本文主要是介绍疫情分析(5)再改进的SEIR病毒模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上次我们针对武汉当时的情况进行了预测,本次我们将针对本次上海爆发的大规模疫情进行数据分析和预测。首先我们需要对SEIR模型进行改造。
对于SEIR普通模型不同的地方,本次新冠疫情即使是普通无症状感染者也就是潜伏携带者具有病毒的传染能力,而无症状感染者可以直接变成治愈者。
一:病毒模型的改进
为了更贴合新冠的真实转播模型,我们对之前的SEIR模型进行改进:
1: 添加潜伏者的传染因子
2:添加潜伏者的变成治愈者的因子
3:因为考虑到有个别案例二次感染新冠,所以我们建立参数让治愈者也可能变成易感者。
4:去除迁入,迁出率。因为,本次我们要分析上海疫情对自身的影响,所以我们初构的模型暂时不考虑人口迁徙对本次上海疫情的影响。
改进SEIR模型大致图如下:
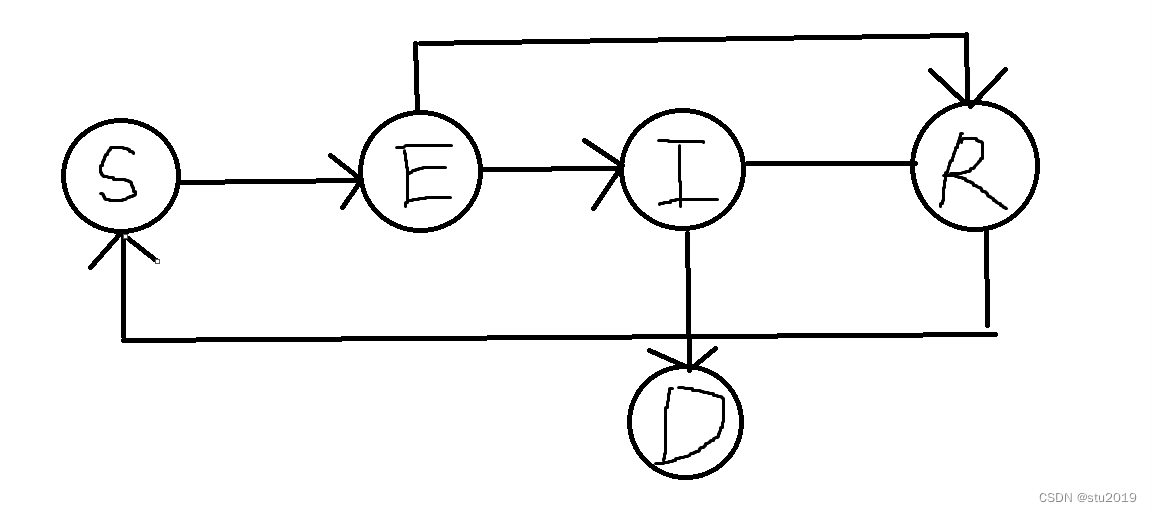
添加的相关参数如下表:
| 符号 | 相关意义 |
| N | 区域总人数 |
| E | 潜伏携带者 |
| I | 感染者 |
| S | 易感者 |
| R | 治愈者 |
| D | D者 |
| r1 | 感染者接触人数 |
| b1 | 感染者传染概率 |
| r2 | 潜伏者接触人数 |
| b2 | 潜伏者传染概率 |
| a | 潜伏者发病率 |
| c | 潜伏者自愈率 |
| y | 治愈率 |
| k | d率 |
| h | 治愈者变易感者率 |
二:参数值的估计
这里的感染者指的是出现症状的人群,所以我们假设他们行动受限。所以平均能接触的人少也相应的下降。
(1)自愈率的估计:
自愈率主要是由无症状感染者的比例(因为无症状感染存在一直无症状还有后期转病的人群):
我的自己思考的估计方法是(不保证准确性),通过网上我们可以得知无症状感染者自愈周期一般是3到5天内,而普通的治疗周期是15到20天。所以我们假设只有无症状感染者能够自愈,并且按一定比例自愈。
