本文主要是介绍多模态大模型Vary:扩充视觉Vocabulary,实现更细粒度的视觉感知,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
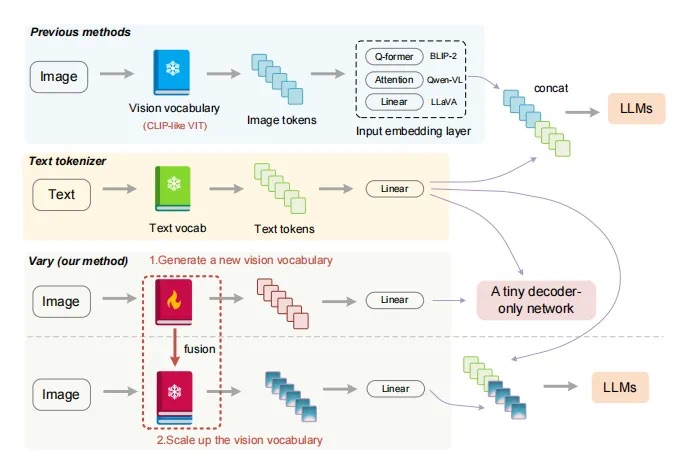
现代大型视觉语言模型(LVLMs)具有相同的视觉词汇- CLIP,它可以涵盖大多数常见的视觉任务。然而,对于一些需要密集和细粒度视觉感知的特殊视觉任务,例如文档级OCR或图表理解,特别是在非英语场景下,clip风格的词汇表在视觉知识的标记化方面可能会遇到效率较低的问题,甚至会出现词汇外问题。
解决方案
在此基础上,本文提出了一种高效、有效的扩展LVLMs视觉词汇量的方法——Vary。Vary的过程分为两部分:新的视觉词汇的生成和整合。
1.第一阶段,设计了一个词汇表网络和一个小型的仅解码器转换器,通过自回归产生所需的词汇表。
2.第二阶段,通过将新的视觉词汇表与原始词汇表(CLIP)合并来扩展vanilla视觉词汇表,为lvlm有效地提供新的特征,使lvlm能够快速获取新特性。
与流行的BLIP-2、MiniGPT4和LLaVA相比,Vary在保持原有功能的同时,具有更出色的细粒度感知和理解能力。具体来说,Vary能够胜任新的文档解析功能(OCR或标记转换),同时在DocVQA中实现78.2%的ANLS,在MMVet中实现36.2%。
Vary方法
一.算法架构
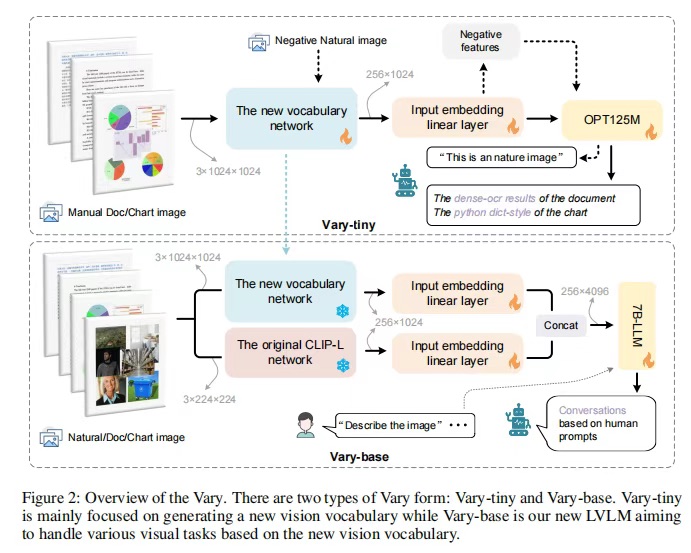
Vary有两种:Vary-tiny和Vary-base,如图2所示。作者设计了Vary-tiny来“书写”新的视觉词汇,而Vary-base则用来使用新的词汇。具体来说,Vary-tiny主要由一个词汇网络和一个微小的OPT-125M组成。在两个模块之间,添加了一个线性层来对齐通道尺寸。在Vary-tiny中没有文本输入分支,因为它主要关注细粒度感知。作者希望新的视觉词汇网络能够在处理人工图像,即文档和图表方面表现出色,以弥补CLIP的不足。同时,作者也期望在对自然图像进行标记时,它不会成为CLIP的噪声。因此,在生成过程中,作者将人工文档和图表数据作为正样本,将自然图像作为负样本来训练Vary-tiny。在完成上述过程后,提取词汇网络并将其添加到一个大型模型中以构建Vary-base。如图2下半部分所示,新旧词汇网络具有独立的输入嵌入层,并在LLM之前进行集成。在此阶段,冻结新旧视觉词汇网络的权值,解冻其他模块的权值。
二、视觉词汇
1.新词汇网络
作者使用SAM预训练的ViTDet图像编码器(基尺度)作为Vary新词汇网络的主要部分。由于SAM-base的输入分辨率为(1024×1024),而输出步幅为16,所以最后一层的特征形状为(H×W×C为64×64×256),无法与CLIP-L的输出(N×C为256×1024)对齐。因此,作者在SAM初始化网络的最后一层后面添加了两个卷积层,这是一个很好的token合并单元,如图3所示。第一个卷积层的核大小为3,目的是将7b - llm特征形状转移到32×32×512。第二个转换层的设置与第一个相同,可以进一步将输出形状转换为16×16×1024。之后,将输出特征平展为256×1024,以对齐CLIP-VIT的图像token形状。
