本文主要是介绍乘骐骥以驰骋兮,来吾道夫先路——2023年大模型技术基础架构盘点与开源工作速览,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一、模型基本架构
- 1.1、自回归(Autoregressive)模型架构
- 1.2、自编码(Autoencoder)模型架构
- 1.3、完整的编码-解码模型架构
- 二、典型开源工作速览
- 2.1、LLaMA-2
- 2.2、baichuan-2
- 2.3、Falcon
- 2.4、BLOOM
- 最后
在过去的一年里,大模型技术在人工智能领域取得了巨大的进展和突破,成为业界瞩目的焦点。从优化的学习算法到激动人心的应用案例,从推动科研的新边界到开拓商业的新天地,大模型技术的跃进式发展,俨然成为推动行业革新、塑造未来商业竞争力的核心动力,为各行各业带来了前所未有的机遇和挑战。
“乘骐骥以驰骋兮,来吾道夫先路”,转眼间,2023年已结束,在这里,从2023年的技术盘点中抽丝剥茧,领略一些至关重要的大模型技术架构盘点与重要开源工作。
一、模型基本架构
在模型架构方面,国内外的大模型普遍为Transformer架构。Transformer的整体主要分为Encoder和Decoder两大部分。
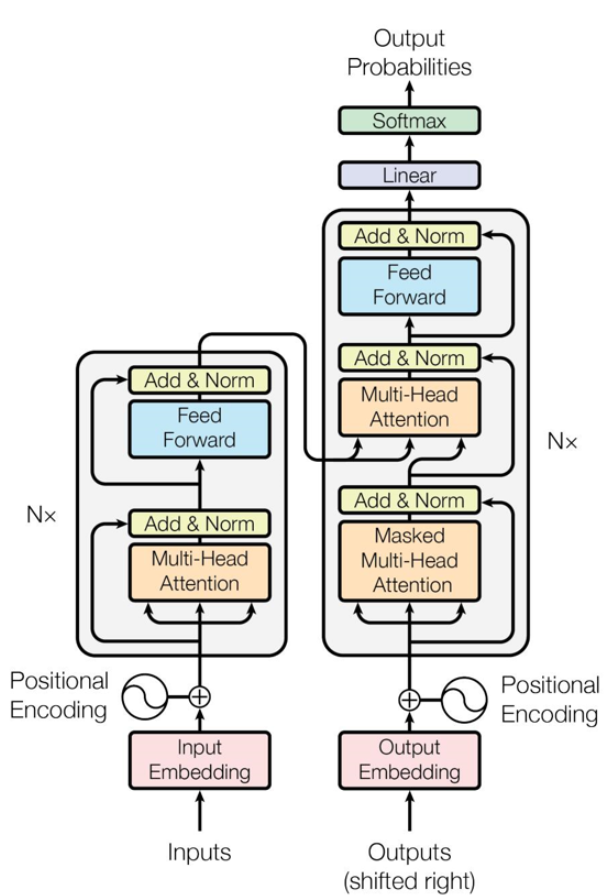
输入的序列首先变成计算机便于处理的Embedding,然后Embedding传入Encoder进行编码,映射成隐藏层特征,经过Encoder后再结合上一次的output输入到Decoder中,最后用softmax计算序列下一个单词的概率。
模型的基座设计大体上可以分为以下三种:
- 仅包含解码器(Decoder-only)- 自回归(Autoregressive)模型
- 仅包含编码器(Encoder-only),即自编码(Autoencoder)模型
- 编码器—解码器(Encoder-Decoder),即完整的Transformer结构
1.1、自回归(Autoregressive)模型架构
这种架构仅包含解码器部分,没有编码器。代表模型是GPT和LLaMA,其训练目标是从左到右的文本生成,AR模型从一系列time steps中学习,并将上一步的结果作为回归模型的输入,以预测下一个time step的值,在这种结构中,模型通过自回归的方式逐步生成输出序列的每个元素。每个输出元素的生成依赖于先前生成的元素,在长文本的生成能力很强,擅长于摘要生成、翻译、对话生成、故事生成等。
