本文主要是介绍可狱可囚的爬虫系列课程 07:BeautifulSoup4库的使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前面一直在讲 Requests 模块如何使用,那都是在请求阶段要做的事情,相信很多网友都在等一个能够开始爬网站信息的教程,今天它来了,今天我要给大家讲一个很简单易懂的库:BeautifulSoup4。
一、概述&安装
BeautifulSoup4 属于 BeautifulSoup 系列的第四代版本,BeautifulSoup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库,这个库能够实现树文档的导航、查找,从而帮助我们提取到网页中所需要的数据。
与 Requests 一样,BeautifulSoup4 也是一个三方库,要使用这个库,同样的使用 pip 命令安装:pip3 install BeautifulSoup4。如果忘记了在哪里安装,请回看 Requests 模块第一篇文章。
安装好以后,我们围绕数据提取这个话题对 BeautifulSoup4 进行剖析。
二、如何使用
想要使用好 BeautifulSoup4 库(以下简称 bs4 库)不是一件易事,还需要懂 HTML 和 CSS 的知识,不过大家既然已经学到这里了,无论你是否具备这些知识,我都用通俗易懂的语言为大家讲解清楚,保证大家在学完这篇文章以后能够顺利的爬取一部分网站。
爬虫中开始使用 bs4 库时表明一定获取到了网页源代码(前面已经讲过 Requests 模块获取网页源代码,不再赘述!),我们只需要在此基础上借助 bs4 库处理即可。
bs4 库解析器的选择与使用
(1) 假设我们已经得到了某网页的源代码(字符串类型),如下所示:
html_str = """<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story" id="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie<p>Test</p></a>;
and they lived at the bottom of a well.</p><p class="story" id="story">...</p>
"""
(2)针对网页源代码,我们需要使用 bs4 库中的 BeautifulSoup 方法进行文档解析,这个文档解析过程需要使用解析器, bs4 库已经提供三种解析器可选,让我们择优选取,详情见下表:
| 解析器 | 用法 | 优点 | 缺点 |
|---|---|---|---|
| Python 标准库 | BeautifulSoup(源代码, ‘html.parser’) | 解析速度适中、容错性好 | 不如 lxml 速度快、不如 html5lib 容错性好 |
| lxml HTML 解析器 | BeautifulSoup(源代码, ‘lxml’) | 解析速度最快、容错性好 | 需要单独安装 lxml 库 |
| lxml XML 解析器 | BeautifulSoup(源代码, ‘xml’) | 解析速度最快、容错性好 | 需要单独安装 lxml 库 |
| html5lib | BeautifulSoup(源代码, ‘html5lib’) | 容错性最好 | 解析速度最慢 |
上表所示,经过对比我们优先选择 lxml 解析器,但本文以讲基础为主,我们退而求其次,选择 Python 标准库的用法,目前几乎不会再有 html5lib 解析器的应用,大家稍微了解即可。
(3)我们已然选择了恰当的解析器,那么 bs4 库的使用应当如何体现在代码中呢?这个库安装时要记住用全称 BeautifulSoup4,使用时要简写为 bs4。导包连同使用解析器解析上方网页源代码的代码一起为大家呈现:
from bs4 import BeautifulSoupsoup = BeautifulSoup(html_str, 'html.parser')
树结构的讲解
如果有刨根问底的同学,此时可能会注意到变量 soup 打印出来的结果与上方网页源代码无异,这是为什么呢?
