本文主要是介绍为什么基于树的模型在表格数据任务中比深度学习更优?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文 | Why do tree-based models still outperform deep learning on tabular data?
代码 | https://github.com/LeoGrin/tabular-benchmark
虽然深度学习在计算机视觉、自然语言处理等领域取得了显著的成果,但在处理表格数据任务方面,深度学习模型的表现并不如树模型。大多数从业人员和数据科学竞赛仍然倾向于使用树模型处理表格数据任务。本文通过研究回答了基于树模型(如随机森林)比深度学习表现更好的原因,以帮助我们了解为什么会出现这种情况,以及如何利用这些经验为我们的任务选择最适合的算法。
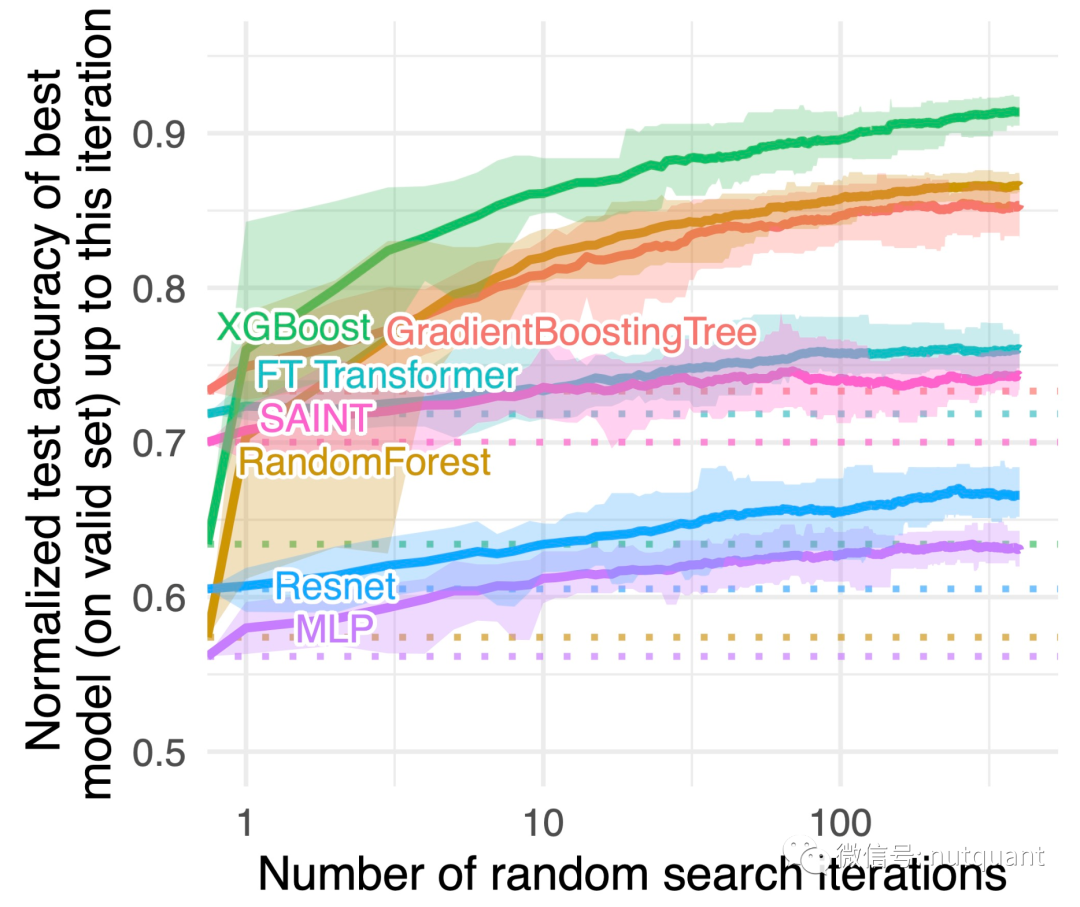
问 :为什么在表格数据任务中基于树的模型优于深度学习?
