本文主要是介绍Datawhale 强化学习笔记(二)马尔可夫过程,DQN 算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 参考
- 马尔可夫过程
- DQN 算法(Deep Q-Network)
- 如何用神经网络来近似 Q 函数
- 如何用梯度下降的方式更新网络参数
- 强化学习 vs 深度学习
- 提高训练稳定性的技巧
- 经验回放
- 目标网络
- 代码实战
- DQN 算法进阶
- Double DQN
- Dueling DQN 算法
- 代码实战
参考
在线阅读文档
github 教程
开源框架 JoyRL datawhalechina/joyrl: An easier PyTorch deep reinforcement learning library. (github.com)
马尔可夫过程
强化学习是解决序列决策问题的有效方法,而序列决策问题的本质是在与环境交互的过程中学习到一个目标的过程。
马尔可夫决策过程是强化学习中最基本的问题模型,它能够以数学的形式来表达序列决策过程。
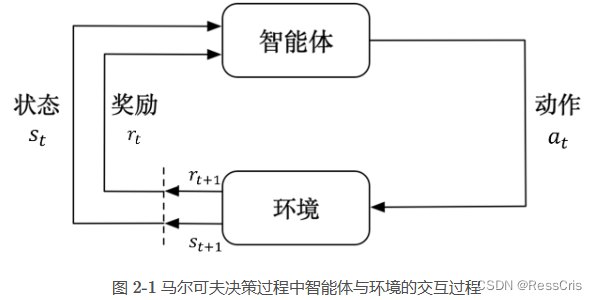
比较重要的概念
马尔科夫决策过程
马尔科夫性质
回报
状态转移矩阵
DQN 算法(Deep Q-Network)
它的主要贡献就是在 Q-learning 算法的基础上引入了深度神经网络来近似动作价值函数 ,从而能够处理高维的状态空间。除了用深度网络代替 Q 表之外, DQN 算法还引入了一些技巧,如经验回放和目标网络。
如何用神经网络来近似 Q 函数
类似于 Q表,可以就用来近似动作价值函数 Q ( s , a ) Q(s, a) Q(s,a), 即将状态向量 s s s 作为输入,并输出所有动作 a = ( a 1 , a 2 , . . . , a n ) a=(a_1, a_2,...,a_n) a=(a1,a2,...,an)对应的价值。
y = Q θ ( s , a ) y = Q_{\theta}(s, a) y=Qθ(s,a)
Q 表是一个二维表格,而神经网络是一个实实在在的函数。前者只能处理离散的状态和动作空间,而神经网络可以处理连续的状态和动作空间。在 Q 表中我们描述状态空间的时候一般用的是状态个数,而在神经网络中我们用的是状态维度。
无论是 Q 表还是 DQN 中的神经网络,它们输出的都是每个动作对应的 Q 值,即预测,而不是直接输出动作。要想输出动作,就需要额外做一些处理,例如结合贪心算法选择 Q 值最大对应的动作等,这就是我们一直强调的控制过程。
如何用梯度下降的方式更新网络参数

强化学习 vs 深度学习
训练方式是一样的,都是将样本喂入网络中,然后通过梯度下降的方式来更新网络参数,使得损失函数最小,即能够逼近真实的 Q 值。
不同点
- 强化学习用于训练的样本(包括状态、动作和奖励等等)是与环境实时交互得到的,而深度学习则是事先准备好的。
- 本质上来讲强化学习和深度学习所要解决的问题是完全不同的,前者用于解决序列决策问题,后者用于解决静态问题例如回归、分类、识别等任务
提高训练稳定性的技巧
经验回放
这个样本一般包括当前的状态 s t s_t st 、当前动作 a t a_t at 、下一时刻的状态 s t + 1 s_{t+1} st+1 、奖励 r t + 1 r_{t+1} rt+1 以及终止状态的标志 done (通常不呈现在公式中),也叫做一个状态转移(transition ),即 ( s t , a t , s t + 1 , r t + 1 s_t, a_t,s_{t+1}, r_{t+1} st,at,st+1,rt+1 )。在 Q-learning 算法中,每次交互得到一个样本之后,就立马拿去更新模型了。
这样的方式用在神经网络中会有一些问题,这跟梯度下降有关。首先每次用单个样本去迭代网络参数很容易导致训练的不稳定,从而影响模型的收敛,在深度学习基础的章节中我们也讲过小批量梯度下降是目前比较成熟的方式。其次,每次迭代的样本都是从环境中实时交互得到的,这样的样本是有关联的,而梯度下降法是基于一个假设的,即训练集中的样本是独立同分布的。