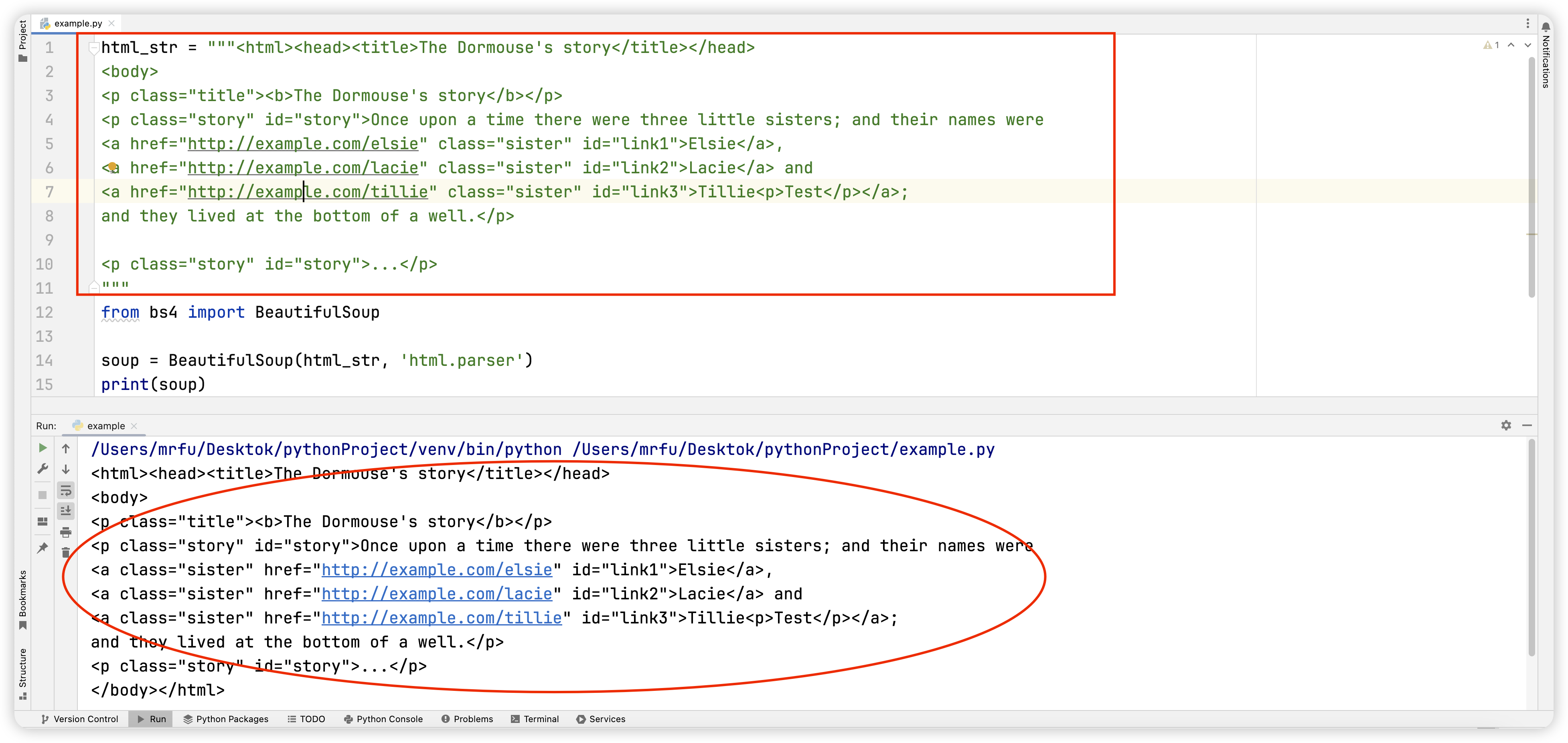
bs4 库对网页源代码的解析其实是将网页源代码转换了一种结构,这种结构我们称之为树结构,更有利于我们后续信息的导航与采集,下图展示了树结构的大致构造。

这里我们对树结构做一下解读:
(1)整体看树结构是一个由外到内层层递进的一种结构,最外层是根节点 html 标签,网页源代码的所有标签都属于它;其次再划分为两层,分别是 head 标签和 body 标签,它们两个标签中 body 负责网页内容显示,head 负责网页的相关配置;再往下层更加详细的就是按照 HTML 语言的语法规则,交由我们程序员负责如何配置以及显示何种内容。这大概就是一个完整的树结构,同时这也是 HTML 语言规定的大致结构;
(2)分层看这个树结构是由一个个 HTML 标签组成的,类似的像
一样的单标签,在网页源代码中看到这样形式的都可以理解为是 HTML 标签。但是通常情况下 HTML 标签内还包含很多属性、标签、内容,像
<div id="box"><h1>电影观后感</h1></div>、
<a href="https://www.baidu.com">百度一下</a>等,这些按照规则定制出来的内容便组成了网页。
我们的爬虫便是按照这些层次结构进行数据的采集。大家简单了解上述内容以后,希望能够再去菜鸟教程等网站学习一下和 HTML 相关的内容,让自己对树结构以及网页的结构有更深入的理解。
CSS 选择器的使用&数据的采集
接下来,我们以最开始给大家的那一段网页源代码,结合六种 CSS 选择器以及 bs4 库提供的两个方法、两个属性,开始信息的提取。
(1)select 方法:使用 CSS 选择器(标签选择器、class 选择器、id 选择器、父子选择器、后代选择器、nth-child 选择器)从指定位置处找出所有符合的标签存放入列表中。
(2)select_one 方法:使用 CSS 选择器(标签选择器、class 选择器、id 选择器、父子选择器、后代选择器、nth-child 选择器)从指定位置处找出第一个符合的标签。
(3)text 属性:从标签中获取标签内容。
(4)attrs 属性:从标签中获取指定属性名对应的属性值。
我们用以下几个问题来学习相关内容。
