本文主要是介绍常用数据无损压缩算法分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
当今,各种信息系统的数据量越来越大,如何更快、更多、更好地传输与存储数据成为数据信息处理的首要问题,而数据压缩技术则是解决这一问题的重要方法。事实上,从压缩软件WINRAR到熟知的MP3,数据压缩技术早已应用于各个领域。
2 数据压缩技术概述
本质上压缩数据是因为数据自身具有冗余性。数据压缩是利用各种算法将数据冗余压缩到最小,并尽可能地减少失真,从而提高传输效率和节约存储空间。
数据压缩技术一般分为有损压缩和无损压缩。无损压缩是指重构压缩数据(还原,解压缩),而重构数据与原来数据完全相同。该方法用于那些要求重构信号与原始 信号完全一致的场合,如文本数据、程序和特殊应用场合的图像数据(如指纹图像、医学图像等)的压缩。这类算法压缩率较低,一般为1/2~1/5。典型的无 损压缩算法有:Shanno-Fano编码、Huffman(哈夫曼)编码、算术编码、游程编码、LZW编码等。而有损压缩是重构使用压缩后的数据,其重 构数据与原来数据有所不同,但不影响原始资料表达信息,而压缩率则要大得多。有损压缩广泛应用于语音、图像和视频的数据压缩。常用的有损压缩算法有 PCM(脉冲编码调制)、预测编码、变换编码(离散余弦变换、小波变换等)、插值和外推(空域亚采样、时域亚采样、自适应)等。新一代的数据压缩算法大多 采用有损压缩,例如矢量量化、子带编码、基于模型的压缩、分形压缩和小波压缩等。
3 常用数据无损压缩算法
3.1 游程编码
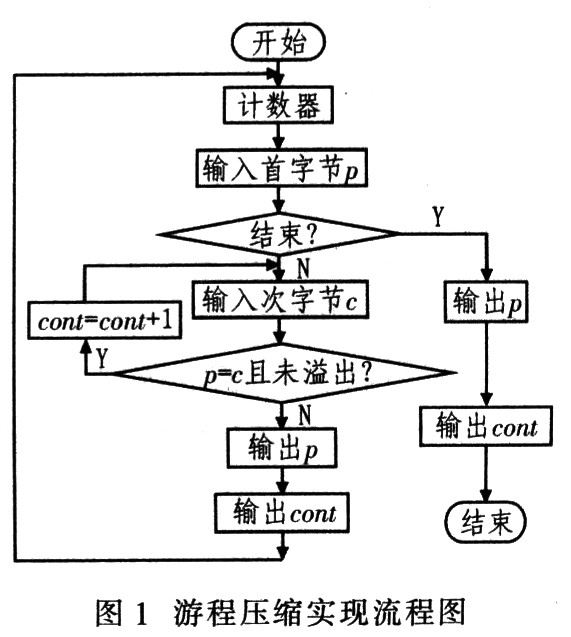
这 种数据压缩思想:如果数据项d在输入流中连续出现n次,则以单个字符对nd来替换连续出现n次的数据项,这n个连续出现的数据项叫游程n,这种数据压缩方 法称游程编码(RLE),其实现流程如图1所示。RLE算法具有实现简单,压缩还原速度快等优点,只需扫描一次原始数据即可完成数据压缩。其缺点是呆板, 适应性差,不同的文件格式的压缩率波动大,平均压缩率低。实践表明,RLE能够压缩复杂度不高的原始点阵图像。
3.2 基于字典编码技术的LZW算法
LZW 算法是LZ78的流行变形,由Terrv Welch在1984年开发。LZW算法首先将字母表中的所有字符初始化到字典,常用8位字符,在输入任何数据前优先占用字典的前256项 (0~255)。LZW编码的原理:编码器逐个输入字符并累积一个字符串I。每输入一个字符则串接在I后面,然后在字典中查找I;只要找到I,该过程继续 执行搜索。直到在某一点,添加下一个字符x导致搜索失败,这意味着字符串I在字典中,而Ix(字符x串接在I后)却不在。此时编码器输出指向字符串,的字 典指针;并在下一个可用的字典词条中存储字符串Ix;把字符串I预置为x。其压缩流程如图2所示。
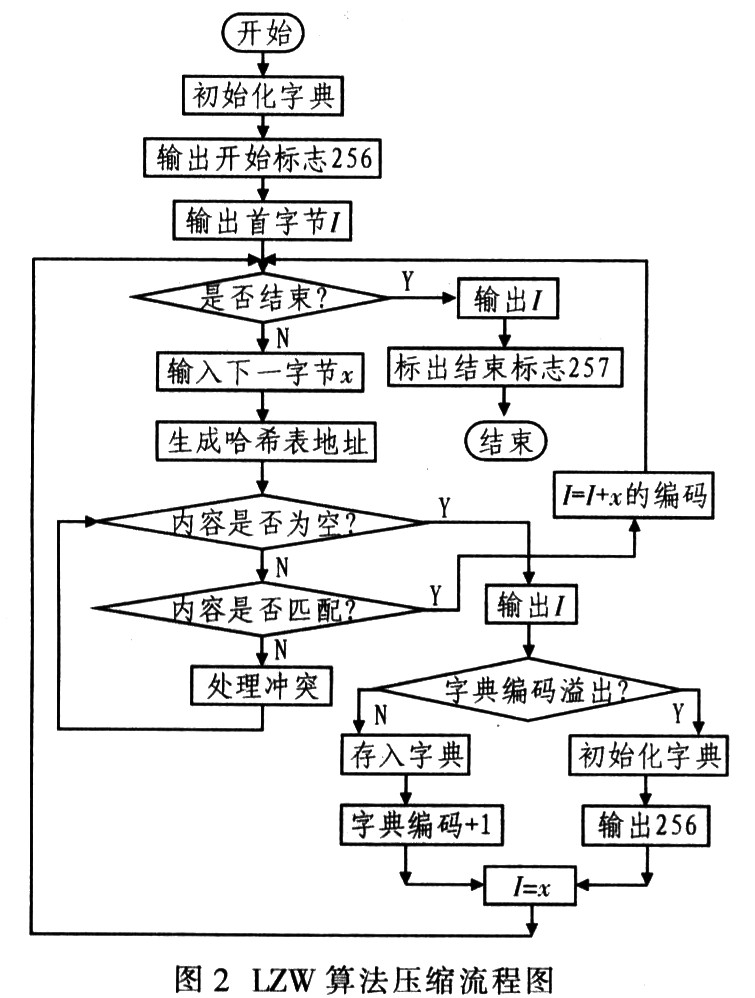
因为字典的前256项被占用,因此字典指针必须高于8位。由于LZW算法的字典中的字符串每次仅增加一个字符。因此,要获得长字符串则需较长时间,这样才能较好地压缩.IZW编码能够适应输入数据。
