本文主要是介绍Python爬虫中的多线程、线程池,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
进程和线程的基本介绍
进程是一个资源单位,线程是一个执行单位,CPU调度线程来执行程序代码。
当运行一个程序时,会给这个程序分配一个内存空间,存放变量等各种信息资源,而这个内存空间可以说是一个进程, 一个进程默认情况下会有一个线程,称为主线程(因为执行是靠线程的,CPU调度线程来执行程序代码,如果没有线程,那么进程中的资源就不能被使用,代码也就不能被执行)
做个比喻:一个进程相当于一个公司,公司里有各种办公资源,而公司里的员工就相当于线程,工作由员工使用办公资源完成, 如果没有员工,那么那些办公资源不会自动把工作完成,而一个公司必须至少有一个员工,不然公司还能自己成立嘛?
单线程
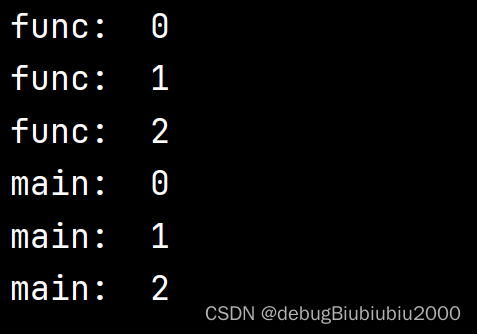
def func():for i in range(3):print('func: ', i)if __name__ == '__main__':func()for i in range(3):print('main: ', i)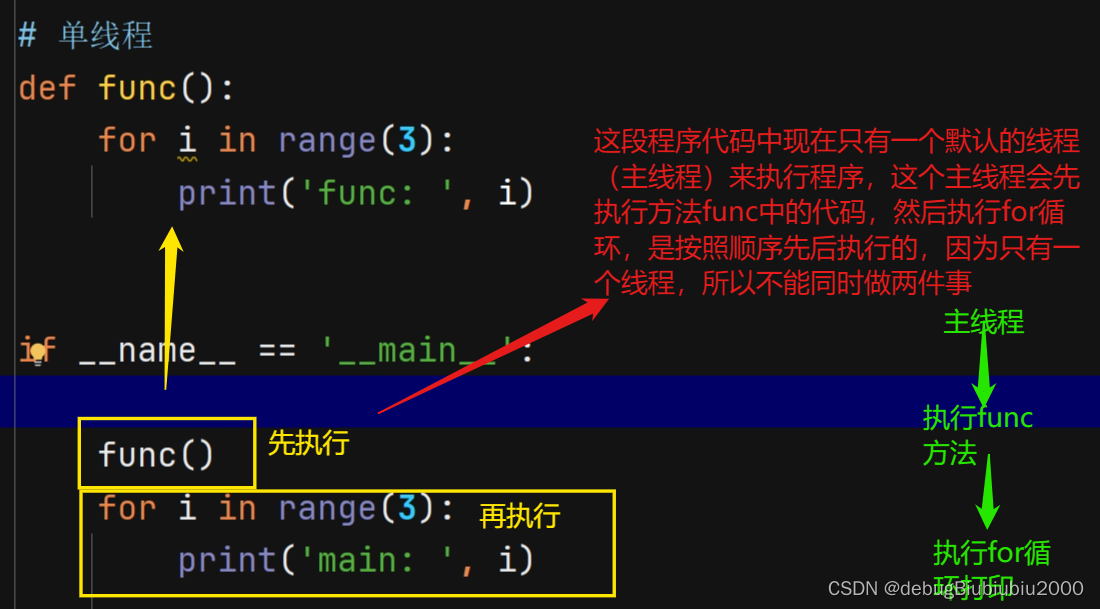
执行效果:
多线程(写法一)
from threading import Thread# 多线程
def func():for i in range(3):print('func: ', i)if __name__ == '__main__':# 创建一个线程,target参数是告诉这个线程该干什么事# 就比如招聘了一个新员工,要给他安排任务# 此处给线程的任务就是调用func方法t = Thread(target=func)# 启动线程,告诉线程可以开始干活了# 注意,start方法只是说线程的状态是工作状态,但是什么时候真的开始执行,由CPU决定# 就是说线程已经随时准备就绪,等待CPU的调度执行t.start()for i in range(3):print('main: ', i)# 多线程
def func(name):for i in range(3):print(name, i)if __name__ == '__main__':# 要给func传递参数,则可以利用args参数# 注意,args接收的是元祖,所以只有一个参数的话,要加上逗号t1 = Thread(target=func, args=('线程1',))t1.start()# 创建第二个线程t2 = Thread(target=func, args='线程2',)for i in range(3):print('main: ', i)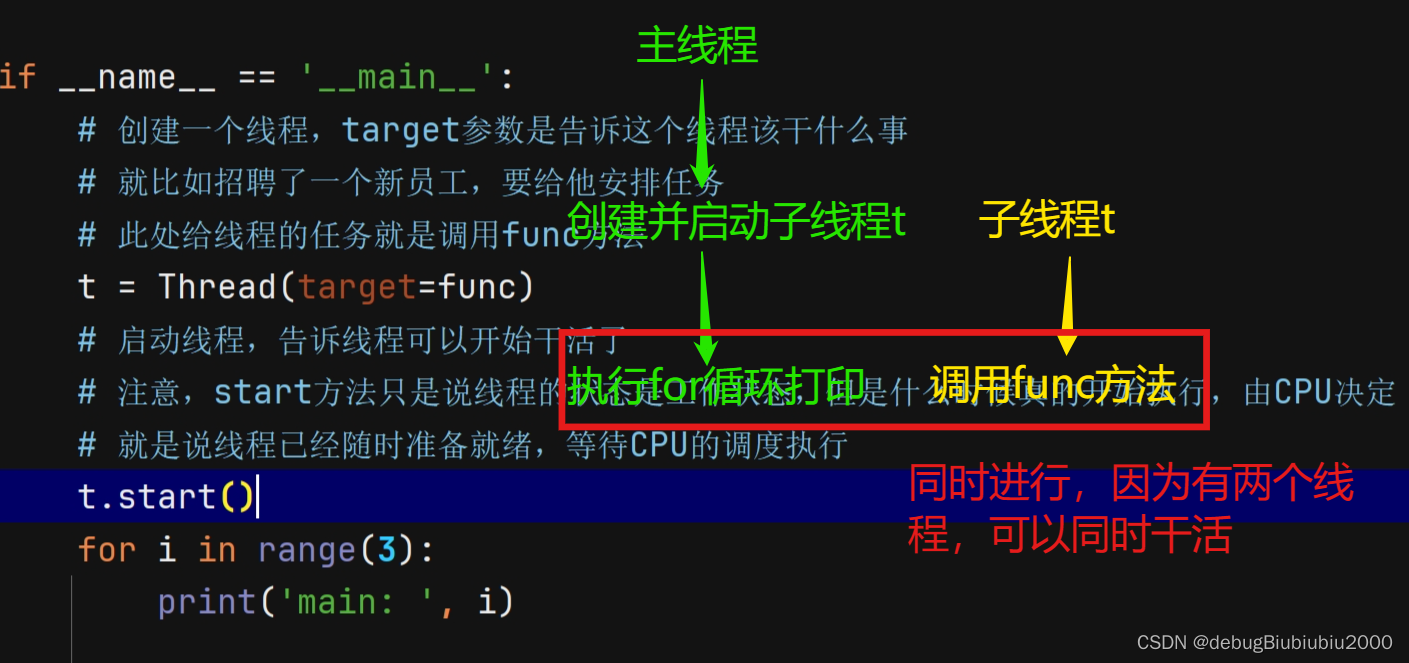 执行结果:
执行结果:

