本文主要是介绍实战Keras3.0:自定义图片数据集分类任务,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、创建自定义图片数据集
1、数据收集
以10张小狗图片和10张小猫图片为例
2、数据预处理
1、创建Excel表格,并在其中创建两列,一列是图片路径,另一列是对应的标签(狗0、猫1)
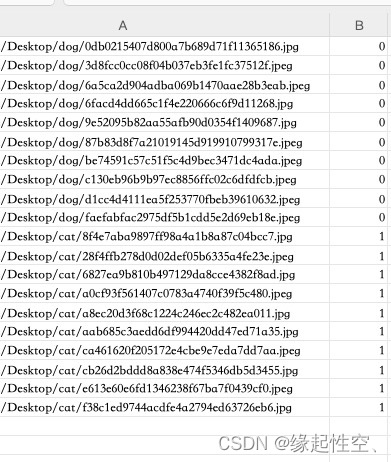
2、用pandas库的read_excel函数读取Excel,用PIL库的Image函数将图片数据格式化
import pandas as pd
from sklearn.model_selection import train_test_split
import keras
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt#读取Excel表格
data = pd.read_excel('/Users/Desktop/cat_dog/dog_and_cat.xlsx')#图片数据处理
def imageDigitization(image_data):train_data = []for image_item in image_data:#读取图片img = Image.open(image_item)# 缩放图片img_resized = img.resize((200, 200))img_array = np.array(img_resized)train_data.append(img_array)return np.array(train_data) #标签数据处理
def labelDigitization(y):train_label=[]for label_item in y:train_label.append(label_item)return np.array(train_label) #格式化图片和标签数据
X = data['A'].values
X = imageDigitization(X)
y = data['B'].to_list()
y = labelDigitization(y)#图片数据归一化
X= X.astype('float32') /255.0
3、验证数据
用matplotlib库pyplot查看数据集,因图像NumPy数组,标签是整数数组。这些标签对应于图像所代表的类别,由于数据集不包括类名称,所以将根据标签的整数自定义映射名称的数组。
#验证数据
class_names = ['dog', 'cat']plt.figure(figsize=(20,20))
for i in range(20):plt.subplot(10,10,i+1)plt.xticks([])plt.yticks([])plt.grid()plt.imshow(X[i], cmap=plt.cm.binary)plt.xlabel(class_names[y[i]])
plt.show()
4、数据准备
用sklearn库的train_test_split划分训练集和测试集,标签one-hot编码。
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)#标签one-hot编码
y_train = keras.utils.to_categorical(y_train,num_classes=2)
y_test = keras.utils.to_categorical(y_test,num_classes=2)
二、搭建网络
任务类型猫、狗图像二分类问题
# 创建一个Sequential模型
model = Sequential()# 添加第一个卷积层,使用32个3x3的卷积核,激活函数为ReLU,输入形状为200x200x3
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(200,200, 3)))# 添加第二个卷积层,使用64个3x3的卷积核,激活函数为ReLU
model.add(Conv2D(64, (3, 3), activation='relu'))# 添加最大池化层,池化大小为2x2
model.add(MaxPooling2D(pool_size=(2, 2)))# 将卷积层的输出展平,以便输入到全连接层
model.add(Flatten())# 添加一个全连接层,使用128个神经元,激活函数为ReLU
model.add(Dense(128, activation='relu'))# 添加一个输出层,使用2个神经元,激活函数为softmax
model.add(Dense(2, activation='softmax'))# 编译模型,优化器为Adam,损失函数为分类交叉熵,评估指标为准确率
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
模型结构
Model: "sequential"
_________________________________________________________________Layer (type) Output Shape Param #
=================================================================conv2d (Conv2D) (None, 198, 198, 32) 896 conv2d_1 (Conv2D) (None, 196, 196, 64) 18496 max_pooling2d (MaxPooling2 (None, 98, 98, 64) 0 D) flatten (Flatten) (None, 614656) 0 dense (Dense) (None, 128) 78676096 dense_1 (Dense) (None, 2) 258 =================================================================
Total params: 78695746 (300.20 MB)
Trainable params: 78695746 (300.20 MB)
Non-trainable params: 0 (0.00 Byte)三、模型训练
保存模型、评估准确率
#模型训练
history=model.fit(X_train, y_train,validation_data=(X_test, y_test),epochs=20,verbose=1)#保存模型
model_path = '/Users/code/model/dog_and_cat.keras'
model.save(model_path)#评估准确率
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=2)
print('\nTest accuracy:', test_acc)这篇关于实战Keras3.0:自定义图片数据集分类任务的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