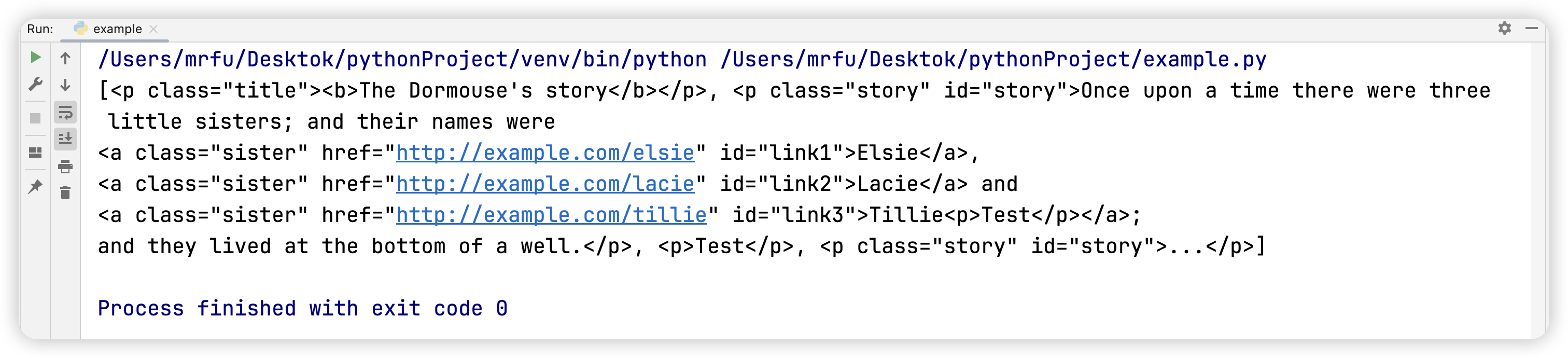
问题一:使用标签选择器获取源代码中所有的 p 标签。
标签选择器:默认代表源代码中所有的某标签。
p_list_1 = soup.select('p')
print(p_list_1)
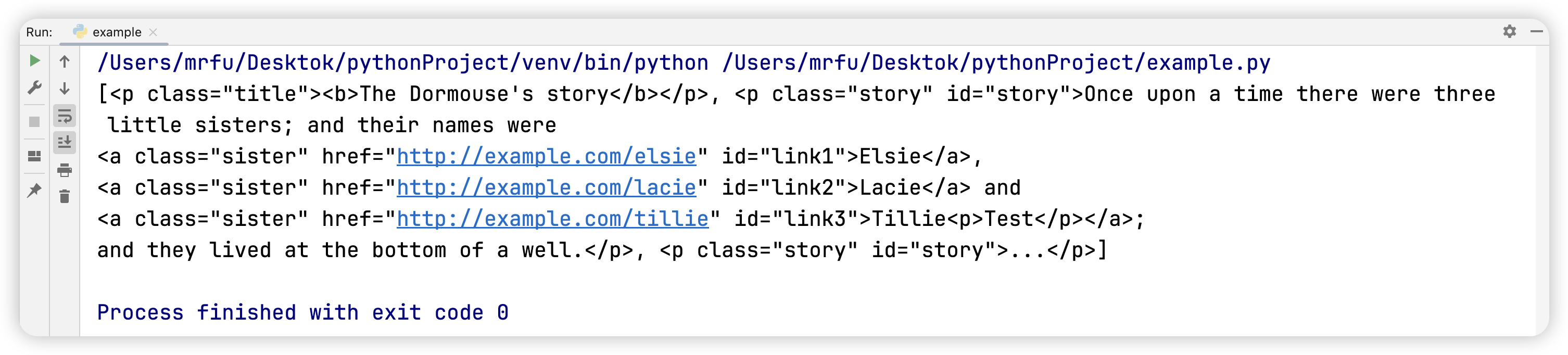
问题二:使用父子选择器获取 body 标签下所有的 p 子标签。
父子选择器:使用>连接具有父子关系的标签,父标签在左,子标签在右。
如何判断两个标签是否是父子关系呢?举个例子:<body><p class="title"><b>The Dormouse's story</b></p><p>Test</p></body>这里的标签 body 与标签 p 为父子关系,标签 p 与标签 b 为父子关系,标签 body 与标签 b 为后代关系,两个标签 p 为兄弟关系。
p_list_2 = soup.select('body > p')
print(p_list_2)
问题三:使用后代选择器获取 body 标签下的所有 a 标签。
后代选择器:使用空格连接具有后代关系的标签,祖先标签在左,后代标签在右。
a_list = soup.select('body a')
print(a_list)

问题四:分别使用 class 选择器和 nth-child 选择器获取 body 标签下的第一个 p 子标签。
class 选择器:如果标签内有 class 属性,只需要用点来调用 class 属性对应的属性值即可。例如:<p class="one"></p>,此时就是.one。
nth-child 选择器:通过同级标签中的排名数来选择标签。网页源代码中 body 标签下所有子标签中排名第一的位置是我们需要的标签,所以写为 p:nth-child(1)。
p_1 = soup.select_one('body > p.title')
print(p_1)p_2 = soup.select_one('body > p:nth-child(1)')
print(p_2)

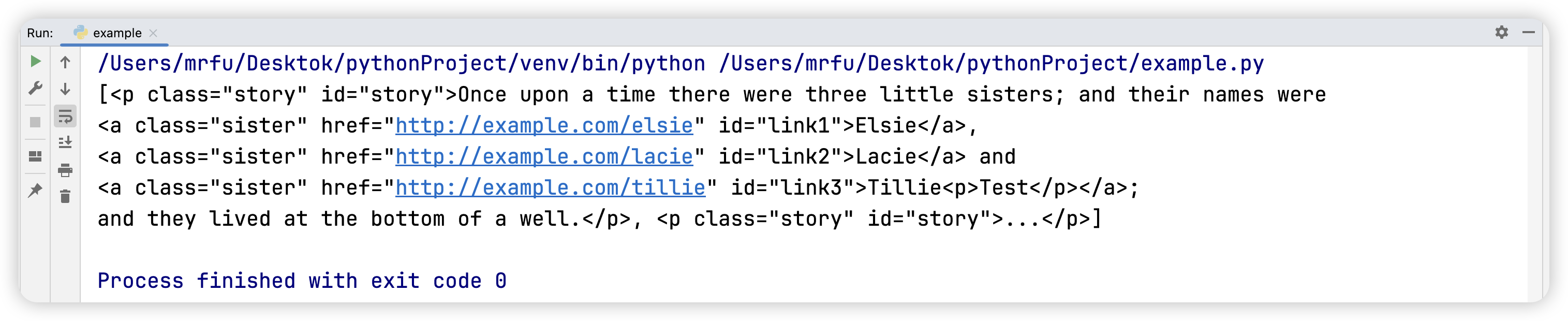
问题五:通过 id 选择器获取 body 标签下的后两个 p 子标签。
