本文主要是介绍AAAI 2024:大模型如何掌握复杂工具?看孔子框架的教学之道,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如今,大型语言模型(LLM)发展飞速,在文本和图像生成方面表现都很出色,但在我们的实际生活中,要理解和正确使用各种工具方面尚存在困难。人们期望这些模型在解决实际问题时能够灵活运用和理解各种工具,例如在规划路线、智能家居等生活场景中,模型可能需要准确选择和使用各种工具。
为了应对 LLM 在实际应用场景中使用各种复杂工具时面临的挑战,作者提出了孔子(Confucius)框架,通过当一个出色的“老师”,使 LLM 在贴近我们生活的应用场景中更加智能。通过多阶段学习、迭代自指导和反思反馈(ISIF)等策略,该框架使 LLM 能够更好地掌握各种工具。
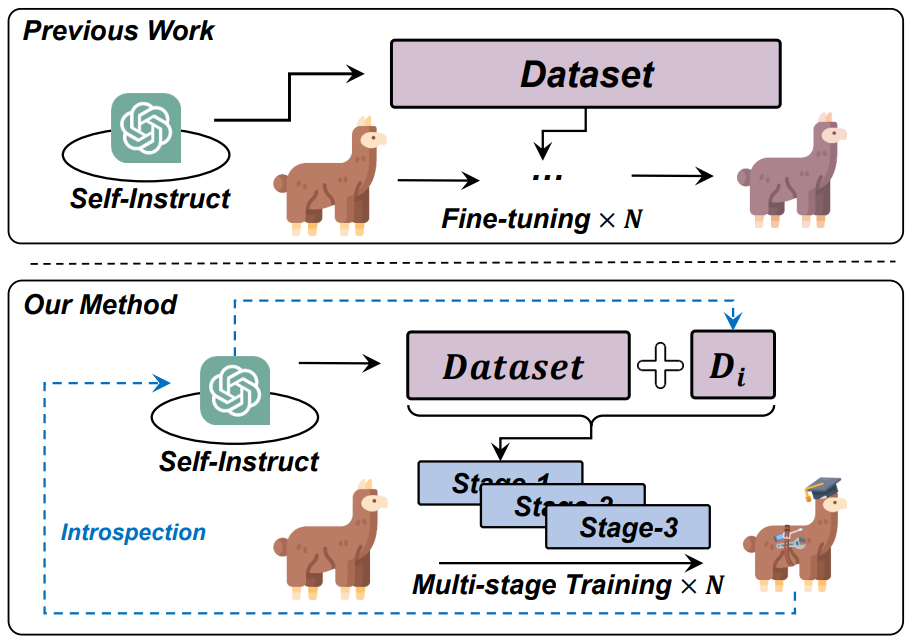
▲图1 现有基于微调的工具学习方法与Confucius 的比较
论文题目:
Confucius: Iterative Tool Learning from Introspection Feedback by Easy-to-Difficult Curriculum
论文链接:
https://arxiv.org/abs/2308.14034
工具学习(Tool Learning)
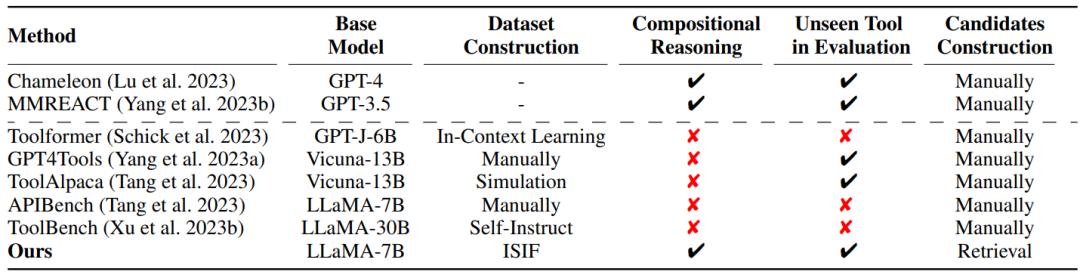
▲表1 相关工作的比较
工具学习可以让 LLM 与各种工具进行有效交互以完成复杂任务。通过将 LLM 与 API 相结合,可以大大扩展其功能,使 LLM 成为用户与广泛的应用生态系统之间的高效桥梁。目前主流的方法可以分成以下2大类:
-
无微调(tuning-free)的工具学习:利用 LLM 天生具备的上下文学习能力的方法。在这种方法中,输入工具的演示,来提示 LLM 使用各种工具。然而,该方法存在两个主要缺点:
-
数据安全问题:由于数据安全原因,不是所有应用都能将工具和用户数据传输给 LLM 服务提供商。这限制了在这些应用中使用专有 LLM 的可能性。