LZW算法与其他算法相比具有自适应的特点,即可以根据压缩内容不同来建立不同字典,以减少冗余度,提高压缩比;并且解压时这个字典无需与压缩代码同时传 送,而是在解压过程中逐步建立与压缩时完全相同的字典,从而完整、准确地恢复被压缩内容。因此,LZW算法是一种解码速度与压缩性能较好的压缩算法。
实现LZW算法需要考虑以下几点:
(1)字典建立(数据结构与字典大小) LZW字典的数据结构是一棵多叉树。字典越大,代替的子串越多。但应用中字典容量则受一定限制,要权衡利弊选择合适的字典。
(2)字典维护与更新 字典指针由哈希函数生成。正确选择哈希函数非常重要,这将影响执行效率。正确的哈希函数所产生的重复值极少,这样检索字符串所需比较次数也较少,从而可有效提高代码的执行效率。
当字典满时,字典的维护和更新对压缩率也是至关重要的。可重新从初始状态建立字典;也可监测压缩率,当压缩率变坏时全部或部分清除字典。
(3)压缩数据代码长度 压缩时,输入数据一般是8位。但压缩后的输出是转化的字符串代码,其中0~255为8位码,256为9位码,25l~512为10位码,l 024为11位码。解压则相反,需要位操作。因此,输出可以从9位码开始,随着字典内容的增加,码字也逐渐增加。这样可提高执行效率,但在译码时需考虑不 等长码的识别,可通过设置标志位来解决。
3.3 基于哈夫曼编码原理的压缩算法
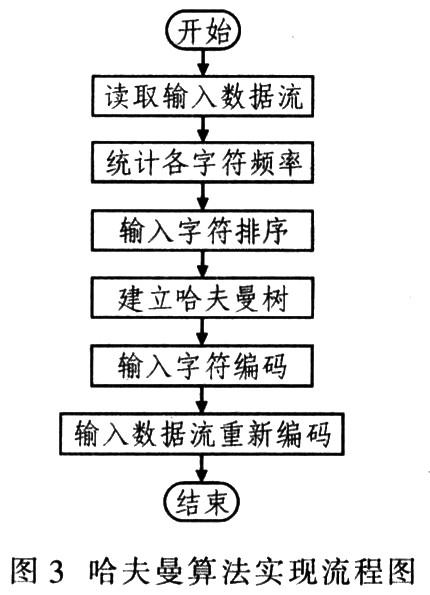
哈夫曼算法的过程为:统计原始数据中各字符出现的频率;所有字符按频率降序排列;建立哈夫曼树:将哈夫曼树存入结果数据;重新编码原始数据到结果数据。哈夫曼算法实现流程如图3所示。
哈夫曼算法的实质是针对统计结果对字符本身重新编码,而不是对重复字符或重复子串编码。实用中.符号的出现频率不能预知,需要统计和编码两次处理,所以速 度较慢,无法实用。而自适应(或动态)哈夫曼算法取消了统计,可在压缩数据时动态调整哈夫曼树,这样可提高速度。因此,哈夫曼编码效率高,运算速度快,实 现方式灵活。
采用哈夫曼编码时需注意的问题:
(1)哈夫曼码无错误保护功能,译码时,码串若无错就能正确译码;若码串有错应考虑增加编码,提高可靠性。
(2)哈夫曼码是可变长度码,因此很难随意查找或调用压缩文件中间的内容,然后再译码,这就需要在存储代码之前加以考虑。
(3)哈夫曼树的实现和更新方法对设计非常关键。
3.4 基于算术编码的压缩算法
算术编码压缩也是一种根据字符出现概率重新编码的压缩方案。该思想和哈夫曼编码有些相似,但哈夫曼编码的每个字符需用整数个位表示。而算术编码方法则无这一限制,它是将输入流视为整体进行编码。虽然算术编码压缩率高.但运算复杂,速度慢。
4 结语
游 程编码和LZW编码属于基于字典模型的压缩算法,而哈夫曼编码和算术编码属于基于统计模型的压缩算法,前者与原始数据的排列次序有关而与其出现频率无关, 后者则正好相反。这两类压缩方法算法思想各有所长,相互补充。许多压缩软件结合了这两类算法。例如WINRAR就采用了字典编码和哈夫曼编码算法。这几种 数据无损压缩算法应用广泛,设计人员可以根据具体应用中的数据流特点来改进算法从而开发适用的软硬件压缩器。
这篇关于常用数据无损压缩算法分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





