本文主要是介绍t-SNE高维数据可视化实例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
t-SNE:高维数据分布可视化
实例1:自动生成一个S形状的三维曲线
实例1结果:

实例1完整代码:
import matplotlib.pyplot as plt
from sklearn import manifold, datasets
"""对S型曲线数据的降维和可视化"""x, color = datasets.make_s_curve(n_samples=1000, random_state=0) # 生成一个S形状的三维曲线,以及相应的颜色数据,数据点的数量为1000个,随机数种子是0,color是[1000,1]的一维数据,对应每个点的颜色
n_neighbors = 10
n_components = 2 #n_neighbors和n_components分别表示t-SNE算法中的近邻数和降维后的维度数fig = plt.figure(figsize=(15, 15)) #图像的宽和高
plt.suptitle("Dimensionality Reduction and Visualization of S-Curve Data ", fontsize=14) #自定义图像名称# 绘制S型曲线的3D图像
ax = fig.add_subplot(211, projection='3d') #分为2行1列的子图布局,选择第1个子图,投影方式为3D
ax.scatter(x[:, 0], x[:, 1], x[:, 2], c=color, cmap=plt.cm.Spectral) #x[:, 0], x[:, 1], x[:, 2]代表x,y,z 绘制散点图,Spectral colormap将不同的颜色映射到数据集的不同标签上
ax.set_title('Original S-Curve', fontsize=14)
ax.view_init(4, -72) # 将视角设置为仰角4度,方位角-72度# t-SNE的降维与可视化
ts = manifold.TSNE(n_components=n_components,perplexity=30) #将原始数据降低到n_components维度;perplexity=30表示t-SNE算法的困惑度参数设置为30。
# 训练模型
y = ts.fit_transform(x)
ax1 = fig.add_subplot(2, 1, 2) ##分为2行1列的子图布局,选择第2个子图
plt.scatter(y[:, 0], y[:, 1], c=color, cmap=plt.cm.Spectral)
ax1.set_title('t-SNE Curve', fontsize=14)
plt.show()实例2:手写数字
实例2结果

这个由于数据量太多,呈现的效果不是很明显
实例2完整代码
from sklearn import preprocessing
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import torchvisiontraindata = torchvision.datasets.MNIST(root='./t-SNE_dataset/', train=True, download=True)
testdata = torchvision.datasets.MNIST(root='./t-SNE_dataset/', train=False, download=True)X_train = traindata.data #[60000, 28, 28]
y_train = traindata.targets #[60000]
X_test = testdata.data #[10000, 28, 28]
y_test = testdata.targets #[10000]X_train = X_train.view(len(X_train), -1) #[样本数量, 特征维度];-1是根据原来的形状自动计算出新的维度大小,以保证总的元素个数不变,这里是28*28
X_test = X_test.view(len(X_test), -1)# t-SNE降维处理
tsne = TSNE(n_components=3, verbose=1 ,random_state=42) #n_components=3表示降维后的维度为3,即将图像数据降低到三维;verbose=1表示打印详细的日志信息;random_state=42表示设置随机种子以保证可重复性。
train = tsne.fit_transform(X_train)
test = tsne.transform(X_test) # 注意:使用已经训练好的t-SNE对象对验证集进行降维,不再fit_transform# 归一化处理
scaler = preprocessing.MinMaxScaler(feature_range=(-1,1))