-
输入长度限制:由于输入长度的限制,提示无法容纳大量工具,因此导致对大量工具的应用存在一定的限制。
-
-
基于微调(tuning-base)的工具学习:是一种直接在工具使用数据集上微调语言模型参数的方法,通常通过提示专有 LLM 使用特定工具来构建(如搜索、计算和翻译)。这些方法大多首先使用自指导技术从专有 LLM 中收集工具使用数据,然后微调一个开源模型。其优势在于它们可以轻松部署在自托管环境中。然而,在构建的数据集上微调语言模型通常会引入泛化问题。
孔子(Confucius)框架
Confucius 包含两个主要阶段:
-
为了解决训练 LLM 使用复杂工具的挑战,首先提出一个多阶段学习方法,通过一个从易到难的课程,教授 LLM 使用各种工具。
-
提出了一种迭代的内省与更新(ISIF)技术,动态更新数据集,为模型的训练提供更有针对新的样本,以提高模型使用复杂工具的能力。
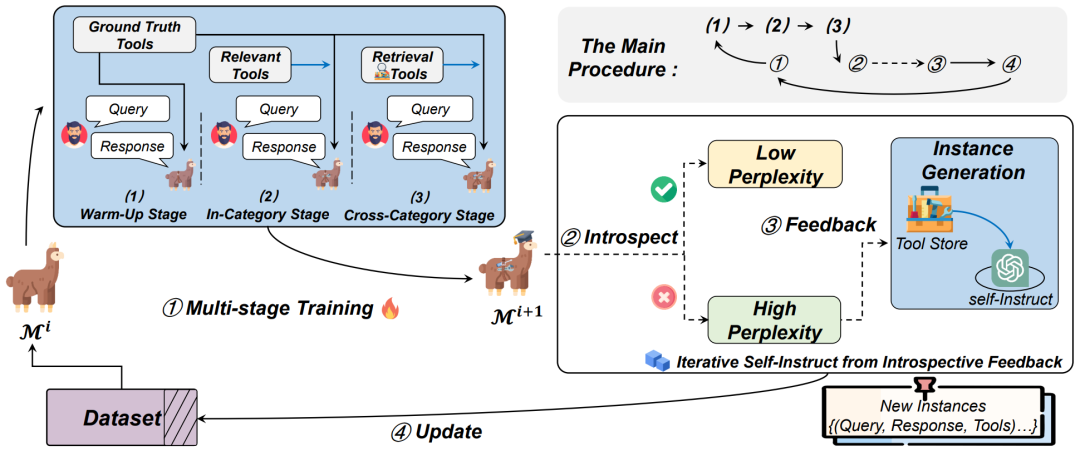
▲图2 整体架构包括多阶段学习和迭代自指导和内省反馈
多阶段学习
这是一种分阶段进行模型训练的方法,旨在逐步提高模型对复杂任务的学习能力。该方法通常包含多个训练阶段,每个阶段都侧重于不同的任务或难度水平,使模型能够逐渐适应和提高性能。如图 2 所示,一般包括以下几个阶段:
-
热身训练阶段(Warm-Up Training):在这个阶段,模型接触到一些基本的任务或信息,以建立起对基础知识的了解。这有助于模型建立起基础,为后续学习提供一个良好的起点。
-
同类别训练阶段(In-Category Training):模型在这个阶段接触到与任务相关的更多信息,学习如何在同一类别的任务中进行选择和应用,这有助于模型更好地理解任务的内在特征和模式。
-
跨类别训练阶段(Cross-Category Training):模型在这个阶段进一步面对更广泛的任务和场景,以在不同类别的任务中进行训练,可以提高模型的泛化能力,使其能够应对更多样化和复杂的情境。
