本文主要是介绍精确掌控并发:漏桶算法在分布式环境下并发流量控制的设计与实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是《百图解码支付系统设计与实现》专栏系列文章中的第(16)篇,也是流量控制系列的第(3)篇。点击上方关注,深入了解支付系统的方方面面。
本篇重点讲清楚漏桶原理,在支付系统的应用场景,以及使用reids实现的核心代码。
1. 前言
在流量控制系列文章中的前两篇,分别介绍了固定时间窗口算法和滑动时间窗口算法在支付渠道限流的应用以及使用redis实现的核心代码。
这两个算法有一个共同的问题:那就是超过阀值的数据会直接拒绝掉。如果超过阀值也不想拒绝请求,后面仍然发出去,怎么办?这就是本篇要说的漏桶及下篇要讲的令牌桶解决的问题。
2. 漏桶原理
漏桶算法通过模拟水桶漏水的过程来控制数据的传输速率。它允许短时间的突发数据流,随后以恒定的速率排空积聚的数据。这种机制特别适合于需要平滑处理瞬时高流量冲击,但后端需要恒定速率处理的场景。比如批量接收上游商户的退款,然后根据渠道的要求以极低的TPS慢慢退出去到渠道。
最简单的理解,漏桶 = 队列 + 固定窗口算法。其中队列用于先保存数据。固定窗口算法用于获取可用计数,获取到就从队列获取一个请求进行业务处理。
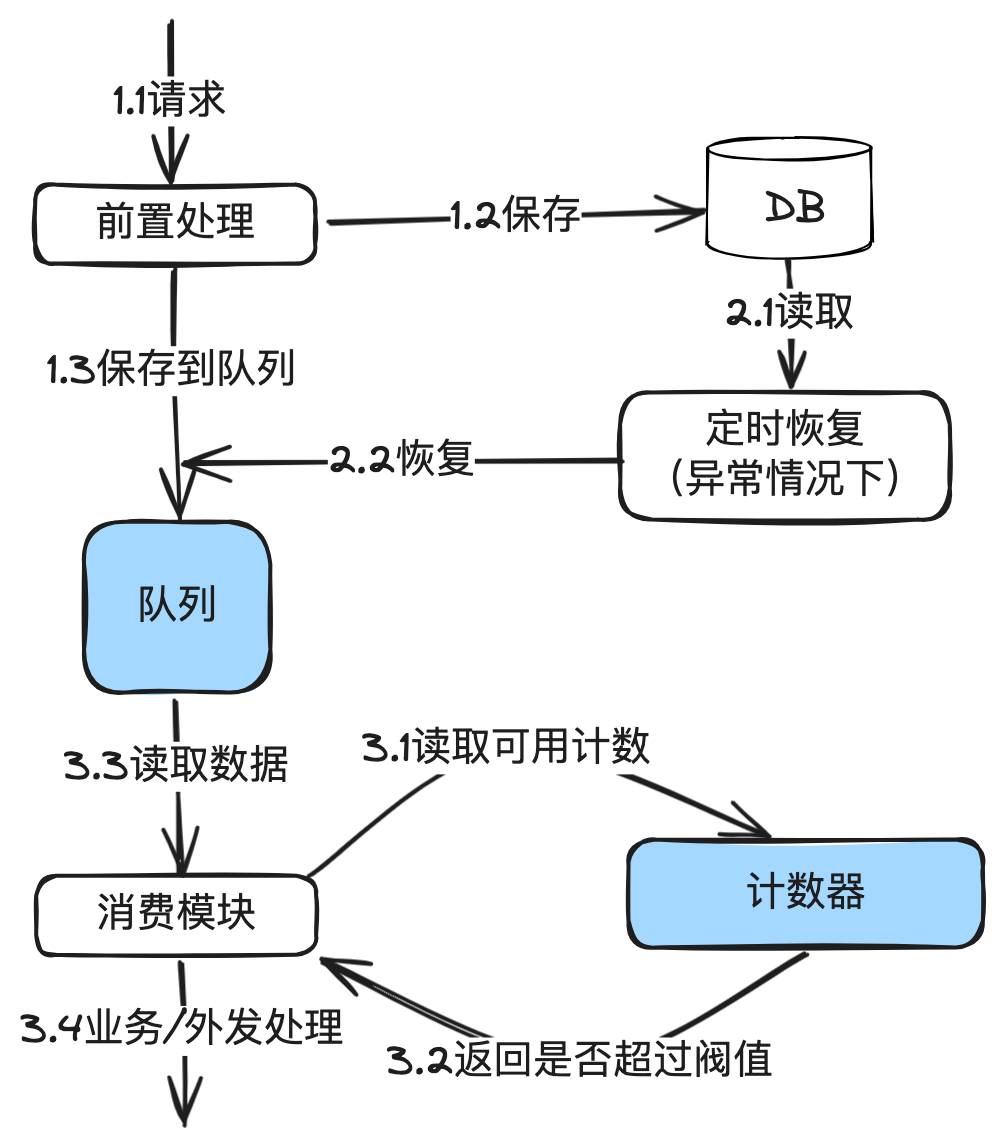
工作原理:
- 桶容量:漏桶有一个固定的容量,代表在任何时刻系统能够容纳的最大请求量。比如上面图中的队列。
- 数据流入:数据来了后就保存到桶(队列)中,如果桶已满,则溢出的数据会被丢弃。
- 恒定速率流出:数据以固定的速率从桶中“漏出”,即被处理。这个速率是预先设定的,与请求量无关。
- 计数器最简单的做法,就是把固定时间窗口的代码用起来。
- 保存到数据库,是为了持久化,以及队列出现问题时,可以重新恢复。
3. 在支付系统下的应用场景
中国的IT基础设施领先于全球各个国家,各大银行和第三方钱包也被各电商双十一等大促场景狂虐之后进化到支持极高的TPS,但是在跨境场景下,比如东南亚或南美的国家,他们的银行IT基础设施差,系统老旧,无法支持高并发流量。甚至碰到过一些银行要求退款只能有1TPS。
在分布式场景下,要做到1TPS的高精度限流,只能依赖漏桶来做。
4. Redis实现漏桶的核心代码
漏桶算法通常通过队列 + 固定时间窗口计数法来实现。队列存储待处理的请求,而一个线程以固定速率从队列中取出并处理这些请求。
为什么又是Redis?因为前面已经实现过Redis版本的固定时间窗口算法,再加一个队列就可以搞定。当然大家也可以选择其它的方案实现,这只是一个抛砖引玉。
下面是单机版本的伪代码:
public class LeakyBucket {private final int capacity;private final long leakIntervalInMillis;private final LinkedBlockingQueue<Data> bucket;public LeakyBucket(int capacity, long leakRateInMillis) {this.capacity = capacity;this.leakIntervalInMillis = leakRateInMillis;this.bucket = new LinkedBlockingQueue<>(capacity);}// 尝试添加数据到桶中public boolean addToBucket(Data data) {return bucket.offer(data);}// 启动桶的漏水过程public void startLeaking() {new Thread(() -> {while (true) {try {Data data = bucket.poll(leakIntervalInMillis, TimeUnit.MILLISECONDS);if (data != null) {process(data);}} catch (InterruptedException e) {log.debug("Leaking process interrupted");continue;}}}).start();}// 处理桶中的数据private void process(Data data) {// 业务处理... ...}