原因1 :神经网络偏向输出过于平滑的解
简单来说,神经网络很难创建最佳拟合函数,特别是对于非平滑函数或决策边界时,而随机森林在处理奇怪、不规则或锯齿状模式时表现更好。这可能是由于神经网络使用了梯度反向传播进行参数更新。梯度依赖于可微分的参数空间,而这些空间的定义是平滑的。而尖锐、断裂和随机的函数通常是不可微分的。
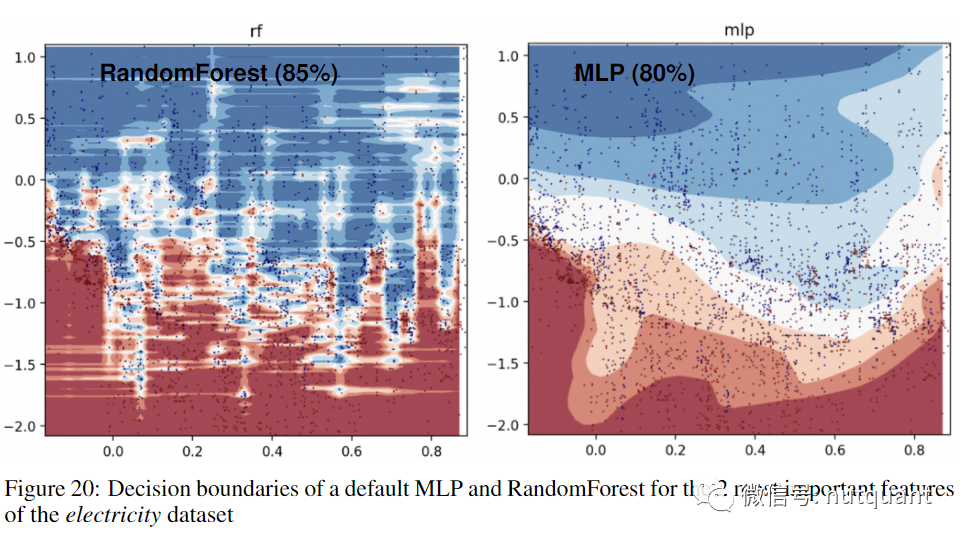
下图清楚地展示了基于树的方法(随机森林)和深度学习器之间的决策边界差异。可以看到,随机森林能够在x轴(对应日期特征)上学习到MLP无法学习到的不规则模式。
原因2 :无信息特征对神经网络影响更大
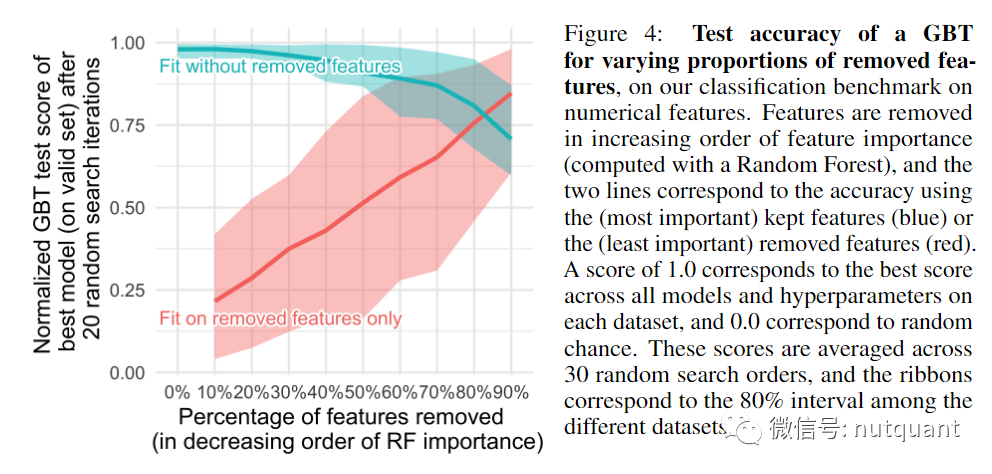
另一个非常重要的因素是特征的质量。如果将无关的特征输入神经网络,结果会非常糟糕(而且会浪费更多的资源来训练模型)。表格数据集包含许多无用信息特征。对于每个数据集,我们根据特征重要性(由随机森林排名)逐渐删除越来越多的特征。
下图4显示,去除高达一半的特征对GBT的分类准确性影响不大。此外,对于已删除特征的GBT进行测试的准确性(即低于某个特征重要性阈值的特征)在删除高达20%的特征时非常低,直到50%时才相当低,这表明大多数这些特征是无信息的,而不仅仅是冗余的。
使用MLP的神经网络架构对无信息特征不够稳健。在下图5中展示的两个实验中,我们可以看到去除无信息特征(5a)减少了MLPs(Resnet)和其他模型(FT Transformers和基于树的模型)之间的性能差距,而添加无信息特征(5b)则扩大了这种差距。
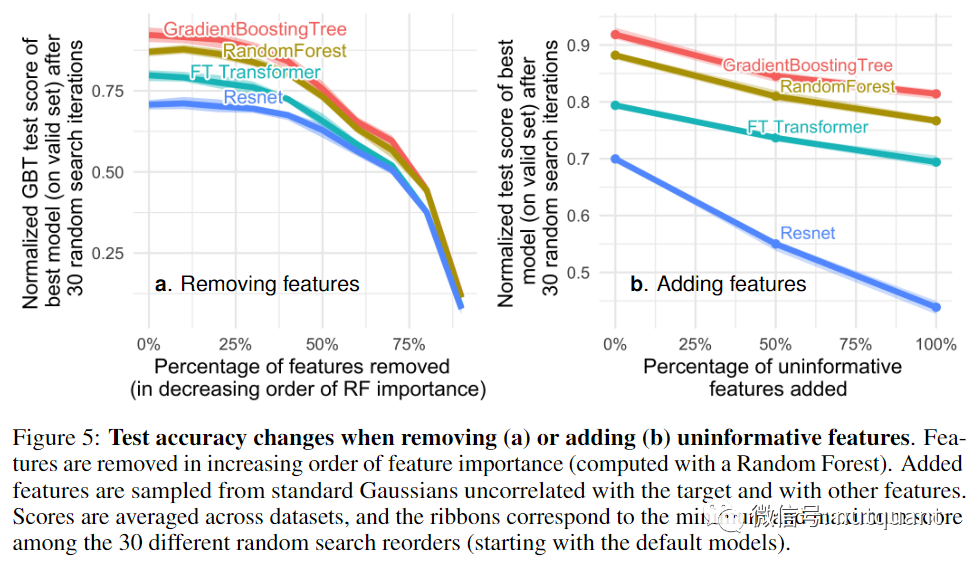
上述实验证明,删除无信息特征对于MLP模型的帮助更大,因此这些特征的减少可以抵消由于删除信息性特征而导致的准确性降低。
原因 3 :神经网络对特征的旋转具有不变性,但是表格数据通常不具备旋转不变性