多阶段学习的优势:它能够使模型逐步适应任务的复杂性,避免一开始就让模型直接面对过于困难的情况。这种分阶段的学习过程能够更好地引导模型学到有用的特征和知识,提高模型在真实场景中的性能。
迭代式内省与更新
为了对复杂工具进行更有针对性的训练,这个阶段通过动态构建数据集,根据模型内省的反馈,迭代地定制工具使用的训练数据。如图 2 所示,该阶段包括两个子阶段:实例生成(Instance Generation)和内省与更新(Updates with Introspective Feedback)。
-
实例生成: 首先建立一个工具存储库,包含了 110 个常用的工具和使用实例。这些实例是手动构建的,每个包括一个具体的提问和一个按照思维链格式构建的答案,至少涉及四个工具,以促使数据集的复杂性。接着,从工具存储库中随机选择 5 至 7 个工具,构成工具集 。然后,使用这些工具的演示作为提示,通过 ChatGPT 生成各种提问,并通过组合推理回答这些提问。由于复杂工具需要更多的训练数据,预先创建的数据集与训练过程中经过优化后的 LLM 不同步,因此需要生成更多有针对性的样本来不断更新数据集。

▲表1 与其他工具使用数据集的比较
-
更新与内省反馈: 由于通过自指导生成的实例可能没有受到任何有针对性的训练指导,因此需要构建一个提示来指导实例生成。给定一个包含 个 token 的提问 ,首先检索一个工具集 ,然后将 提供给 LLM 生成回复。通过计算生成的回复 相对于 和 的生成概率,可以得到回复的生成困惑度 。困惑度表示生成的不确定性程度,因此具有更高困惑度的样本需要在后续训练中进行更多的训练。在内省反馈更新阶段,通过过滤具有高困惑度的实例,得到一个被筛选的实例集 。然后,这些被筛选的实例用于自指导提示,生成更多类似的工具使用实例进行进一步的训练。这个过程是迭代的,每个时期都使用更新后的数据集对模型进行训练,以动态改善工具使用的性能。
实验
总体性能