train = scaler.fit_transform(train)
test = scaler.transform(test) # 对验证集进行归一化处理,使用训练集的scaler对象进行transformfig = plt.figure(figsize=(20, 20))
ax = fig.add_subplot(projection='3d') #创建一个三维坐标轴,并将它添加到图像窗口中
ax.set_title('t-SNE process')
ax.scatter(train[:,0], train[:,1], train[:,2] , c=y_train, marker='o', label='Train', s=10)
#c=y_train表示根据训练集的标签y_train来对散点进行颜色编码,每个标签对应一个特定的颜色。s=10将每个数据点的大小设置为 10 像素,使用marker='o'表示使用圆圈形状的标记来表示训练集
ax.scatter(test[:,0], test[:,1], test[:,2] , c=y_test, marker='^', label='Test', s=10) # 使用marker='^'表示使用三角形形状的标记来表示验证集
ax.legend() # 添加图例,以便区分训练集和验证集plt.show()实例3:自己的实验(判断迁移是否有效)
实例3实验结果 :
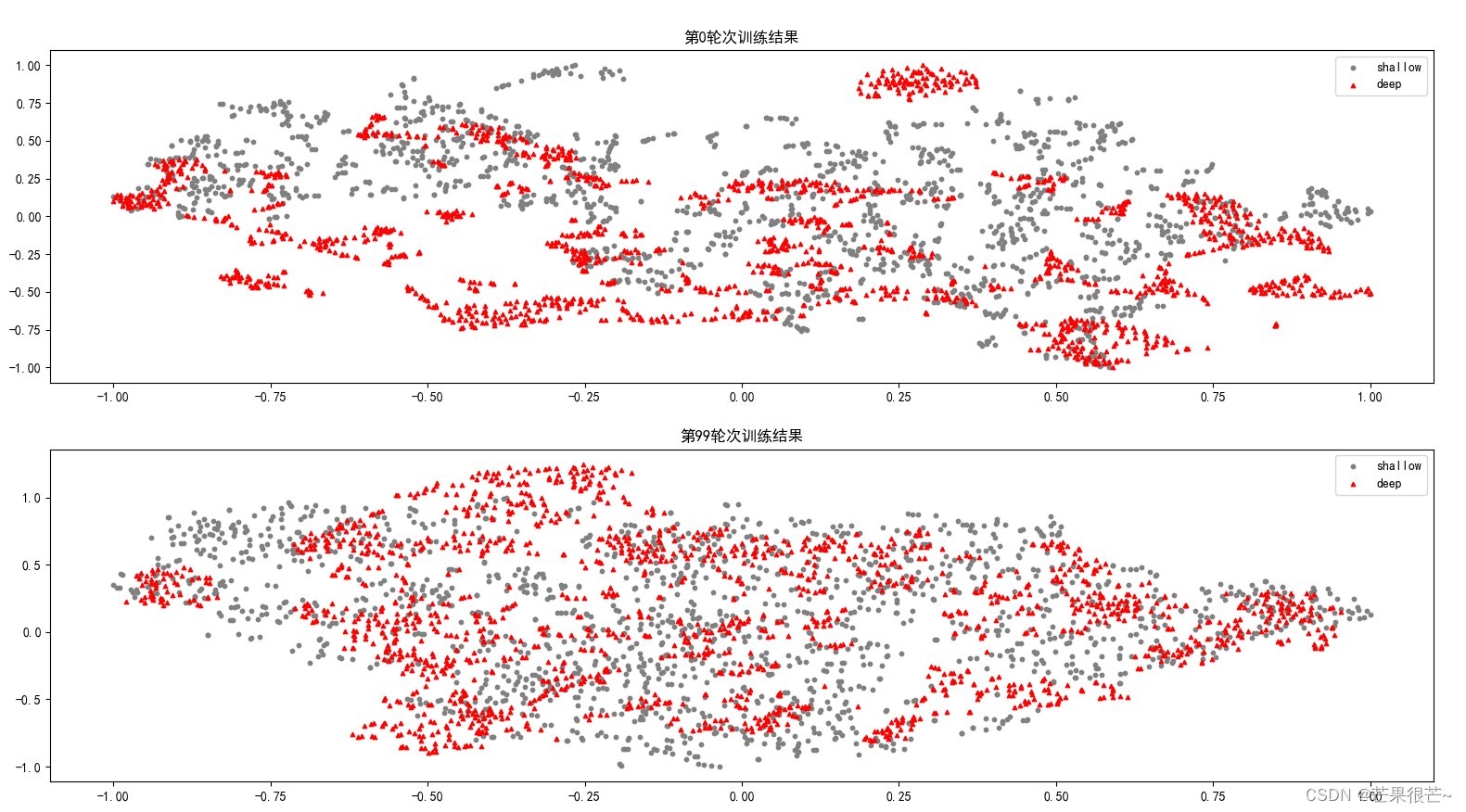
实例3代码:
from __future__ import print_function
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torch.autograd import Variable
import os
from data_loader_new import DatasetFolder
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
from sklearn import preprocessingdef sne():ckpt_model_0 = "E:/XD_DANN/dataset1400/result1214/mnist_mnistm_model_epoch_0.pth"my_net_0 = torch.load(ckpt_model_0)ckpt_model_9 = "E:/XD_DANN/dataset1400/result1214/mnist_mnistm_model_epoch_99.pth"my_net_9 = torch.load(ckpt_model_9)alpha = 0source_dataset_name = 'shallow_train' ###target_dataset_name = 'deep_train' ###source_image_root = os.path.join('..', 't_SNE', source_dataset_name)target_image_root = os.path.join('..', 't_SNE', target_dataset_name)dataset_source = DatasetFolder(source_image_root)dataloader_source = DataLoader(dataset=dataset_source,batch_size=len(dataset_source),shuffle=True,num_workers=8)data_source_iter = iter(dataloader_source)s_img, _, _ = next(data_source_iter) #图片,标签,位置信息_, _, s_feature_0 = my_net_0(input_data=s_img, alpha=alpha)_, _, s_feature_9 = my_net_9(input_data=s_img, alpha=alpha) #类别,领域,特征print("源域数据加载成功")dataset_target = DatasetFolder(root=target_image_root)dataloader_target = DataLoader(dataset=dataset_target,batch_size=len(dataset_target),shuffle=True,num_workers=8)data_target_iter = iter(dataloader_target)t_img,_ ,_ = next(data_target_iter)_, _, t_feature_0 = my_net_0(input_data=t_img, alpha=alpha)_, _, t_feature_9 = my_net_9(input_data=t_img, alpha=alpha) # 