1:无症状感染者的占总的85%
2:设无症状感染者自愈比例为a
3:设无症状转病后治愈周期也是15到20天,而自愈周期是3到5天
4:我们取连续五天的数据,其中取前三天无症状和确诊总的增加的数量(这些新增病例有3-5天的自愈周期);用最后一天和第一天的总治愈数据相减得到总治愈数(总治愈数由两部分构成:这5天内无症状者自愈的人数和上一个治疗周期非自愈者的治愈数),再减去一个周期之前的非自愈病例的治愈数。(非自愈的比例为1-a,用15-20天之前的总新增数量*0.85*(1-a))得到无症状的自愈数量(关于a的函数)。最后用无症状自愈数/总增加的数量解关于a的方程就可以得到自愈比5例a的大小。
5:我们取n个(尽理大)的5个连续区间,计算它们a值的大小,最后取平均,就可以得到我们要的参数自愈数的估计了。
6:我模拟了从2月份上海疫情爆发初期到目前5月末的n个数据进行测试:进过测试我发现我自己思考的模型在疫情爆发之处拟合的结果还可以,但到越后面拟合程度越低。(因为爆发初期的治愈周期的不同可能影响程度不大,等到一段时间后治愈周期的影响就会对结果产生严重后果)
最终得到结果:自愈率c大约是0.02
(2)治愈者变成易感者的概率:
这个数据不好自己模拟,只能去相关研究机构找到相关数据。
附上我查阅到的研究报告:
晚讯 | 感染奥密克戎或无法形成免疫 二次感染率高|奥密克戎|感染率|晚讯|免疫|二次|病例|毒株|新冠|疫情|香港|确诊|-健康界
h值大约是:2%
(3)接触人数:平均每人每天接触20人左右。我们设感染者因为身体原因行动不便,所以每人每天接触人数少一半为10人。
(4)传染率:
由于之前模拟的是自然情况下covid-19的传染率,现在面对的是奥米克荣的情况,所以不能直接使用其相关参数,查阅相关资料可知,我们的疫苗对奥米克荣的传染影响不大,主要是针对严重性的影响,所以我们可以直接使用网上的传染率进行计算。查阅相关资料可知,奥米克荣R值大约是2,所以我们用平均接触人数20除2,可得传染率为0.1。