}上面单机的代码实用性不高,因为在分布式环境下,并发请求量是根据部署机器累计起来的,1台机器限流1TPS,20台机器就到了20TPS。
优化为分布式:
class LeakyBucketHolding {private final LinkedBlockingQueue<Data> bucket;private int limit;private String bizType;public LeakyBucketHolding(String bizType, int capacity, int limit) {this.bizType = bizType;this.bucket = new LinkedBlockingQueue<>(capacity);this.limit = limit;}// 其它代码略
}class LeakyBucket {@Autowiredprivate RedisLimitUtil redisLimitUtil;private Map<String, LeakyBucketHolding> leakyBucketHoldingMap = new HashMap();// 添加数据到桶中public boolean addData(Data data) {String key = buildKey(data);LeakyBucketHolding holding = leakyBucketHoldingMap.get(key);if (null == holding) {holding = buildHolding(data);leakyBucketHoldingMap.put(key, holding);}return holding.getLinkedBlockingQueue().offer(data);}public Data getData() {for(LeakyBucketHolding holding : leakyBucketHoldingMap.values()) {if(holding.getBucket().size() == 0) {return null;}/* RedisLimitUtil的实现参考* "精确掌控并发:固定时间窗口算法在分布式环境下并发流量控制的设计与实现"中的示例代码*/boolean limited = RedisLimitUtil.isLimited(holding.getBizType(), holding.getLimit());if (limited) {return null;}try {return holding.getBucket().poll(10, TimeUnit.MILLISECONDS);} catch (InterruptedException e) {log.log("Leaking process interrupted");}return null;}}
}上面的代码只是写一个示例,也没有做方法的抽取,真实的代码会比这个写得更优雅一点,大家将就看一下,理解思路就行。
代码使用的是内存列队,也就是请求过来后,先保存到DB,然后发到内存队列。在重启服务器时,内存列队的数据会丢失,这种情况下,依赖定时任务从DB中恢复任务到内存列队。
还有一种做法,就不使用内存队列,而是使用redis来实现队列。代码如下:
public class LeakyBucket {// 其它代码略... ...// 添加数据到队列中public void addData(Data data) {return redisTemplate.rpush(data.getBizType(), data);}// 添加数据到队列中public Data getData(String bizType) {return redisTemplate.lpop(bizType);}// 其它代码略... ...
