本文主要是介绍用户行为分析遇到的问题-ubantu16,hadoop3.1.3,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
用户行为分析传送门
我的版本
ubantu16
hadoop 3.1.3
habse 2.2.2
hive3.1.3
zookeeper3.8.3
sqoop 1.46/1.47 我sqoop把MySQL数据往hbase导数据时候有问题
重磅:大数据课程实验案例:网站用户行为分析(免费共享)
用户行为分析-小数据集 - CSDN App
Hmaster节点老掉:配置zookeeper
密码相关的问题
第一个是root账户的密码,ubantu是没给root设置密码的,那怎么且换root用户呢
sudo -i #此时就已经切换到root用户了
passwd root #设置root账户密码
第二个问题是MySQL root的密码
sudo mysql #进入MySQL
#登录进去之后
use mysql;ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '你的密码';
flush privileges;
ubuntu22.04 密钥存储在过时的 trusted.gpg 密钥环中
遇到缺密钥的情况:
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 这里换成缺的那个密钥
我的配置:
~/.bashrc
export FLUME_HOME=/usr/local/flume
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$PATH:$FLUME_HOME/binexport SQOOP_HOME=/usr/local/sqoop
export PATH=$PATH:$SBT_HOME/bin:$SQOOP_HOME/bin
export CLASSPATH=$CLASSPATH:$SQOOP_HOME/lib
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_212
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=${JAVA_HOME}/bin:$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin:/usr/local/hbase/bin:export HBASE_HOME=/usr/local/hbaseexport ZOOKEEPER_HOME=/usr/local/zookeeper-3.8.3-bin
export PATH=$PATH:$ZOOKEEPER_HOME/binexport PIG_HOME=/usr/local/pig
export PATH=$PATH:/usr/local/pig/bin
core-site.xml
<configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property><property><name>dfs.http.address</name><value>0.0.0.0:50070</value></property>
</configuration>
hdfs-site.xml
<configuration><property><name>dfs.namenode.secondary.http-address</name><value>Master:50090</value></property><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property><property><name>dfs.namenode.http-address</name><value>Master:50070</value></property>
</configuration>
yarn-site.xml
<?xml version="1.0"?>