特征的旋转不变性指的是,当数据发生旋转时,特征的值不发生改变。在图像识别中,例如边缘检测算子Sobel算子,它可以检测出图像中的边缘,而且在图像旋转的情况下,边缘的位置和方向可能会发生变化,但是Sobel算子检测到的边缘的强度和位置不会发生改变。
神经网络具有旋转不变性是因为它们的学习过程不依赖于特征的方向。当应用旋转矩阵时,神经网络的权重矩阵和输入特征矩阵都会被旋转,但由于神经网络的权重矩阵可以自适应地调整来适应旋转后的特征矩阵,因此神经网络的性能不会受到影响。这种旋转不变性使得神经网络能够在处理图像等数据时表现出色,因为图像的方向可能是任意的,但神经网络能够识别出相同的物体。
表格数据通常不具备旋转不变性。因为表格数据的每个特征都有固定的位置和方向,如果对表格数据进行旋转,特征的位置和方向也会随之改变,从而影响模型的性能。因此,在处理表格数据时,通常需要进行特征工程,将特征转换为具有旋转不变性的形式,例如使用极坐标表示数据。
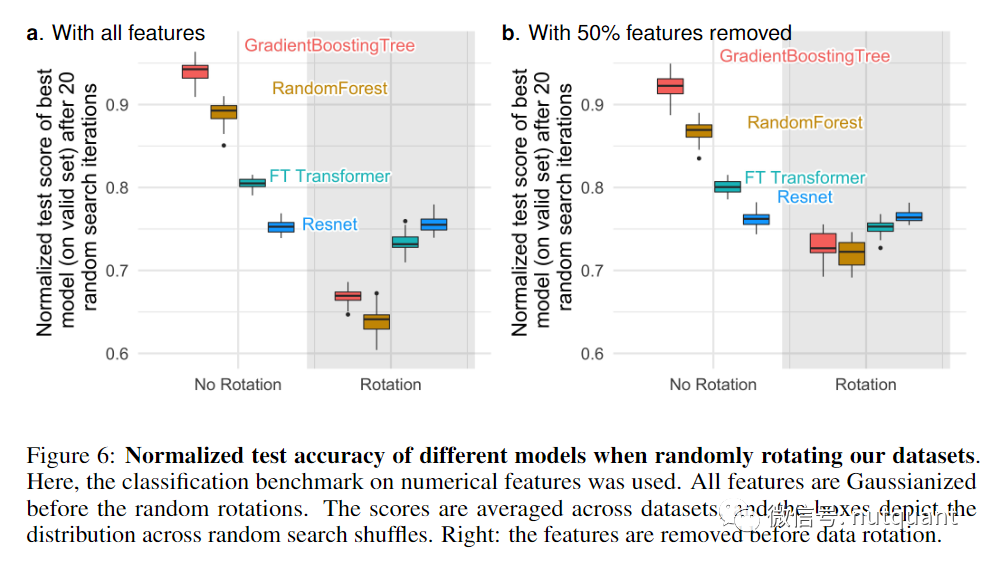
下图6展示了随机旋转数据集时测试准确性的变化,证实只有Resnet具有旋转不变性。而且随机旋转会打乱模型的排序表现,NN模型高于基于树的模型,Resnet模型高于FT Transformer模型。
本文分析了在表格数据任务中基于树的模型优于深度学习的几个可能的原因,包括目标函数中存在不规则模式、无信息特征以及不具有旋转不变性的表格数据。同时,本文还开源了一个测试基准,允许研究人员使用同样的方法和数据集来设计新的架构,并将其与论文的结果进行比较,以促进表格深度学习研究的发展。
TODO:build tabular-specific neural network
这篇关于为什么基于树的模型在表格数据任务中比深度学习更优?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