经验回放会把每次与环境交互得到的样本都存储在一个经验回放中,然后每次从经验池中随机抽取一批样本来训练网络。
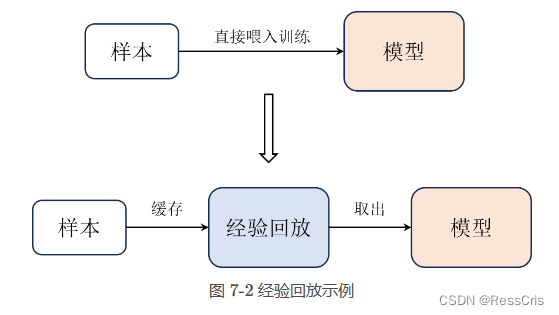
在训练初期智能体生成的样本虽然能够帮助它朝着更好的方向收敛,但是在训练后期这些前期产生的样本相对来说质量就不是很好了。经验回放的容量需要有一定的容量限制,太小导致收集到的样本具有一定的局限性,太大失去了经验本身的意义。
目标网络
使用了一个每隔若干步才更新的目标网络。
目标网络和当前网络结构都是相同的,都用于近似 Q 值,在实践中每隔若干步才把每步更新的当前网络参数复制给目标网络,这样做的好处是保证训练的稳定,避免 Q 值的估计发散。如果当前有个小批量样本导致模型对
值进行了较差的过估计,如果接下来从经验回放中提取到的样本正好连续几个都这样的,很有可能导致 Q
值的发散。
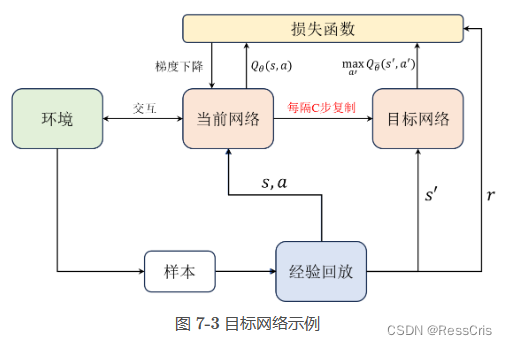
对于目标网络的作用,这里举一个典型的例子,这里的目标网络好比皇帝,而当前网络相当于皇帝手下的太监,每次皇帝在做一些行政决策时往往不急着下定论,会让太监们去收集一圈情报,然后集思广益再做决策。
代码实战
github 教程 中 notebooks 中的第7章代码
和大多数强化学习算法一样,分为交互采样和模型更新两个步骤。
其中交互采样的目的就是与环境交互并产生样本,模型更新则是利用得到的样本来更新相关的网络参数,更新方式涉及每个强化学习算法的核心。

根据强化学习的原理我们需要优化的是对应状态下不同动作的长期价值,然后每次选择价值最大对应的动作就能完成一条最优策略,使用神经网络表示Q表时也是如此,我们将输入的状态数作为神经网络的输入层,动作数作为输出层,这样的神经网络表达的功能就跟在Q learning中的Q表是一样的,只不过具有更强的鲁棒性。
DQN 算法进阶
改进的角度不同,本质上都是通过提高预测的精度和控制过程中的探索度来改善算法性能。
-
网络层面
- Double DQN (google DeepMind 2015年12月提出)
- 通过引入两个网络解决 Q 值过估计的问题。改进目标 Q 值的计算来优化算法
- Dueling DQN
- 通过优化神经网络的结构
- Noisy DQN
- 优化网络结构,但不是为了提高Q值的估计,而是增强网络的探索能力
- 引入噪声层
- Double DQN (google DeepMind 2015年12月提出)
-
经验回放
- PER DQN(优先经验回放 ,prioritized experience replay)
- 优化深度网络中梯度下降的方式,或者说网络参数更新的方式
- 和数据结构中优先队列与普通队列一样,会在采样过程中赋予经验回放中样本的优先级。
- PER DQN(优先经验回放 ,prioritized experience replay)
Double DQN
动作选择和动作评估两个过程分离开来,从而减轻了过估计问题。
在 DQN 算法中,大臣是不管好的还是坏的情报都会汇报给皇帝的,而在 Double DQN 算法中大臣会根据自己的判断将自己认为最优的情报汇报给皇帝,即先在策略网络中找出最大 Q 值对应的动作。这样一来皇帝这边得到的情报就更加精简并且质量更高了,以便于皇帝做出更好的判断和决策,也就是估计得更准确了。
DQN 将下一个状态对应的最大Q值作为实际值(因为实际值通常不能直接求得,只能近似),这种做法实际上只是一种近似,可能会导致过估计等问题。 而在Double DQN中,它不直接通过最大化的方式选取目标网络计算的所有可能 Q 值,而是首先通过估计网络选取最大 Q 值对应的动作。
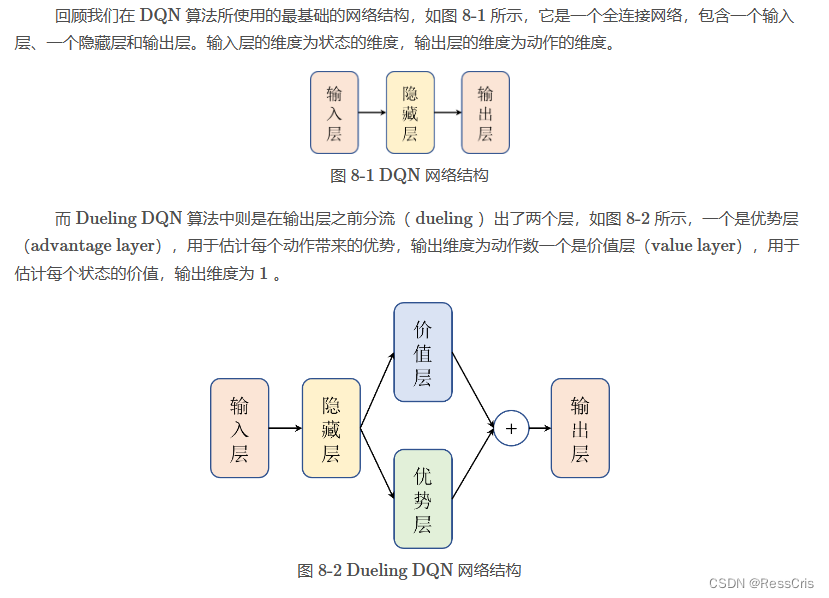
Dueling DQN 算法
代码实战
github 教程 中 notebooks 中的第8章代码
这篇关于Datawhale 强化学习笔记(二)马尔可夫过程,DQN 算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