2.生成短语中的数据引擎
Documnet数据 作者选择高分辨率文档图像-文本对作为新视觉词汇预训练的主要正数据集,因为密集OCR可以有效验证模型的细粒度图像感知能力。目前还没有公开的中英文文档数据集,所以作者创建了自己的数据集。首先从arXiv和CC-MAIN-2021-31-PDFUNTRUNCATED上的开放获取文章中收集pdf格式的文档作为英文部分,从互联网上的电子书中收集中文部分。然后使用PyMuPDF的fitz提取每个pdf页面中的文本信息,同时通过pdf2image将每个页面转换为PNG图像。在此过程中,分别构建了1M个中文文档和1M个英文文档图像-文本对进行训练。图表数据 作者发现目前的LVLMs并不擅长图表理解,尤其是中文图表,所以作者选择它作为另一个需要“写”进新词汇表的主要知识。对于图表图像-文本对,遵循渲染方式。选择matplotlib和pyecharts作为渲染工具。对于matplotlib风格的图表,构建了250k的中英文版本。而对于pyecharts,分别为中文和英文创建了50万个pyecharts。此外,作者将每个图表的文本基础真值转换为python- dictionary形式。图表中使用的文本,例如标题、x轴和y轴,是从互联网上下载的自然语言处理(NLP)语料库中随机选择的。
负样本自然图片 对于CLIP-VIT擅长的自然图像数据,需要保证新引入的词汇不会产生噪声。因此,作者构建了负的自然图像-文本对,以使新词汇网络在看到自然图像时能够正确编码。作者从COCO数据集中提取了120k张图像,每张图像对应一个文本。文本部分从以下句子中随机抽取:“It 's a image of nature”;“这是一张自然的照片”;“这是一张自然照片”;“这是一个自然的形象”;“这是大自然的杰作。”
3.输入格式
用图像-文本对对var -tiny的所有参数进行自回归训练。输入格式遵循流行的LVLMs,即图像token以前缀的形式与文本token打包。具体来说,作者使用两个特殊的标记“”和“”来指示图像标记作为插值OPT-125M(4096个标记)的输入的位置。在训练过程中,Vary-tiny的输出仅为文本,并将“”视为eos令牌。
三、扩大视觉词汇
1.Vary-base结构
在完成词汇网络的训练后,作者将其引入到LVLM - Var -base中。具体来说,作者将新的视觉词汇表与原始的CLIP-VIT并行化。这两个视觉词汇表都有一个单独的输入嵌入层,即一个简单的线性。如图2所示,线性的输入通道为1024,输出通道为2048,保证了拼接后的图像token通道为4096,这与LLM (Qwen-7B或Vicuna-7B)的输入完全一致。
2.扩展短语中的数据引擎