1.2、自编码(Autoencoder)模型架构
这种模型仅包含编码器部分,没有解码器。代表模型是BERT、ALBERT 、DeBERTa,自编码模型是通过去噪任务(如利用掩码语言模型)学习双向的上下文编码器,其目标是通过联合训练来学习双向上下文信息。这种自编码器结构有助于在各种下游任务上获得高效的特征表示,常用于自然语言理解,如情感分析、提取式问答。
1.3、完整的编码-解码模型架构
最通用的Transformer结构,同时包含编码器和解码器。代表模型是T5、BART和BigBird适用于序列到序列的任务,如机器翻译。编码器负责将输入序列编码成一个上下文表示,解码器则使用这个表示逐步生成输出序列。这种结构在翻译等任务中表现良好,同时也可以应用于其他序列生成任务。
| 架构 | 优点 | 代表作品 |
|---|---|---|
| 自回归模型架构 | 生成过程天然自回归,适用于生成任务,如文本生成、语言建模。大部分大模型采用的方法。 | GPT、 LLaMA |
| 自编码模型架构 | 能够学习输入数据的紧凑表示,适用于降维、特征提取等任务。易于在下游任务中以无监督或半监督的方式进行微调。 | DeBERTa、MAAL |
| 完整编码-解码模型架构 | 充分利用了上下文信息,能够捕捉输入序列中的长距离依赖关系,具有较强的通用性。 | T5、BART、BigBird |
考虑到训练效率、推理需求和下游实际应用任务,大模型通常采用仅包含解码器的架构,通过自回归预训练高效地生成优质内容。
二、典型开源工作速览
2.1、LLaMA-2
论文地址:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
仓库地址:https://github.com/facebookresearch/llama
简要介绍:
LLaMA-2由Meta AI的GenAI团队开发,开放了两个版本,一个是纯无监督训练出来的基础模型,另一个是在基础模型之上进行有监督微调SFT和人类反馈的强化学习RLHF进行训练的Chat模型。所发布的两个版本中,都提供了7B、13B 和70B的三个参数规模的模型。
训练成本:
2000个A100-80GB,时间从2023年1月到2023年7月
模型效果:
Meta在论文中表示,LLaMA 70B的模型在许多方面都超越了 ChatGPT-3.5的水平。