(5)发病率:为奥米克荣潜伏周期的倒数,奥米克荣潜伏期为3-5天,我们这里就取1/5。
(6)治愈率:为治愈周期的倒数:奥米克荣治愈周期为15到20天,我们这里就取1/15。
(7):死亡率:
这个数据很重要,因为我们之后要针对疫苗对奥米克荣的影响进行分析,所以我们不能直接使用上海疫情的相关数据。为了找到没有在疫苗的影响下的相关数据,我们发现朝鲜全国是全国都没有接种过任何一次疫苗的,而且5月初朝鲜发现了奥米克荣,并且大规模传播,所以我们直接使用朝鲜的数据。
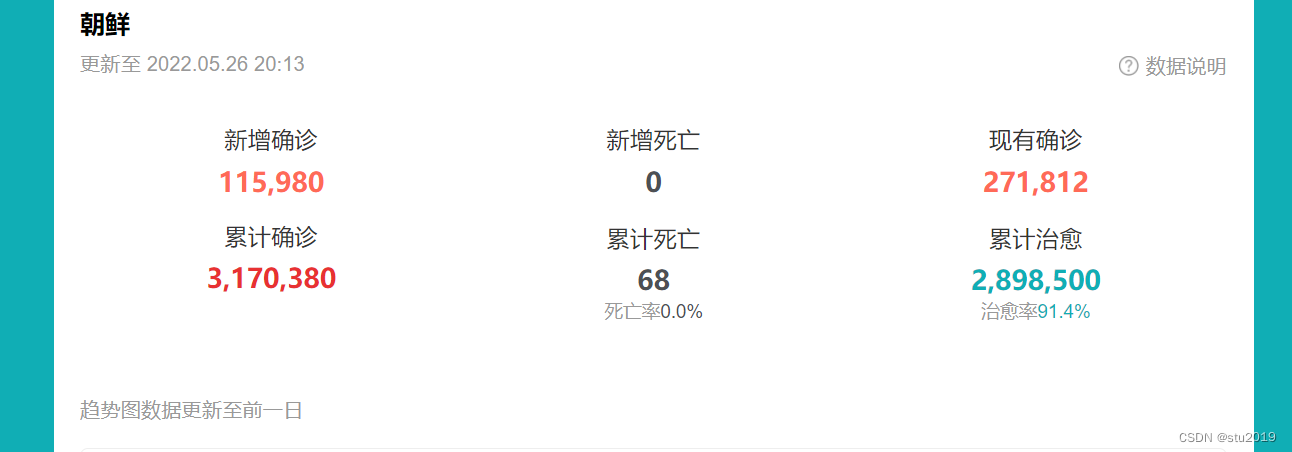
死亡率公式:1-(累计治愈人数/(总确诊数-现有确诊数量))=1-(2898500/(3170380-271812))=0.000025
转移公式的推导:
dS/dt = −r1b1IS / N - r2b2ES / N + hR
dE/dt = r1b1IS / N + r2b2ES / N − aE - cE
dI/dt = aE − yI - kI
dR/dt = yI + cE - hR
dD/dt = kI
模型的建立:
关键代码:
self.S.append(self.S[i] - self.r1 * self.b1 * self.S[i] * self.I[i] / self.N - self.r2 * self.b2 * self.S[i] * self.E[i] / self.N + self.h*self.R[i])self.E.append(self.E[i] + self.r1 * self.b1 * self.S[i] * self.I[i] / self.N - self.a * self.E[i] + self.r2 * self.b2 * self.S[i] * self.E[i] / self.N - self.c*self.E[i])self.I.append(self.I[i] + self.a * self.E[i] - self.g * self.I[i] - self.d*self.I[i])self.R.append(self.R[i] + self.g * self.I[i] + self.c*self.E[i] - self.h*self.R[i])self.D.append(self.D[i] + self.d*self.I[i])for i in range(20, length):leiq = 0leiw = 0for t in range(6):leiq = leiq + que[i-20+t]leiw = leiw + wzz[i-20+t]cue_i = cue[i+5] - cue[i]curr = wzz[i]+wzz[i+1]+wzz[i+2]a = solve([cue_i-leiq-leiw*(1-x)-x*curr], [x])result.append(solve([cue_i-leiq-leiw*(1-x)-x*curr], [x])[x])i = i+5
print(sum(result)/len(result))结果:
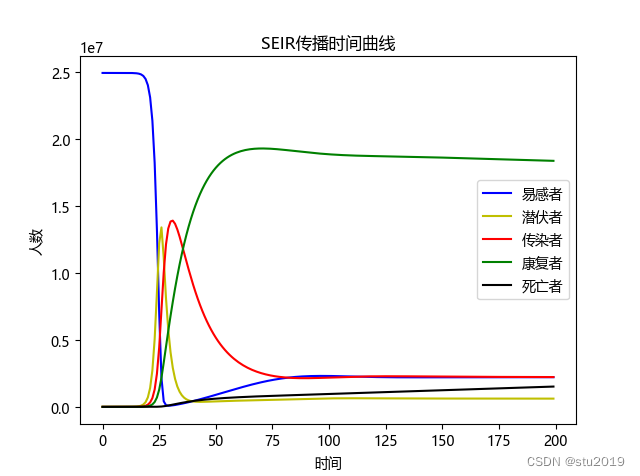
改进:
因为我们的模型是直接让治愈者以h的概率变成易感者,这点是有些不符合实情,因为查阅资料奥密克戎好了以后还会复发吗-乐哈健康网
普通感染者300天内基本不会再次感染,所以我们去掉h(多次感染的参数)再次进行函数拟合。
转移公式的推导:
dS/dt = −r1b1IS / N - r2b2ES / N
dE/dt = r1b1IS / N + r2b2ES / N − aE - cE
dI/dt = aE − yI - kI
dR/dt = yI + cE
dD/dt = kI
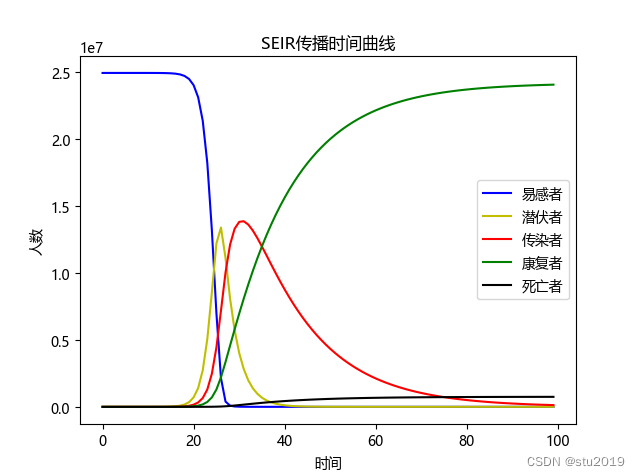
关键代码:
for i in range(0, len(self.T) - 1):self.S.append(self.S[i] - self.r1 * self.b1 * self.S[i] * self.I[i] / self.N - self.r2 * self.b2 * self.S[i] * self.E[i] / self.N)self.E.append(self.E[i] + self.r1 * self.b1 * self.S[i] * self.I[i] / self.N - self.a * self.E[i] + self.r2 * self.b2 * self.S[i] * self.E[i] / self.N - self.c*self.E[i])self.I.append(self.I[i] + self.a * self.E[i] - self.g * self.I[i] - self.d*self.I[i])self.R.append(self.R[i] + self.g * self.I[i] + self.c*self.E[i])self.D.append(self.D[i] + self.d*self.I[i])结果:
以下是上海疫情的实际情况:
感染者:
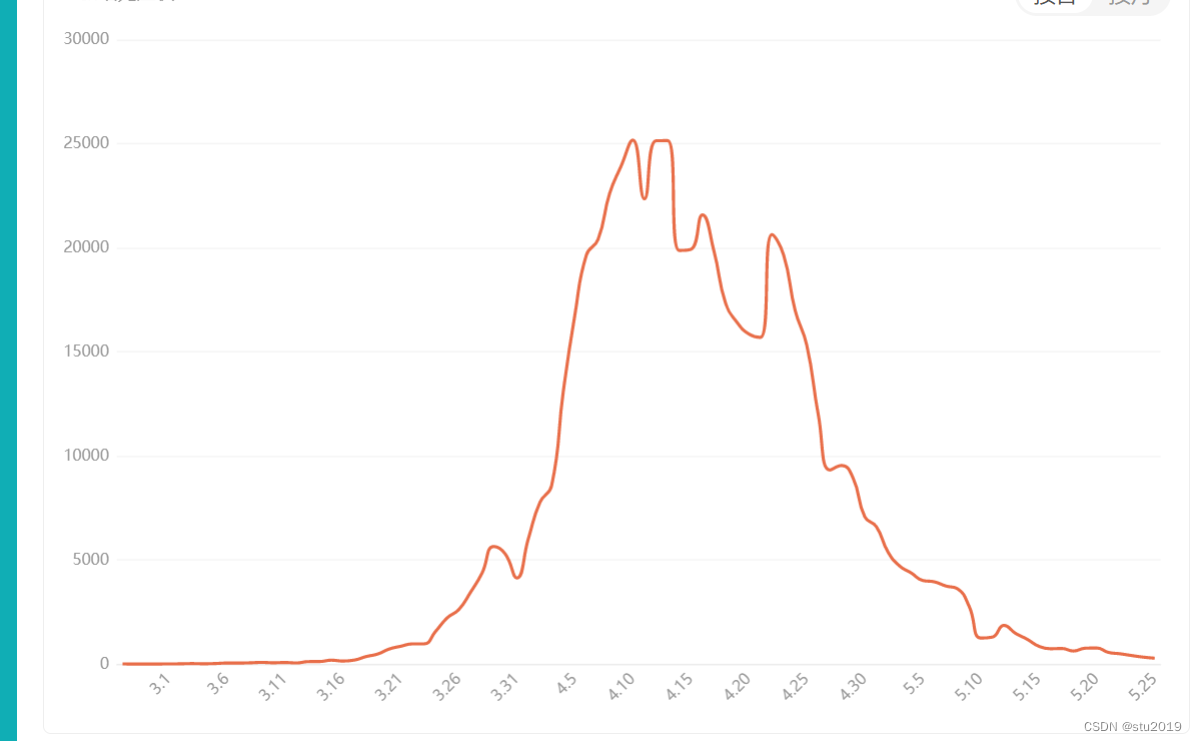
治愈者和死亡者: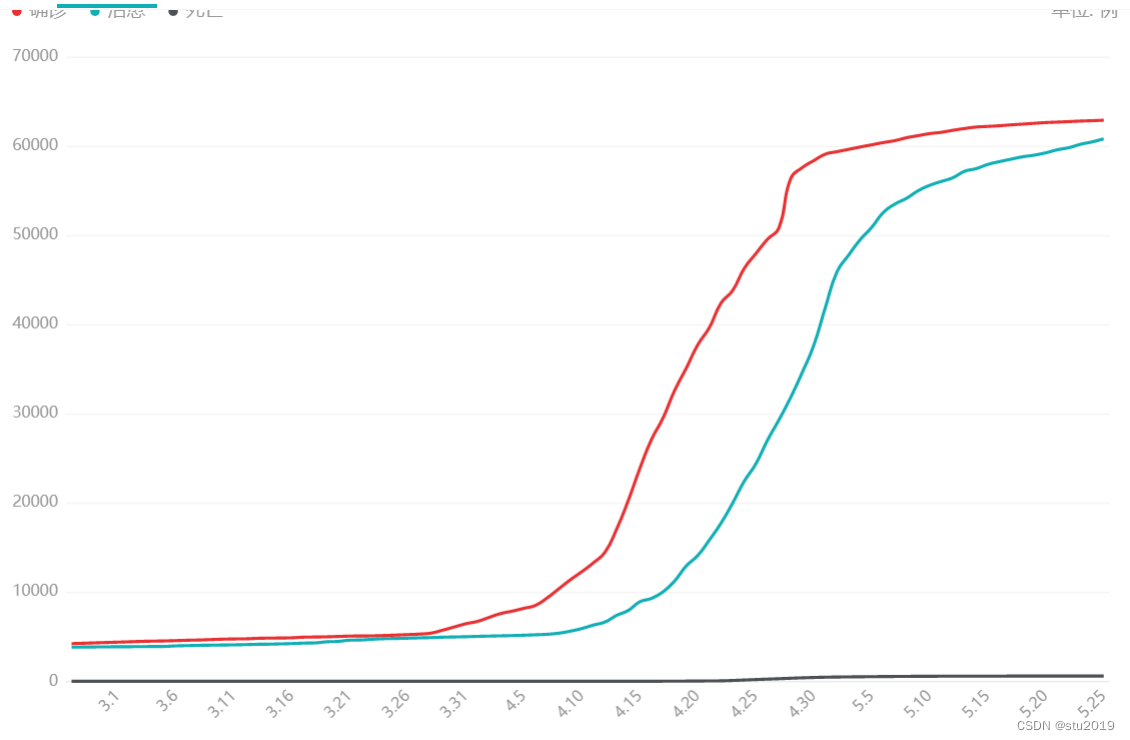
可以对比我们的预测图:
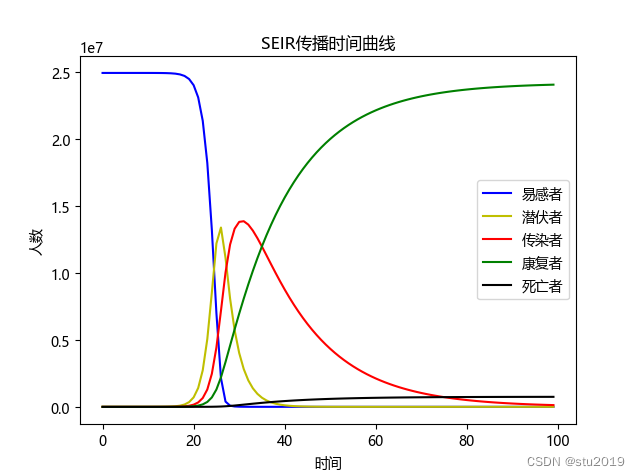
可以发现,疫情的趋势基本上是相当吻合了,但是疫情的人数(确诊,死亡)却大相径庭,这就是隔离和疫苗和戴口罩对疫情防控的作用了。
我们知道病毒传播需要三个关键步骤:1:控制传染源 2:切断传播途径 3:保护易感人群
那么对于这三个途径的防控措施不尽相同,针对本次上海爆发的疫情,接下来我将分情况研究它们对疫情防控产生的影响。再综合考虑它们共同作用下对疫情的影响。
这篇关于疫情分析(5)再改进的SEIR病毒模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






