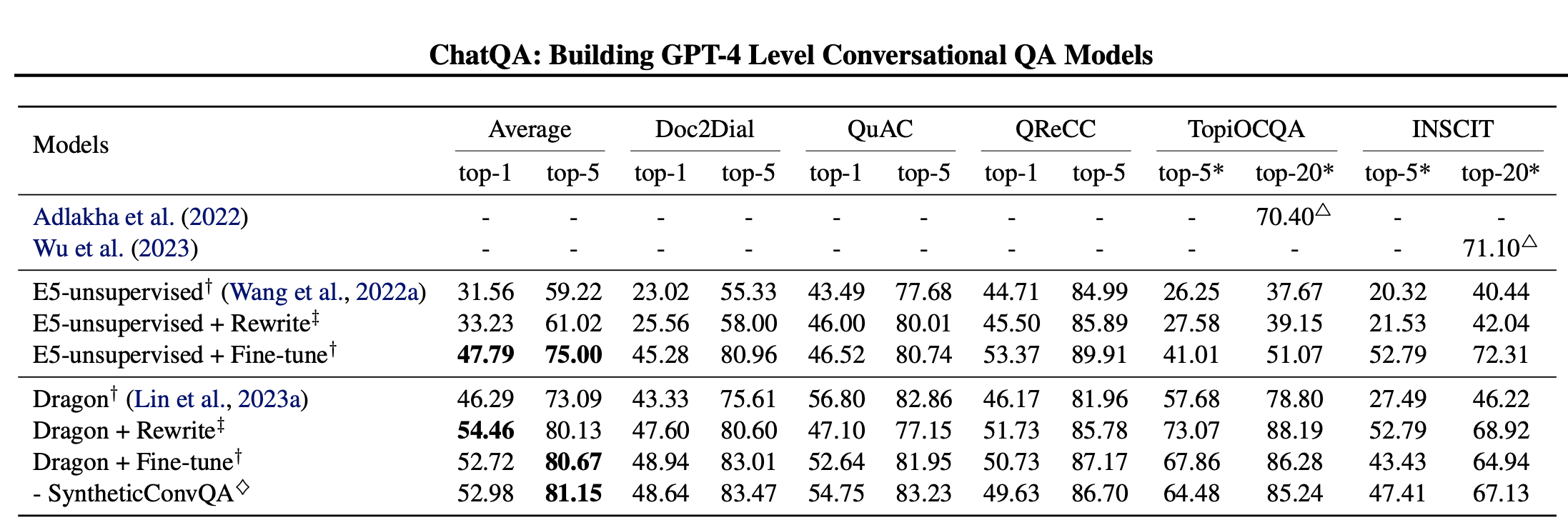
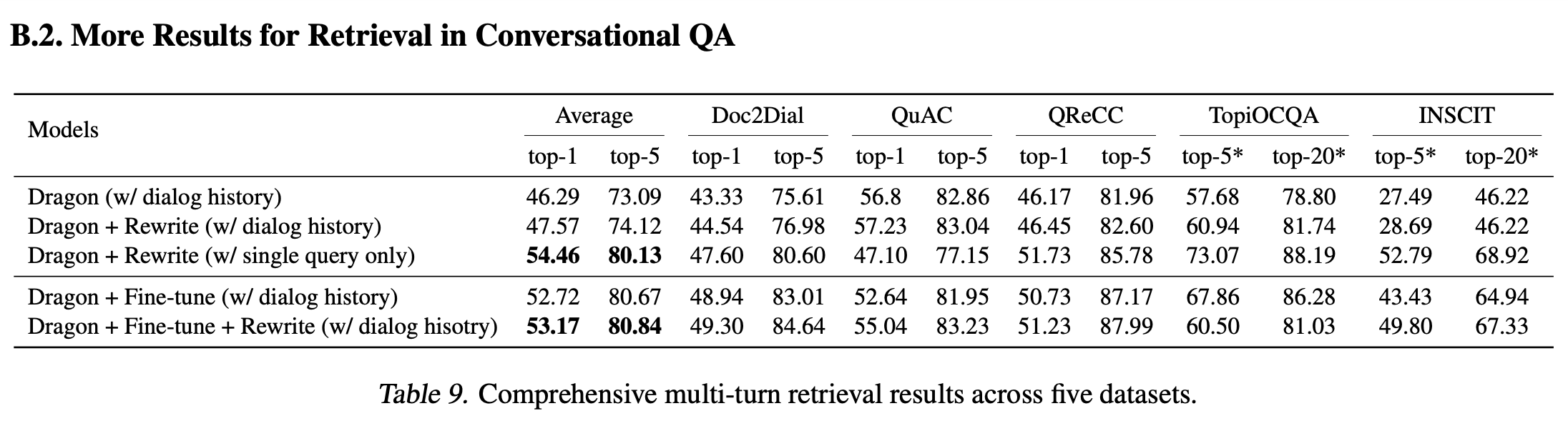
表中发现与仅使用重写的query作为输入(Dragon + 重写(仅使用单个查询))相比,提供额外的对话历史(Dragon + 重写(带有对话历史))会使得平均分数显著下降。这是因为 Dragon 最初是在单轮查询上进行预训练的,因此当提供单轮重写的查询而不是多轮对话时,它自然会具有更好的泛化能力。而且重写的query已经包含了来自对话历史的足够信息。此外,我们观察到“Dragon + 微调”与“Dragon + 微调 + 重写”表现相当。