id 选择器:如果标签内有 id 属性,只需要用井号来调用 id 属性对应的属性值即可。例如:<p id="one"></p>,此时就是#one。
p_list_3 = soup.select('body > p#story')
print(p_list_3)
问题六:选择器综合使用获取 body 标签下的第二个 p 子标签的第三个 a 子标签的标签内容和 href 属性值。
text 属性:能够获取到标签内的内容。例如:
张三
,此处的张三便是标签内的内容。attrs 属性:能够根据属性名获取到对应的属性值。例如: 百度一下,此处的 href 是属性名,https://www.baidu.com 是 href 对应的属性值。
text_str = soup.select_one('body > p:nth-of-type(2) > a#link3').text
href_str = soup.select_one('body > p:nth-of-type(2) > a#link3').attrs['href']
print(text_str)
print(href_str)

三、完整代码&总结
html_str = """<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story" id="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie<p>Test</p></a>;
and they lived at the bottom of a well.</p><p class="story" id="story">...</p>
"""
from bs4 import BeautifulSoupsoup = BeautifulSoup(html_str, 'html.parser')# 问题一:使用标签选择器获取源代码中所有的 p 标签。
p_list_1 = soup.select('p')
print(p_list_1)# 问题二:使用父子选择器获取 body 标签下所有的 p 子标签。
p_list_2 = soup.select('body > p')