2.2、baichuan-2
论文地址:https://cdn.baichuan-ai.com/paper/Baichuan2-technical-report.pdf
仓库地址:https://github.com/baichuan-inc/Baichuan2
简要介绍:
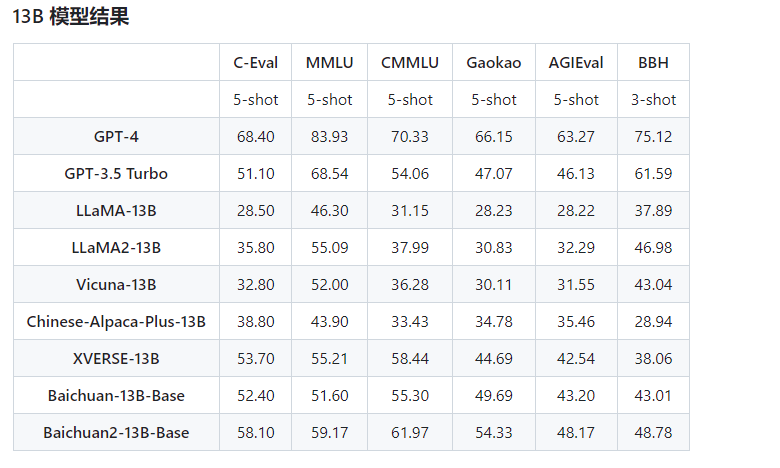
Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练。在多个权威的中文、英文和多语言的通用、领域 benchmark 上取得同尺寸最佳的效果。
训练成本:
1024个NVIDIA A800 GPUs
模型效果:
模型在通用、法律、医疗、数学、代码和多语言翻译六个领域的中英文和多语言权威数据集上对模型进行了广泛测试。同时,Baichuan-2-7B模型还开放了中间的11个 Checkpoints 供社区研究。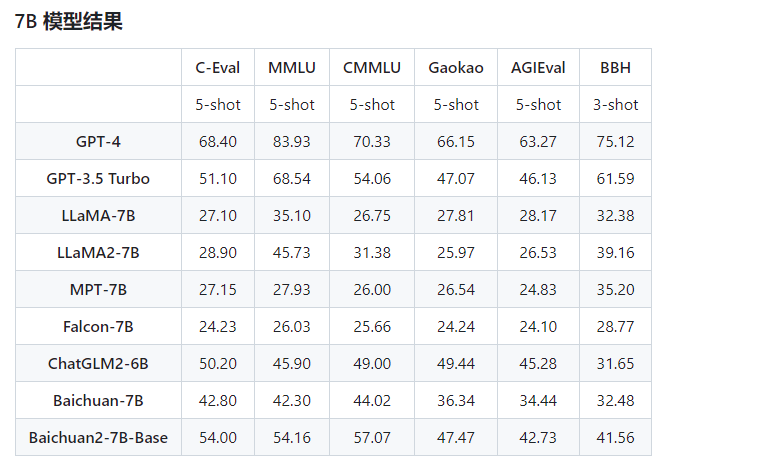
2.3、Falcon
论文地址:https://huggingface.co/blog/zh/falcon-180b
仓库地址:https://huggingface.co/tiiuae/falcon-180B
简要介绍:
Falcon-180B是一个拥有1800亿参数的因果解码器模型(自回归语言模型),由阿布扎比(Abu Dhabi)的技术创新研究院(TII)开发和训练,于2023年9月发布。它是继Falcon-40B之后,TII推出的第二个开源大语言模型(LLM),也是目前世界上最大的开源开放大模型。Falcon-180B的目标是为研究者和商业用户提供一个强大、高效、多语言和多领域的基础模型,可以用于各种自然语言处理(NLP)任务,如文本生成、摘要、问答、对话、机器翻译等。目前开放了两个版本:一个是纯无监督训练出来的基础模型Falcon-180B,另一个是在基础模型之上进行有监督微调SFT和人类反馈的强化学习RLHF进行训练的Chat模型Falcon-180B-chat。
训练成本:
约为 LLaMA-2-70B 的4倍,估计超过8000万美元
模型效果:
Falcon-180B效果上表现很不错,在 MMLU 表现上超越了 LLaMA-2-70B、ChatGPT-3.5;在多个数据集【HellaSwag、LAMBADA、WebQuestions、Winogrande、PIQA、ARC、BoolQ、CB、COPA、RTE、WiC、WSC、ReCoRD 】上与谷歌的 PaLM 2-Large 不相上下。
2.4、BLOOM
论文地址:https://arxiv.org/abs/2211.05100
仓库地址:https://bigscience.huggingface.co/
简要介绍:BLOOM是 BigScience Large Open-science Open-access Mul-tilingual Language Model首字母的缩写。BLOOM本身基于变换器网络(Transformer)架构的自回归语言模型,也是第一个开源开放的超过100B的语言模型。
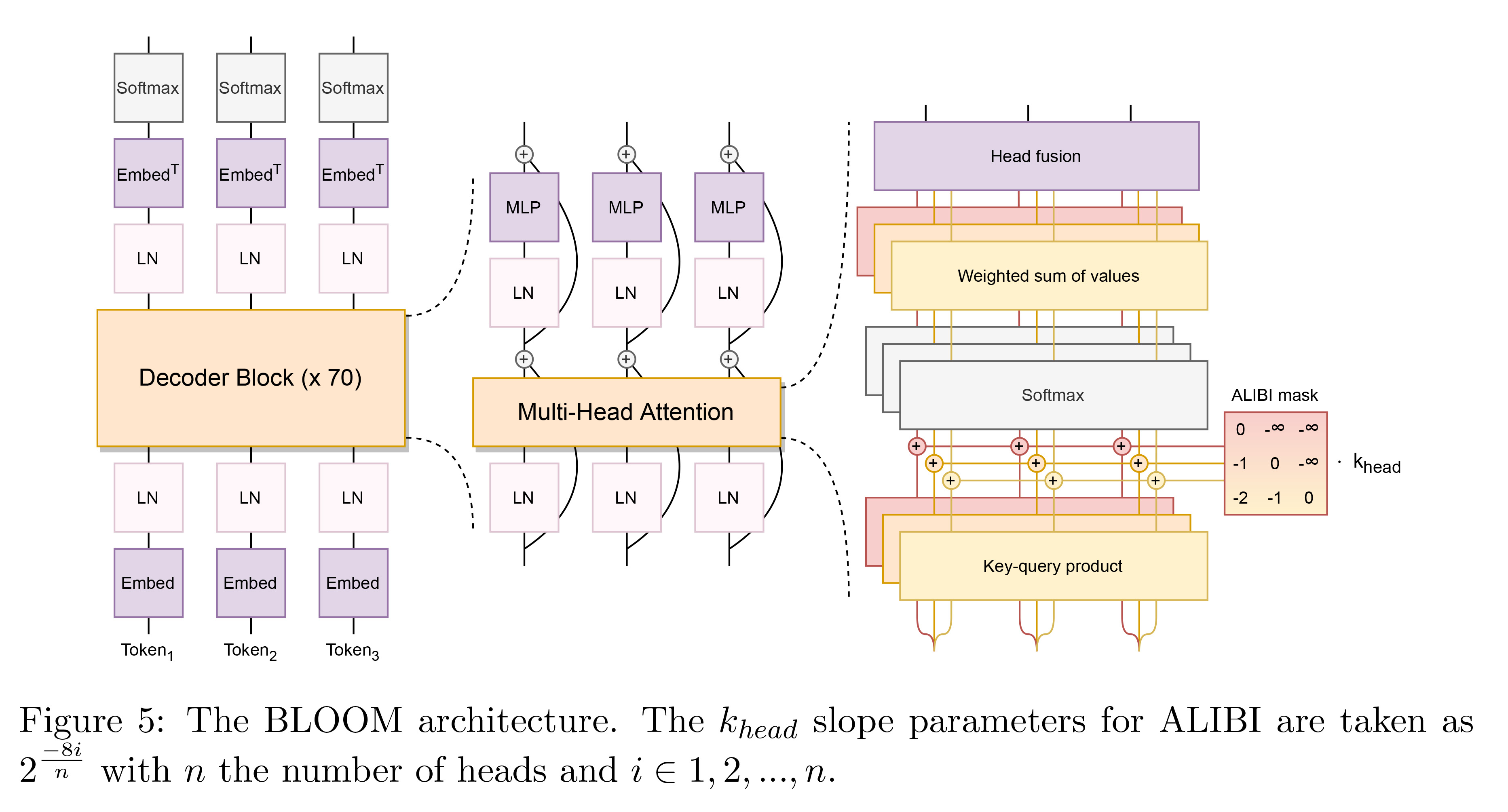
训练成本:
训练时间3.5月,花费1,082,990计算小时。 48个节点,每个节点包括用4个NVLink互联的8块NVIDIA A100 80GB GPUs(应该是一台Nvidia DGX A100或类似的),2x AMD EPYC 7543 32-Core CPUs 和 512GB内存,一共384 A100 GPUs。 训练中预留了4个节点备用,防止训练过程的失效。
模型效果:
模型会学习数十亿个单词和短语之间的统计学关联,然后执行各种任务,包括生成摘要、翻译、回答问题,以及对文本进行分类等等。值得一提的是BLOOM还使用了13种编程语言。
在这个瞬息万变的技术时代,大模型技术不仅仅是一种工具或框架,更是推动科技革命的引擎。
大模型已然推动着人工智能、自然语言处理等领域的快速演进。开源社区的力量汇聚成涌动的江河,推动着技术的不断创新。2024年,期待更多的开源项目涌现,为技术发展注入新的活力。
最后
💖 个人简介:人工智能领域研究生,目前主攻文本生成图像(text to image)方向
📝 个人主页:中杯可乐多加冰
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏⭐️+留言📝
另外,我们已经建立了研学交流群,如果你也是大模型、T2I方面的爱好者或研究者可以私信我加入。
这篇关于乘骐骥以驰骋兮,来吾道夫先路——2023年大模型技术基础架构盘点与开源工作速览的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