如表 2 的实验表明,Confucius 在已见和未见工具集上均取得显著优异的表现,相较于其他 Baseline 表现更为出色。在已见测试集中,Confucius 在工具选择方面实现了显著的改进,比 ChatGPT 的绝对改善为 4.99。这表明 Confucius 在正确选择工具方面具有潜在的强大性能。
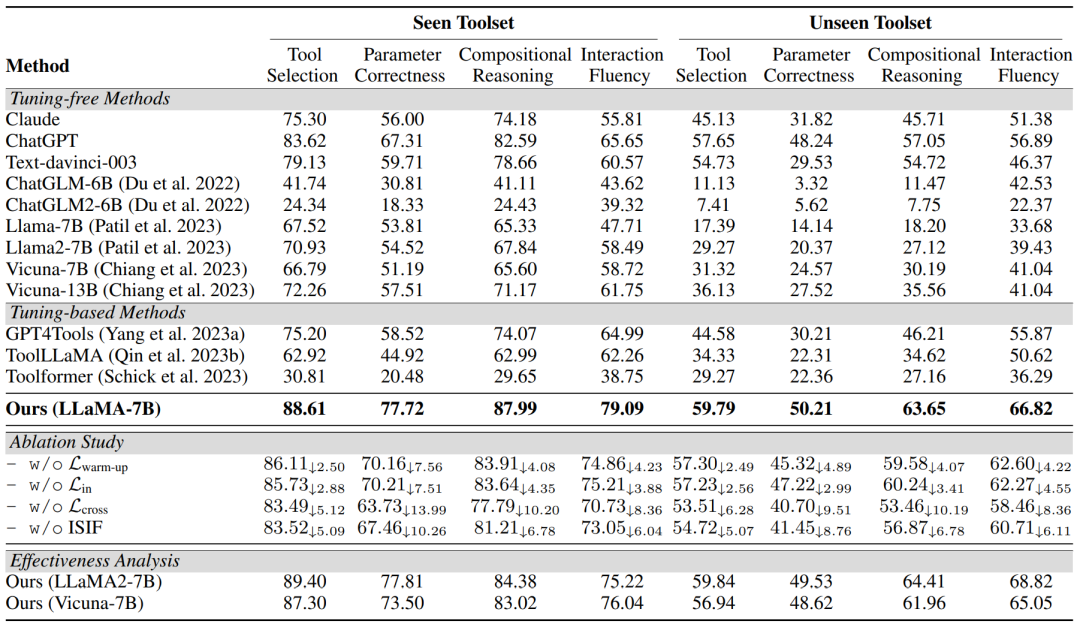
▲表2 整体实验结果比较
在组合推理方面,Confucius 在已见和未见工具集上相较于微调 baseline 有显著提升,同时超越了 ChatGPT。这表明 Confucius 在处理复杂任务时受益于链式思维的工具使用实例,为其性能提供了有效支持。
在未见工具集中,Confucius 胜过了 ChatGPT 等无微调方法,这证明 Confucius 具备有效的泛化工具使用能力。相较之下,其他微调 baseline 在从已见工具集推广到未见工具集时表现出性能下降,而 Confucius 的性能下降相对较小,这要归功于其迭代训练策略 ISIF,为 LLM 提供了更强大的工具使用技能。
此外,工具检索器的效果也得到了验证,实验结果显示该工具检索器能够有效地找到与真实情况相匹配的适当工具。人工评估结果也进一步印证了 Confucius 相对于其他方法的卓越性。
人工评估
人工评估的结果如表 3 所示。在两个方面,即可执行性和流畅性,Confucius始终优于 SOTA 工作。此外,与 ChatGPT 相比,本文的框架取得了可比甚至更好的结果,进一步验证了其有效性。两个评估指标的平均 Kappa 统计分别为 0.762 和 0.732,说明评估者之间存在一致性。
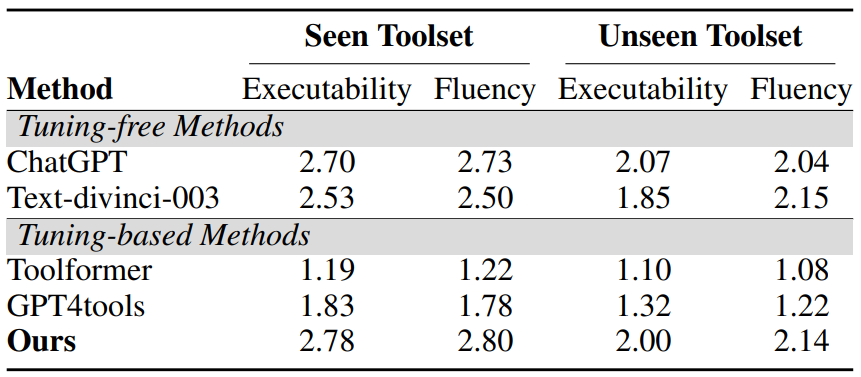
▲表3 在可见和不可见测试集上的人工评估
多阶段训练的分析
在表 2 中,作者还进行了消融实验。可以看到所有的变体模型性能都下降了,这证实了作者在 Confucius 中提出的多阶段训练方法的有效性。相较于其他两个变体模型,去除跨类别训练的模型在工具选择得分方面的性能降低最为显著。这一现象表明,构建一个类似于实际场景的候选工具集以提高LLM的工具选择能力是非常必要的。
