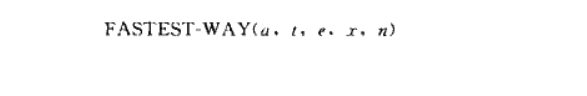前言:动态规划的概念
动态规划(dynamic programming)是通过组合子问题的解而解决整个问题的。分治算法是指将问题划分为一些独立的子问题,递归的求解各个问题,然后合并子问题的解而得到原问题的解。例如归并排序,快速排序都是采用分治算法思想。本书在第二章介绍归并排序时,详细介绍了分治算法的操作步骤,详细的内容请参考:http://www.cnblogs.com/Anker/archive/2013/01/22/2871042.html。而动态规划与此不同,适用于子问题不是独立的情况,也就是说各个子问题包含有公共的子问题。如在这种情况下,用分治算法则会重复做不必要的工作。采用动态规划算法对每个子问题只求解一次,将其结果存放到一张表中,以供后面的子问题参考,从而避免每次遇到各个子问题时重新计算答案。
动态规划与分治法之间的区别:
(1)分治法是指将问题分成一些独立的子问题,递归的求解各子问题
(2)动态规划适用于这些子问题不是独立的情况,也就是各子问题包含公共子问题
动态规划通常用于最优化问题(此类问题一般有很多可行解,我们希望从这些解中找出一个具有最优(最大或最小)值的解)。动态规划算法的设计分为以下四个步骤:
(1)描述最优解的结构
(2)递归定义最优解的值
(3)按自低向上的方式计算最优解的值
(4)由计算出的结果构造一个最优解
动态规划最重要的就是要找出最优解的子结构。书中接下来列举4个问题,讲解如何利用动态规划方法来解决。动态规划的内容比较多,我计划每个问题都认真分析,写成日志。今天先来看第一个问题:装配线调度问题
2、问题描述
一个汽车公司在有2条装配线的工厂内生产汽车,每条装配线有n个装配站,不同装配线上对应的装配站执行的功能相同,但是每个站执行的时间是不同的。在装配汽车时,为了提高速度,可以在这两天装配线上的装配站中做出选择,即可以将部分完成的汽车在任何装配站上从一条装配线移到另一条装配线上。装配过程如下图所示: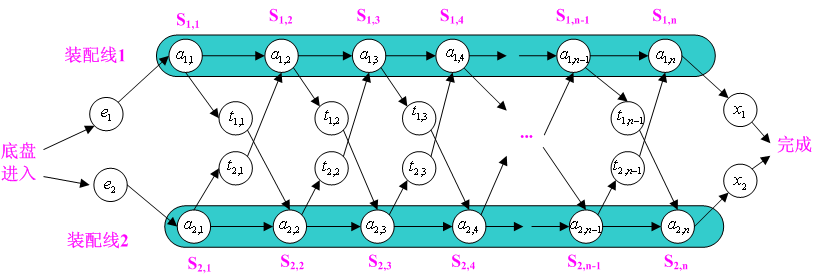
装配过程的时间包括:进入装配线时间e、每装配线上各个装配站执行时间a、从一条装配线移到另外一条装配线的时间t、离开最后一个装配站时间x。举个例子来说明,现在有2条装配线,每条装配线上有6个装配站,各个时间如下图所示: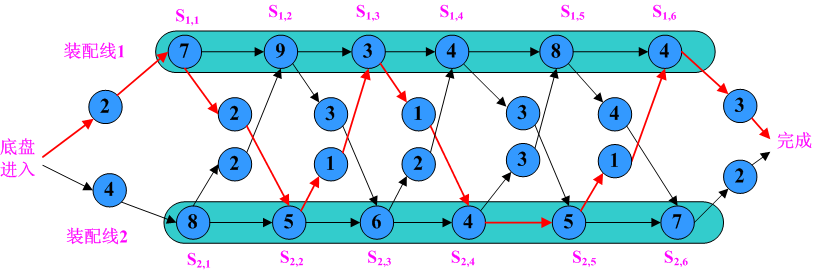
从图中可以看出按照红色箭头方向进行装配汽车最快,时间为38。分别现在装配线1上的装配站1、3和6,装配线2上装配站2、4和5。
3、动态规划解决步骤
(1)描述通过工厂最快线路的结构
对于装配线调度问题,一个问题的(找出通过装配站Si,j的 最快线路)最优解包含了子问题(找出通过S1,j-1或S2,j-1的最快线路)的一个最优解,这就是最优子结构。观察一条通过装配站S1,j的最快线路,会发现它必定是经过装配线1或2上装配站j-1。因此通过装配站的最快线路只能以下二者之一:
a)通过装配线S1,j-1的最快线路,然后直接通过装配站Si,j;
b)通过装配站S2,j-1的最快线路,从装配线2移动到装配线1,然后通过装配线S1,j。
为了解决这个问题,即寻找通过一条装配线上的装配站j的最快线路,需要解决其子问题,即寻找通过两条装配线上的装配站j-1的最快线路。
(2)一个递归的解
最终目标是确定底盘通过工厂的所有路线的最快时间,设为f*,令fi[j]表示一个底盘从起点到装配站Si,j的最快时间,则f* = min(f1[n]+x1,f2[n]+x2)。逐步向下推导,直到j=1。
当j=1时: f1[1] = e1+a1,1,f2[1] = e2+a2,1。
当j>1时:f1[j] = min(f1[j-1]+a1,j,f2[j-1]+t2,j-1+a1,j),f2[j] = min(f2[j-1]+a2,j,f1[j-1]+t1,j-1+a2,j)。