换句话说,对于多轮微调方法,用重写的查询替换原始查询作为输入能够取得相当的结果。这是因为重写的查询对于模型来说并不会提供太多额外信息,因为对话历史已经提供,甚至可能会产生负面效果(例如,在 TopiOCQA 数据集上的结果),因为它使整个对话输入不够自然。说明了微调方法在使模型具备理解多轮上下文能力方面的有效性。
二、QAnything
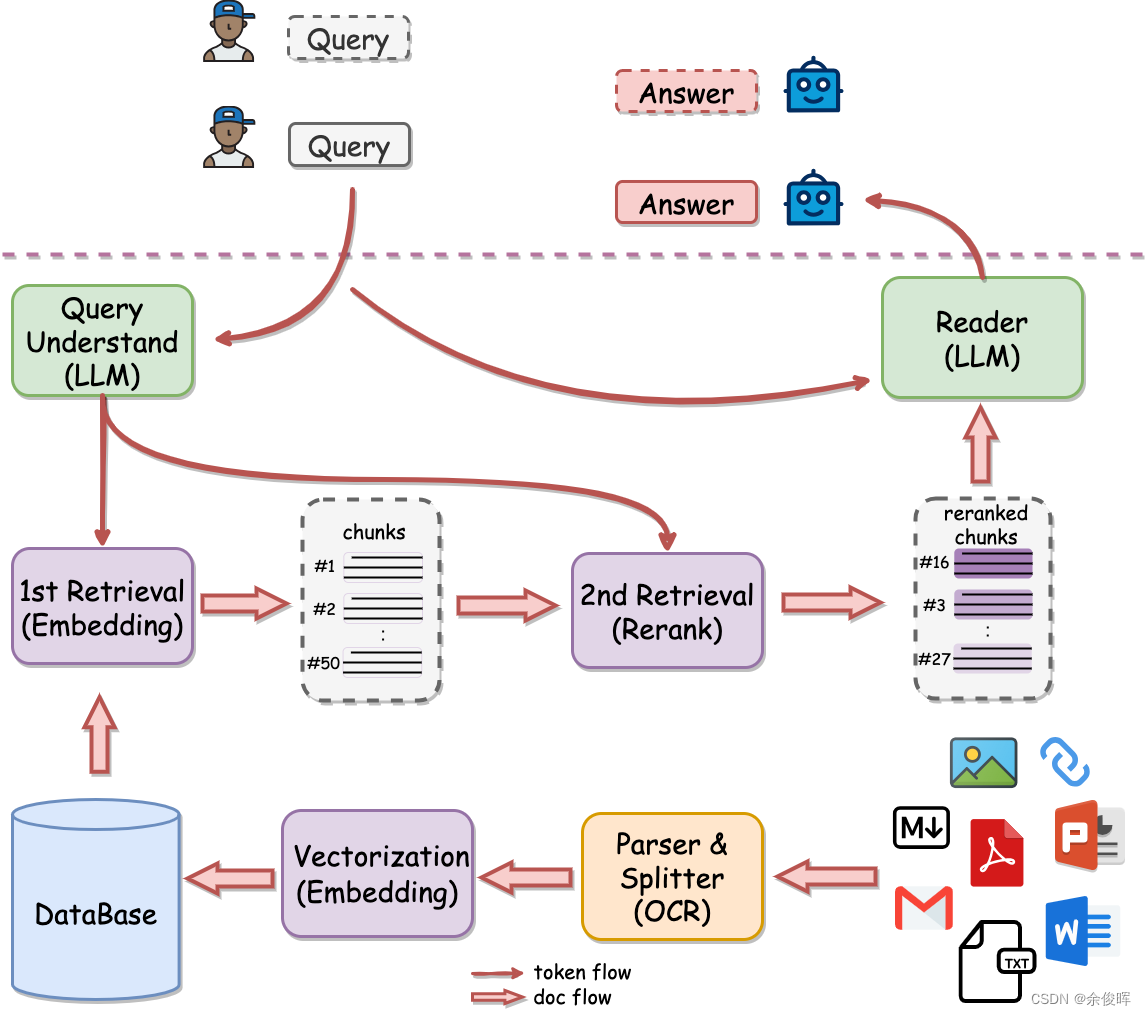
2.1 架构
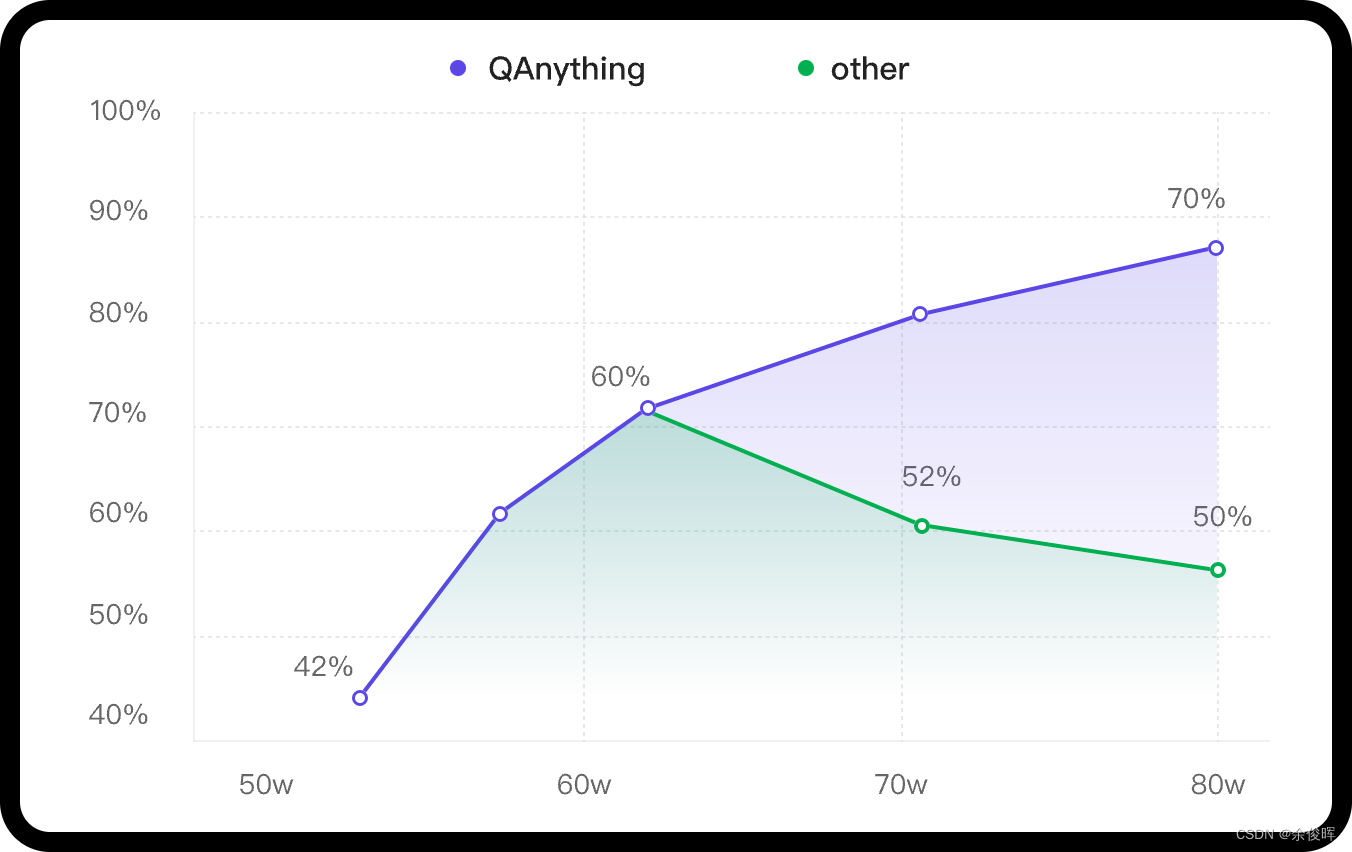
知识库数据量大的场景下两阶段优势非常明显,如果只用一阶段embedding检索(传统RAG),随着数据量增大会出现检索退化的问题,如下图中绿线所示,二阶段rerank重排后能实现准确率稳定增长,即数据越多,效果越好。