类别,领域,特征print("目标域数据加载成功")# s_img = s_img.view(len(s_img), -1) # [样本数量, 特征维度];-1是根据原来的形状自动计算出新的维度大小,以保证总的元素个数不变,这里是28*28# t_img = t_img.view(len(t_img), -1)s_feature_0 = s_feature_0.view(len(s_feature_0), -1)t_feature_0 = t_feature_0.view(len(t_feature_0), -1)s_feature_9 = s_feature_9.view(len(s_feature_9), -1)t_feature_9 = t_feature_9.view(len(t_feature_9), -1)tsne = TSNE(n_components=2, verbose=1,random_state=42) # n_components=3表示降维后的维度为3,即将图像数据降低到三维;verbose=1表示打印详细的日志信息;random_state=42表示设置随机种子以保证可重复性。# shallow_before = tsne.fit_transform(s_img.detach().numpy())# deep_before = tsne.fit_transform(t_img.detach().numpy())shallow_before = tsne.fit_transform(s_feature_0.detach().numpy())deep_before = tsne.fit_transform(t_feature_0.detach().numpy())shallow_after = tsne.fit_transform(s_feature_9.detach().numpy())deep_after = tsne.fit_transform(t_feature_9.detach().numpy())scaler = preprocessing.MinMaxScaler(feature_range=(-1, 1))shallow_before = scaler.fit_transform(shallow_before)deep_before = scaler.fit_transform(deep_before)shallow_after = scaler.fit_transform(shallow_after)deep_after = scaler.transform(deep_after) # 对验证集进行归一化处理,使用训练集的scaler对象进行transformfig = plt.figure(figsize=(30, 30))ax = fig.add_subplot(211)ax.set_title('第0轮次训练结果')ax.scatter(shallow_before[:, 0], shallow_before[:, 1], c='gray', marker='o', label='shallow', s=10)ax.scatter(deep_before[:, 0], deep_before[:, 1], c='red', marker='^', label='deep', s=10)ax.legend()ax = fig.add_subplot(212)ax.set_title('第99轮次训练结果')ax.scatter(shallow_after[:,0], shallow_after[:,1], c='gray', marker='o', label='shallow', s=10)ax.scatter(deep_after[:,0], deep_after[:,1] , c='red', marker='^', label='deep', s=10) # 使用marker='^'表示使用三角形形状的标记来表示验证集ax.legend() # 添加图例,以便区分训练集和验证集plt.rcParams['font.sans-serif'] = ['SimHei'] ## 用来正常显示中文标签plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号plt.show()if __name__ == '__main__':sne()print('done')
大家可以根据自己的实验需要更改代码,提醒若需要显示中文/负号,别忘了这两行代码哟!
plt.rcParams['font.sans-serif'] = ['SimHei'] ## 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号参考:http://t.csdnimg.cn/cshBV
这篇关于t-SNE高维数据可视化实例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