LATEX渲染文档 作者认为需要数据具有一定的格式,例如支持公式和表格。为此,作者通过LATEX呈现创建文档数据。首先,在arxiv上收集了一些.tex源文件,然后使用正则表达式提取表、数学公式和纯文本。最后,重新渲染这些内容与用pdflatex准备的新模板。作者收集了10多个模板来执行批处理呈现。此外,将每个文档页面的文本ground truth转换为mathpix markdown样式,以统一格式。通过这个建设过程,作者获得了50万英文页面和40万中文页面。图4显示了一些示例。

使用pdflatex来渲染文档,使用pyecharts/matplotlib来渲染图表。文档数据获取中/英文文本、公式和表格。图表数据包括中/英文条形、线形、饼形和复合样式。
语义关联图呈现 在1.2.2节中,作者批量渲染图表数据来训练新的词汇网络。然而,这些呈现图表中的文本(标题、x轴值和y轴值)相关性较低,因为它们是随机生成的。这个问题在词汇表生成过程中不是问题,作者只希望新的词汇表能够有效地压缩视觉信息。但是在Vary-base的训练阶段,由于LLM的解冻,希望使用更高质量(强相关内容)的数据进行训练。因此,作者使用GPT-4使用相关语料库生成一些图表,然后利用高质量语料库添加渲染200k图表数据进行Vary-base训练。一般数据 训练Vary-base的过程遵循流行的LVLMs,例如LLaVA,包括预训练和SFT阶段。与LLaVA不同的是,作者冻结了所有的词汇网络,并解冻了输入嵌入层和LLM,这更像是一个纯LLM的预训练设置。作者使用自然的图像-文本对数据向vary库引入一般概念。图像-文本对从LAION-COCO中随机抽取,数量为400万。在SFT阶段,使用LLaVA-80k或LLaVA-CC665k以及DocVQA和ChartQA的训练集作为微调数据集。
实验结果
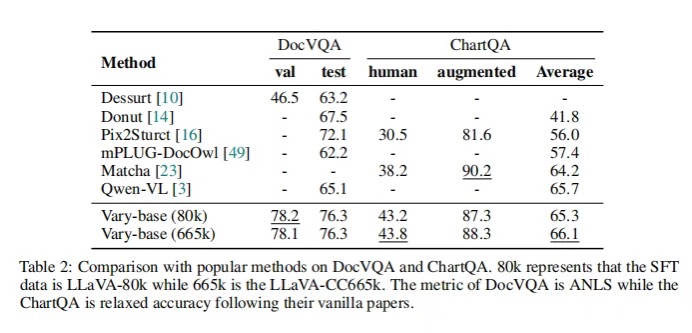
如表2所示,在llva -80k SFT数据上,Vary-base(以Qwen-7B为LLM)在DocVQA上可以实现78.2% (test)和76.3% (val)的ANLS。使用LLaVA-665k的SFT数据,Vary-base在ChartQA上的平均性能可以达到66.1%。在这两个具有挑战性的下游任务上的表现与Qwen-VL相当甚至更好,这表明所提出的视觉词汇量放大方法在下游也很有前景。
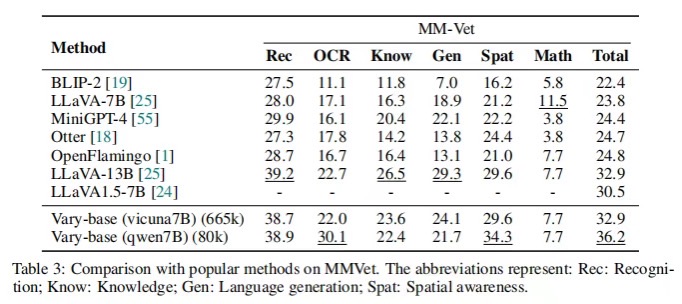
使用相同的LLM (Vicuna-7B)和SFT数据(LLaVA-CC665k), Vary比LLaVA-1.5提高了2.4%(32.9%对30.5%)的总度量,证明Vary的数据和训练策略不会损害模型的一般能力。此外,Vary与Qwen-7B和LLaVA-80k的性能可以达到36.2%,进一步证明了Vary的视觉词汇缩放方式的有效性这一次,只需一句话命令,多模态大模型Vary直接端到端输出结果。Vary表现出了很大的潜力和极高的上限,OCR可以不再需要冗长的pipline,直接端到端输出,且可以按用户的prompt输出不同的格式如latex 、word 、markdown。
这篇关于多模态大模型Vary:扩充视觉Vocabulary,实现更细粒度的视觉感知的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