<configuration><property><name>yarn.resourcemanager.hostname</name><value>Master</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.application.classpath</name><value>/usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/share/hadoop/yarn:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*</value></property>
</configuration>
mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.map.memory.mb</name><value>1536</value>
</property>
<property><name>mapreduce.map.java.opts</name><value>-Xmx1024M</value>
</property>
<property><name>mapreduce.reduce.memory.mb</name><value>3072</value>
</property>
<property><name>mapreduce.reduce.java.opts</name><value>-Xmx2560M</value>
</property></configuration>
步骤二
问题1
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask

问题2
hive插入数据报错
步骤三
问题1
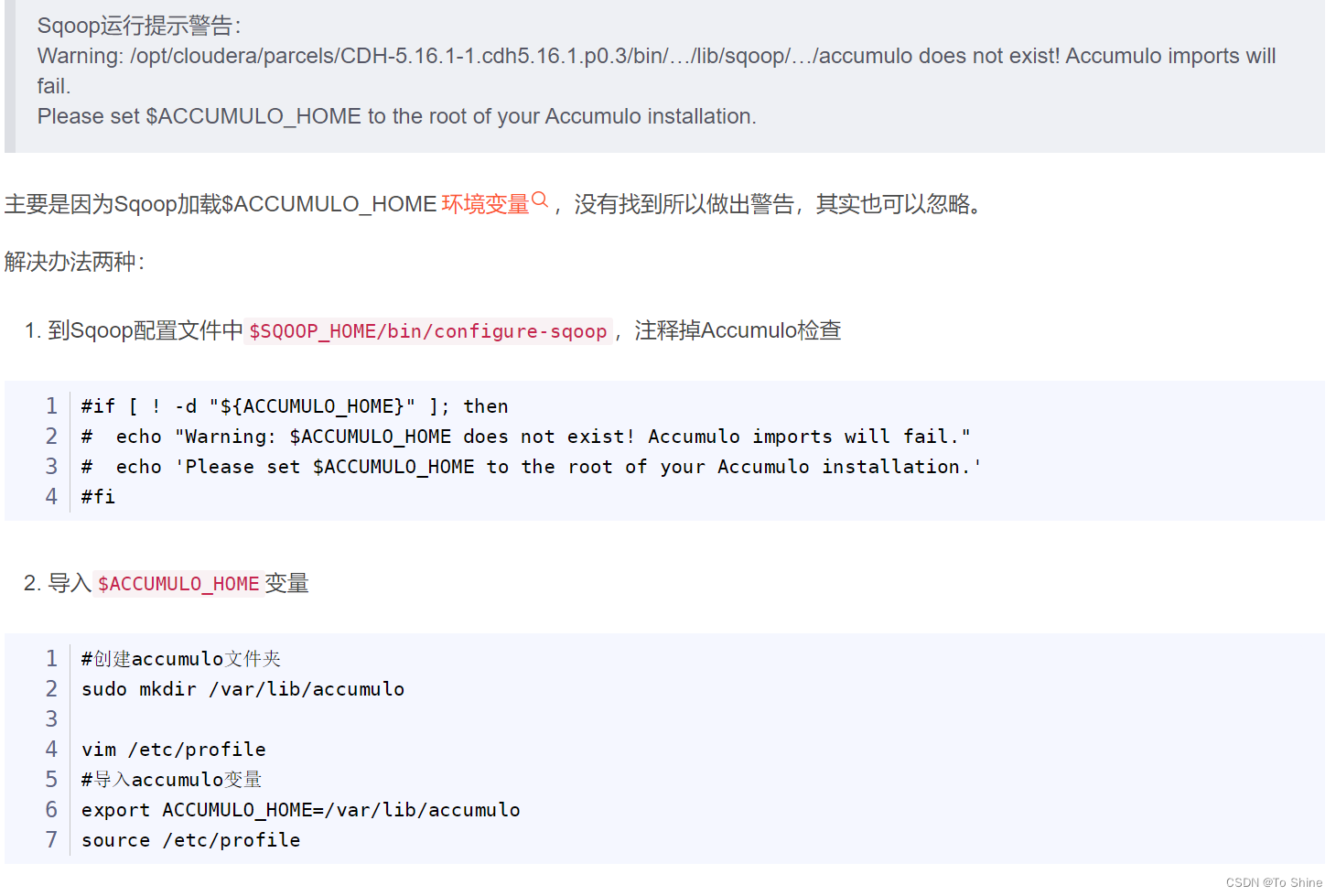
问题2
ERROR: org.apache.hadoop.hbase.PleaseHoldException: Master is initializing 解决办法
ERROR: org.apache.hadoop.hbase.PleaseHoldException: Master is initializing 解决办法
步骤4
问题1:跟着教程有时候安不上RMySQL,实在没办法手动导入吧2
R无法安装RMySQL程序包解决方案
问题2:安不上ggplot2
R中命令行安装ggplot2不成功
安装一个rstudio在rstudio里面找install,手动安
ubantu16如何安装R3.6
我的source.list,换成我的源,把原来的改个名,万一出错了还能改回来
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb https://cloud.r-project.org/bin/linux/ubuntu xenial-cran35/
安装R3.6以及Rstudio:
---------r3.6的安装--------
#第一步下载公钥
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 51716619E084DAB9
#更新软件源
sudo apt-get update
#安装
sudo apt install --no-install-recommends r-base
-------rstudio的安装---------
sudo apt-get install gdebi-corewget https://download2.rstudio.org/rstudio-server-1.0.136-amd64.debsudo gdebi rstudio-server-1.0.136-amd64.debrstudio-server start
这篇关于用户行为分析遇到的问题-ubantu16,hadoop3.1.3的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