因此步骤很简单:
-
各种格式的文档通过各种解析工具(
)进行解析,并向量化;
-
基于BCE向量表征模型的1阶段检索(embedding);
-
基于BCE向量表征模型的2阶段检索(rerank);
-
LLM理解,输出答案
2.2 BCE向量表征模型
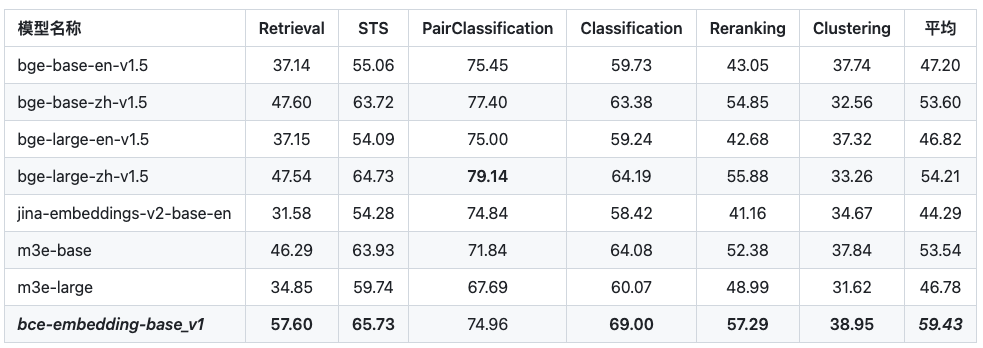
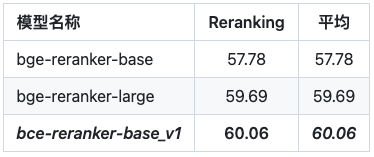
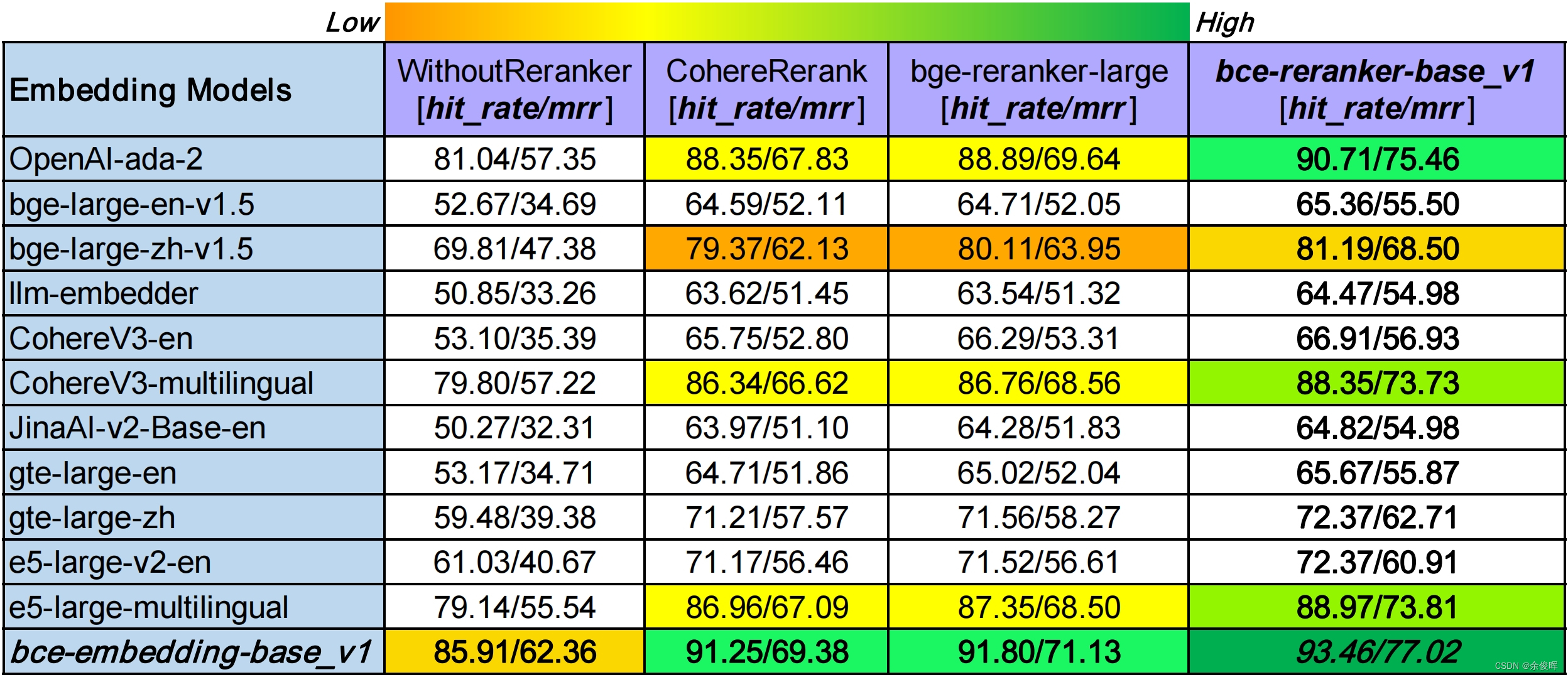
两阶段的检索都使用了BCE向量表征模型,其在两个阶段的性能都优于其他向量表征模型;
2.2.1 一阶段检索(embedding)
2.2.2 二阶段检索(rerank)
2.2.3 基于LlamaIndex的RAG评测(embedding and rerank)
总结
ChatQA:这篇文章的两阶段微调的ChatQA模型,对于对话式问答任务,特别是处理长文档和需要检索的上下文时对话时,能够达到或超过GPT-4的性能水平。
QAnything:介绍了基于微调的Qwen-7b,两阶段的RAG知识库问答引擎 QAnything,支撑任意格式的文档数据私有化进行知识问答。
参考文献
【1】ChatQA: Building GPT-4 Level Conversational QA Models,https://arxiv.org/pdf/2401.10225.pdf
【2】https://github.com/netease-youdao/BCEmbedding
【3】https://github.com/netease-youdao/QAnything/blob/master/README_zh.md
【4】QAnything:https://github.com/netease-youdao/QAnything/tree/master
这篇关于【LLM问答】两阶段的对话式问答模型ChatQA思路和兼看两阶段的RAG知识问答引擎QAnything的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