ISIF 的分析
为了进行公平比较,作者采用了一种与 ISIF 不同的方法,即根据高困惑度实例的内省反馈,随机抽取了一些实例用作自指导的提示,以生成新实例。然后,更新后的数据集用于训练 LLaMA,该模型与 Confucius 使用相同的基本模型。图 3 展示了在不同大小的初始数据集上训练的模型的性能。可以看到,本文提出的 ISIF 在每个数据集大小上的性能始终优于随机更新数据集的方法,这验证了根据内省反馈动态更新数据集的有效性。
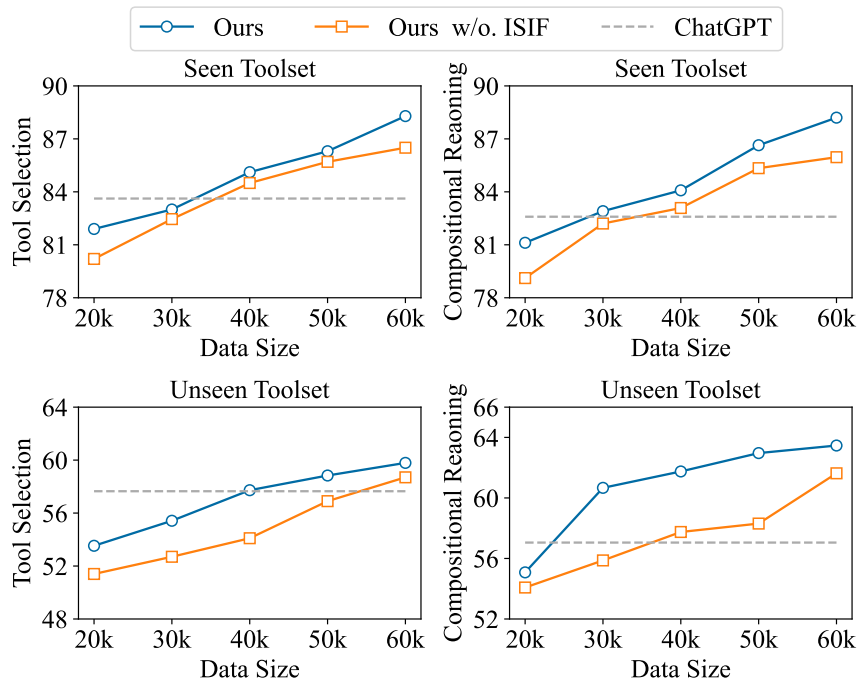
▲图3 Confucius 与变体模型的比较
不同基础模型的泛化
作者为了进一步探索提出的 Confucius 的鲁棒性,使用 Confucius 对其他两个开源LLM(LLaMA2-7B 和 Vicuna-7B)进行调优。正如表 2 所示,与相应的无微调版本相比,使用 Confucius 训练的两个模型在工具选择得分上都取得了较大的优势,这证明了该框架的泛化性。
总结
本文提出了一种名为孔子(Confucius)的工具学习框架,通过采用多阶段学习方法和迭代式内省与更新数据集(ISIF)策略,成功地提升了 LLM 在实际应用场景中掌握复杂工具的能力,从而有效改善了工具使用的效果。具体来说,作者通过从易到难的课程,即热身、同类和跨类别阶段,对 LLM 进行了微调。由于某些工具在不同场景中的使用方式不同,需要更多的训练来充分理解使用方式,因此引入了 ISIF,根据模型内省迭代更新工具使用训练数据集。
实验结果表明,孔子工具学习框架在实现 LLM 对多种工具的更智能学习方面取得了显著成果。这一框架不仅提高了模型在各项实验指标上的性能,而且通过多阶段学习和迭代自指导的结合,使得 LLM 更具适应性和灵活性,能够更好地应对实际应用场景中的各种挑战。

这篇关于AAAI 2024:大模型如何掌握复杂工具?看孔子框架的教学之道的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