多线程(写法二)
from threading import Thread# 多线程(写法二)
# 自定义线程类,要继承 Thread
class MyThread(Thread):def run(self): # 重写run方法for i in range(3):print('子线程: ', i)if __name__ == '__main__':t = MyThread()# 注意,不能 t.run() ,否则就相当于方法调用,那么就是单线程而不是多线程# 必须通过start方法调用# t.run() # 错误# 调用start方法时,start方法会自己去调用run方法# 所以当线程被执行时,执行的是run方法里的代码逻辑t.start()for i in range(3):print('主线程: ', i)执行效果

创建多进程
和创建多线程差不多
from multiprocessing import Processdef func():for i in range(3):print('子进程:', i)# 创建进程比创建线程所耗费的资源要多很多,所以一般我们使用的都是线程
if __name__ == '__main__':# 如果打印结果不是混着的,应该也是正常的,因为我执行的时候结果和单线程一样p = Process(target=func)p.start()for i in range(3):print('主进程:', i)线程池和进程池基本介绍
假设现在我们要爬取一个网站的评论信息,这个网站的评论由于有很多,被分为1000页,那么我们可以用for循环去爬取每一页的评论数据,但我们想提高效率,利用线程来完成。
我们可以创建1000个线程,每个线程分别爬取一个分页,但是创建线程也需要耗费时间和资源,创建1000个线程的效率可能不一定比for循环效率高。
那我们可以考虑少创建一些线程,比如创建50个线程,然后让这50个线程依次去爬取1000个分页的评论,这就是线程池的作用。我们不需要关心这50个线程的具体调度情况,比如哪个进程爬取了哪些网页之类的,我们只需要知道,这50个线程会一起合作,完成1000个URL的爬取任务即可。而具体的每个线程的调度安排由线程池管理。
所以线程池就是一次性开辟一些线程(如一次性开辟50个线程),我们用户直接给线程池提交某个任务(比如爬取1000个URL),由线程池安排这50个线程去共同完成这个任务。
线程池代码如下,进程池的使用和线程池一样,只需要把 ThreadPoolExecutor 换成 ProcessPoolExecutor就行
# ThreadPoolExecutor 线程池, ProcessPoolExecutor 进程池
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutordef task(name):print('执行任务', name)if __name__ == '__main__':# 创建有3个进程的进程池with ThreadPoolExecutor(3) as t:for i in range(6): # 现在要完成6个任务,将这6个任务分配给3个线程# 向线程池t提交任务task, 任务task需要传惨直接在后面写上,如name=xxxt.submit(task, name=f'task{i}')# 只有上述线程池代码执行完成后,才会接着往下执行print('任务全部执行完毕...')执行效果如下图:

进程池的应用——爬取北京新发地的价格数据
import requests
from concurrent.futures import ThreadPoolExecutordef download_one_page(cur_page):url = 'http://www.xinfadi.com.cn/getPriceData.html'data = {'limit': 20,'current': cur_page, # 第多少页的数据'pubDateStartTime': '','pubDateEndTime': '','prodPcatid': '','prodCatid': '','prodName': ''}resp = requests.post(url, data=data)print(resp.json())if __name__ == '__main__':# 可以分别对比for循环和用线程池两种爬取方式,会看到线程池的速度要快很多# for i in range(1, 101): # download_one_page(i)with ThreadPoolExecutor(10) as t: # 创建有10个进程的进程池for i in range(1, 101): # 数据太多了,这里只爬取前100页t.submit(download_one_page, cur_page=i)print('爬取北京新发地前100页数据完成!')
这篇关于Python爬虫中的多线程、线程池的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