}
退款流量控制实例:RefundServiceImpl
/*** 支付服务示例*/
public class RefundServiceImpl implements RefudnService {@Autowireadprivate LeakyBucket leakyBucket;@Overridepublic RefundOrder refund(RefundRequest request) {// 前置业务处理... ...Data data = buildData(request);leakyBucket.addData(data);// 其它业务处理... ...}@PostConstructpublic void init() {new Thread(() -> {while (true) {Data data = leakyBucket.getData();if (null != data) {process(data);} else {sleep(10);}}}).start();}
}在代码中可以看到,退款请求来后,只需要往桶里扔就完事。然后等另外的线程按固定速度发出去。
代码中还存在的问题:
- 上述代码只是示例,真实的代码还有很多异常处理,比如队列数据丢失,需要重新处理。
- 暂时只能用于退款,因为退款的时效要求不高。另外,单机只需要开一个线程就行,因为服务器是分布式部署,多个服务器合并起来仍然是多个线程在并发处理。对退款是足够的。
5. 为什么不使用消息中间件来做队列
为什么不直接使用RabbitMQ或Kafaka等消息中间件来做队列?主要是因为有些公司使用自码的消息中间件,可能只有推模型而没有拉的模式。
如果只有推的模式,就会出现推下来后发现限流,又抛回来,来回做无用功。
如果消息中间件有拉的模式,同时配合redis的固定窗口实现,也是完全没有问题的。
6. 为什么不直接使用消息中间件来做流控
消息中间件是另外的选型方案,会在后面的文章中介绍。
7. 结束语
今天主要介绍了漏桶原理、在支付系统中的使用场景,以及基于redis实现的核心代码。
下一篇将介绍令牌桶在分布式场景下流量控制的应用和核心代码实现。
8. 精选
专栏地址:百图解码支付系统设计与实现
《百图解码支付系统设计与实现》专栏介绍
《百图解码支付系统设计与实现》专栏大纲及文章链接汇总(进度更新于2023.1.15)
领域相关(部分):
支付行业黑话:支付系统必知术语一网打尽
跟着图走,学支付:在线支付系统设计的图解教程
图解收单平台:打造商户收款的高效之道
图解结算平台:准确高效给商户结款
图解收银台:支付系统承上启下的关键应用
图解支付引擎:资产流动的枢纽
图解渠道网关:不只是对接渠道的接口(一)
技术专题(部分):
交易流水号的艺术:掌握支付系统的业务ID生成指南
揭密支付安全:为什么你的交易无法被篡改
金融密语:揭秘支付系统的加解密艺术
支付系统日志设计完全指南:构建高效监控和问题排查体系的关键基石
避免重复扣款:分布式支付系统的幂等性原理与实践
支付系统的心脏:简洁而精妙的状态机设计与核心代码实现
精确掌控并发:固定时间窗口算法在分布式环境下并发流量控制的设计与实现
精确掌控并发:滑动时间窗口算法在分布式环境下并发流量控制的设计与实现
这篇关于精确掌控并发:漏桶算法在分布式环境下并发流量控制的设计与实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