print(p_list_2)# 问题三:使用后代选择器获取 body 标签下的所有 a 标签。
a_list = soup.select('body a')
print(a_list)# 问题四:分别使用 class 选择器和 nth-child 选择器获取 body 标签下的第一个 p 子标签。
p_1 = soup.select_one('body > p.title')
print(p_1)p_2 = soup.select_one('body > p:nth-child(1)')
print(p_2)# 问题五:通过 id 选择器获取 body 标签下的后两个 p 子标签。
p_list_3 = soup.select('body > p#story')
print(p_list_3)# 问题六:选择器综合使用获取 body 标签下的第二个 p 子标签的第三个 a 子标签的标签内容和 href 属性值。
text_str = soup.select_one('body > p:nth-of-type(2) > a#link3').text
href_str = soup.select_one('body > p:nth-of-type(2) > a#link3').attrs['href']
print(text_str)
print(href_str)
上述六个问题涉及到的 CSS 选择器的使用需要大家仔细琢磨,这六个问题涉及的答案不唯一,但是比较具有综合性,我们讲述的这六种 CSS 选择器可以结合使用,如果能把这六种 CSS 选择器学会,爬取数据对大家来说轻而易举。
可能有小伙伴学习过 bs4 库的使用,可能会疑惑我怎么没接触过 select、select_one 这些呢,大家不要担心,bs4 库提供了很多类似于 select、select_one 的方法,比如 find_all、find 方法,这些方法大同小异,你只要掌握上述文章中涉及的知识点,bs4 库的使用就没问题。
以上就是 bs4 库要掌握的内容,下篇文章我们将带大家进行网页爬虫的实战训练。
这篇关于可狱可囚的爬虫系列课程 07:BeautifulSoup4库的使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






